2025-09-11T10:44:29 [TARGET_APPLY ]E: RetCode: SQL_ERROR SqlState: HY000 NativeError: 3144 Message: [MySQL][ODBC 8.0(w) Driver][mysqld-8.0.42]Cannot create a JSON value from a string with CHARACTER SET 'binary'. [1022502] (ar_odbc_stmt.c:2947)
원인
Full Load시에는 실제 데이터베이스에 있는 데이터를 직접 가져오기 때문에 문제가 안되지만, Full Load 이후 CDC과정에서 위 에러가 발생하게 되는데, 이는 소스 디비의 컬럼 데이터 타입이 JSON일 때 발생하는 문제다.
CDC시에는 소스 디비의 binlog를 참고해서 가져오는데, 이때 소스 디비의 컬럼들중 데이터 타입이 JSON인 컬럼을 바이너리 형태로 읽어서 타겟 디비에 데이터를 입력할 때 문제가 발생한다.
해결법
위와 같이 문제 발생하는 테스크(소스 디비에 컬럼 데이터 타입이 JSON이 들어가 있는 테스크)를 변환 규칙으로 기존 data type이 json인걸 찾아서 이를 clob으로 데이터 유형을 변경해주면 해결된다.
블록 단위로 iSCSI, Fibre Channel, SATA, SAS 등전문 프로토콜을 통해 접근
추가 고려사항: "Raw" 스토리지를 사용할 경우 파일시스템(NTFS, XFS, ext4 등)을 얹어야 함
주요 장점: 높은 IOPS, 일관성 보장 → 데이터베이스, 트랜잭션 처리 시스템 단점: 메타데이터 부족, 직접 검색/관리 불편
File Storage
데이터를전체 파일 단위로 저장 및 액세스
디렉토리/경로 기반 구조 (예:/HR/secret/report.pdf)
제한적 메타데이터(생성일, 수정일, 크기 등만 저장)
파일 잠금(Lock)을 통해동시 수정 충돌 방지가능
일반적으로 Block Storage 위에 파일시스템 형태로 구축됨
SMB, NFS 같은파일 전용 프로토콜로 접근
주요 장점: 친숙한 구조(폴더 방식), 공유 디렉토리 활용 용이 (사내 업무 파일 서버) 단점: 대용량·비정형 데이터 검색 성능 낮음, 스케일링 제한적
Object Storage
데이터를객체(Object)단위로 저장 (실제 파일 + 메타데이터 + ID)
무제한 메타데이터사용 가능 → 강력한 검색/분류 지원
파일 Lock 불가, 대신버전 관리를 통해 규제·무결성 충족
이론적으로무제한 확장 가능(하드웨어 계속 추가)
HTTP 기반 REST API를 통해 접근 (S3, MinIO 등)
네트워크 및 디스크 속도에 주로 종속, CPU/MEM 영향 적음
주요 장점: 무제한 확장, 메타데이터 기반 검색, API 접근으로 클라우드/앱 최적화 단점: 실시간 동기 업데이트(DB 등)에는 부적합, 실시간 동기 업데이트를 지원하려면 파일 잠금 기능이 있어야 하는데, 파일잠금기능이 없음.
오브젝트 스토리지에는 파일잠금기능이 없는 이유
오브젝트 스토리지는 거대한 분산 창고에서 물건(데이터)을 통째로 넣고 빼는 방식이라,
부분적으로 물건을 잠그고 여러 사람이 동시에 쓸 수 있는 세밀한 제어(파일 잠금)를 할 수 없습니다.
그래서 "파일 잠금" 기능이 없고, 동시 수정 충돌 방지는 ‘버전 관리’로 해결하려 합니다.
구분
Block Storage
File Storage
Object Storage
저장 단위
블록 (고정 크기, ex: 16KB)
파일 단위
객체 (데이터 + 메타데이터 + ID)
메타데이터
최소 (파일명, 일부 속성)
제한적 (생성/수정일, 크기 등)
무제한 (검색·분류 가능)
접근 방식
전용 프로토콜 (iSCSI, Fibre, SAS 등)
SMB, NFS
REST API (HTTP/S3 호환)
일관성/잠금
강력한 일관성
파일 Lock 지원
파일 Lock 불가, 대신 버전 관리
확장성
제한적 (디스크 추가 필요)
제한적 (파일시스템 규모 한계)
무제한 확장 (분산 스토리지)
주요 활용
DB, 고성능 트랜잭션
사내 공유파일 서버
클라우드, 데이터 레이크, 백업, 미디어 저장
성능 제약
디스크 속도, 파일시스템 필요
프로토콜 오버헤드 (SMB/NFS)
네트워크 및 디스크 I/O 의존
오브젝트 스토리지 vs. SAN/NAS/Block Storage: 핵심 요약
1. 불변성 (Immutability)
객체는 본질적으로 변경 불가능: 한 번만 쓰고 여러 번 읽기 가능. e-디스커버리, 규정 준수(예: 보존기간 지정) 및 최신 데이터 무결성 요구에 적합.
만료 이전까지는 변경 불가, 만료 후에만 삭제 허용.
2. 보안 및 암호화
SAN/NAS는 대부분 드라이브나 볼륨 수준에서 암호화 가능.
객체 스토리지는 버킷 수준뿐 아니라, 객체마다 개별 키로 암호화 가능→ 같은 버킷 안의 서로 다른 객체를 별도의 키로 보호.
3. 클라우드 네이티브 / 접근 방식
SAN/iSCSI: 볼륨 ID와 블록 오프셋으로 접근.
NAS: NFS/SMB 마운트, 디렉토리 경로 방식.
객체 스토리지는 RESTful API와 URL/객체ID로 접근; 클라우드-네이티브 환경에서 기본 스토리지로 인정받음.
거의 모든 데이터베이스가 S3 API를 기본 지원하는 시대.
4. 메타데이터 및 검색성
SAN/NAS: 볼륨, 파일에 한정된 "표준" 메타데이터(생성일, 수정일, 용량 등)만 보유, 커스텀 메타데이터로 직접 검색 불가.
객체 스토리지는 각 객체에 자유로운 커스텀 태그, 데이터 속성 추가 가능, 태그로 빠르고 유연한 검색 지원.
5. 확장성과 성능
SAN/NAS: PB 수준의 확장에 한계, 고가 장비 중심.
객체 스토리지는 엑사스케일(EB)까지 수평 확장 가능, 하드웨어 한계는 드라이브 추가로 극복.
최신 객체 스토리지는 NVMe, 100GbE 및 하드웨어만큼 빠르며, 실제로 대규모 AI/빅데이터 워크로드에서도 SAN/NAS 대비 뛰어난 throughput 보장
6. 데이터 보호: RAID vs. Erasure Coding
RAID: 블록 단위 복제 또는 패리티, 복구시 전체 드라이브를 rebuild해야 함. 디스크 용량 커질수록 복구 시간/리스크 증가, 대규모 환경에 비효율적.
Erasure Coding (MinIO): 객체 단위로 데이터/패리티 블록을 나누어 여러 노드, 드라이브에 분산 저장. 실패 시, 객체 단위로 빠르게 복구 가능. Bitrot(사일런트 데이터 손상)까지 검출/치유 지원하여, SAN/NAS snapshotting 접근 방식보다 훨씬 효율적.
주요 비교표 (SAN/NAS/Block vs Object Storage)
항목Block/SAN/NASObject Storage (MinIO)
구조
블록/파일 기반
객체(파일+메타데이터+글로벌 ID)
확장성
수 TB ~ 수 PB 제한
EB/엑사스케일까지 수평 확장 가능
API
iSCSI/SMB/NFS 등
S3 REST API (웹 기반)
복구
RAID로 전체 드라이브
Erasure Coding으로 객체 단위 복구
메타데이터
제한적/표준세트
커스텀 태그/속성, 고급 검색 가능
불변성
제한적
객체/버킷 단위 불변 정책, 버저닝 지원
보안
볼륨/파일 암호화
버킷/객체 단위 독립 키 암호화
성능
HW/구조적 한계
하드웨어 및 네트워크 한계까지 최대 활용
활용
DB, 파일서버
AI/ML, 빅데이터, 분석, DB, 미디어, 백업
가격
$$$ (고가, 복잡)
$ (소프트웨어 정의, commodity HW 활용)
MinIO란?
MinIO는 고성능, 확장 가능하며 AWS S3 API와 완벽하게 호환되는 분산 객체 스토리지 솔루션입니다. 온프레미스, 프라이빗 클라우드, 퍼블릭 클라우드, 그리고 하이브리드 환경에 모두 배포 가능하며, 대규모 데이터 저장, 백업, AI/ML, 빅데이터 분석 등 클라우드 네이티브 워크로드에 최적화되어 있습니다.
MinIO는 Erasure Coding을 통한 데이터 보호와 Bitrot 방지 기능으로 높은 내구성과 가용성을 제공하며, Kubernetes와의 네이티브 통합으로 현대 인프라 환경에 쉽게 적용할 수 있습니다. 또한, CLI와 웹 UI를 제공해 운영 편의성을 높였고, TLS 암호화 및 IAM 역할 기반 권한 관리 등 강력한 보안 기능도 포함합니다.
즉, MinIO는 빠르고 안정적인 대용량 객체 데이터 저장을 위한 오픈소스 기반의 기업급 스토리지 솔루션입니다
MinIO 배포 방식
MinIO는 세 가지 토폴로지로 배포됩니다: 단일 노드 단일 드라이브(SNSD), 단일 노드 다중 드라이브(SNMD), 다중 노드 다중 드라이브(MNMD)
SNSD는 개발 및 평가용으로 제한된 신뢰성을 가지며, SNMD는 저성능・저용량 워크로드에 적합합니다
MNMD는 분산 클러스터 환경으로, 다중 노드와 드라이브에서 최대 절반 장애까지 견디는 고가용성・고성능을 제공합니다
MNMD는 AI/ML, 분산 쿼리, 데이터 분석, 데이터 레이크 등 페타바이트급 대규모 워크로드를 지원합니다
배포는 가상머신, 베어메탈, 쿠버네티스 등 다양한 인프라 환경에서 가능하며, 클러스터 노드들이 하나의 객체 저장소로 함께 작동합니다
MinIO 서버 관리 방식
프로덕션 환경에서는 고가용성 확보를 위해 여러 노드와 스토리지 장치를 서버 풀(Server Pool)로 묶어 자원을 풀링합니다.
하나 이상의 서버 풀이 모여 단일 MinIO 클러스터를 구성하며, 각 객체는 동일한 서버 풀 내 동일한 삭제 세트(Erasure Set)에 데이터를 씁니다.
서버 풀이 하나라도 다운되면 클러스터 전체 I/O가 중단되고, 복구 후 정상 작동 시 다시 I/O가 재개됩니다.
실제 시작 명령어에서 노드와 드라이브 수를 지정하며, 예를 들어 4노드에 노드당 4드라이브로 총 16드라이브 서버 풀 생성이 가능합니다.
복수 서버 풀로 구성 시, 각 서버 풀은 최소 4개 이상의 노드로 구성하는 것이 권장됩니다.
클러스터 전체는 해당 여러 서버 풀이 연결된 형태이며, 사용자는 CLI(mcli)나 웹 콘솔을 통해 클러스터 및 객체 상태를 관리할 수 있습니다.
MinIO의 가용성, 중복성, 안정성 제공 방법
Erasure Coding을 사용해 데이터를 데이터/패리티 블록으로 나누어 저장, 일부 드라이브 실패에도 데이터 복구가 가능합니다.
Bit rot(무형의 데이터 손상)을 해시 검증 및 자동 복구 기능으로 방어합니다.
Quorum 메커니즘으로 읽기·쓰기 가능한 최소 노드 수를 보장합니다.
서버 풀 단위로 클러스터를 구성하며, 각 객체는 동일 서버 풀 내 삭제 세트에 저장됩니다.
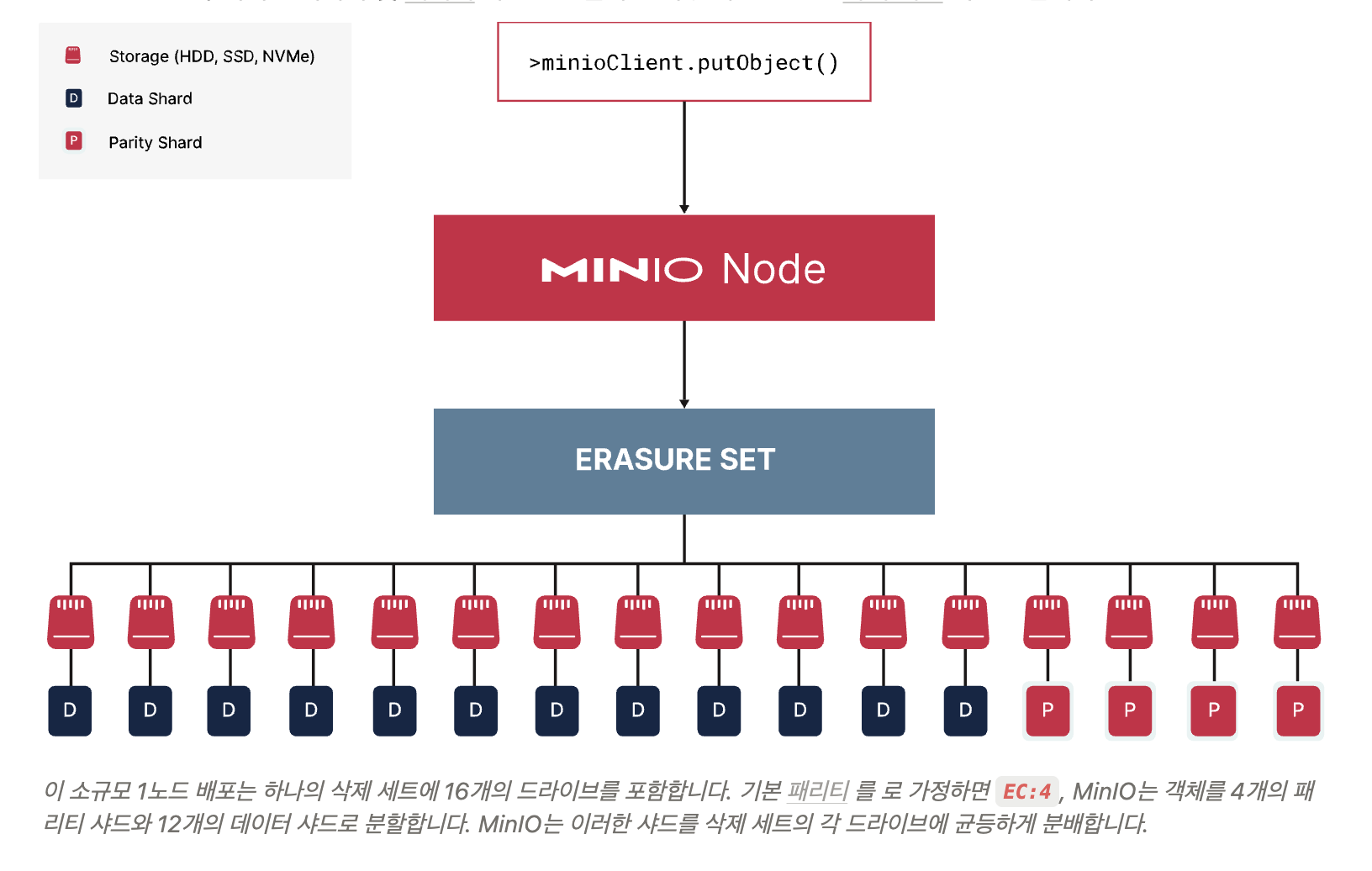
MinIO가 고가용성과 안정성을 위해 데이터를 여러 조각과 패리티로 나누어 여러 디스크에 분산하는 방식
MinIO는 객체를 데이터 샤드(Data Shard)와 패리티 샤드(Parity Shard)로 나누어 저장합니다.
데이터 샤드는 실제 데이터를, 패리티 샤드는 데이터 복구용 중복 정보를 포함합니다.
파란색 D는 데이터 샤드, 빨간색 P는 패리티 샤드를 의미하며, 총 16개의 드라이브에 12개의 데이터 샤드와 4개의 패리티 샤드가 분포되어 있습니다.
패리티 샤드는 데이터의 일부 장애나 손실 시 데이터를 복구할 수 있도록 하는 중복 정보 역할을 합니다 (삭제 코딩 EC:4).
1노드 내의 이런 삭제 세트 구성을 통해 MinIO는 드라이브 장애에도 데이터 가용성과 복원력을 제공합니다.
MinIO는 이 샤드들을 각 드라이브에 균등하게 분포시켜 장애 시 복구 및 가용성을 보장합니다.
사용자는 minioClient.putObject() API를 통해 데이터를 MinIO 노드에 저장하고, 노드는 내부적으로 이 구조를 통해 데이터를 분산 저장합니다.
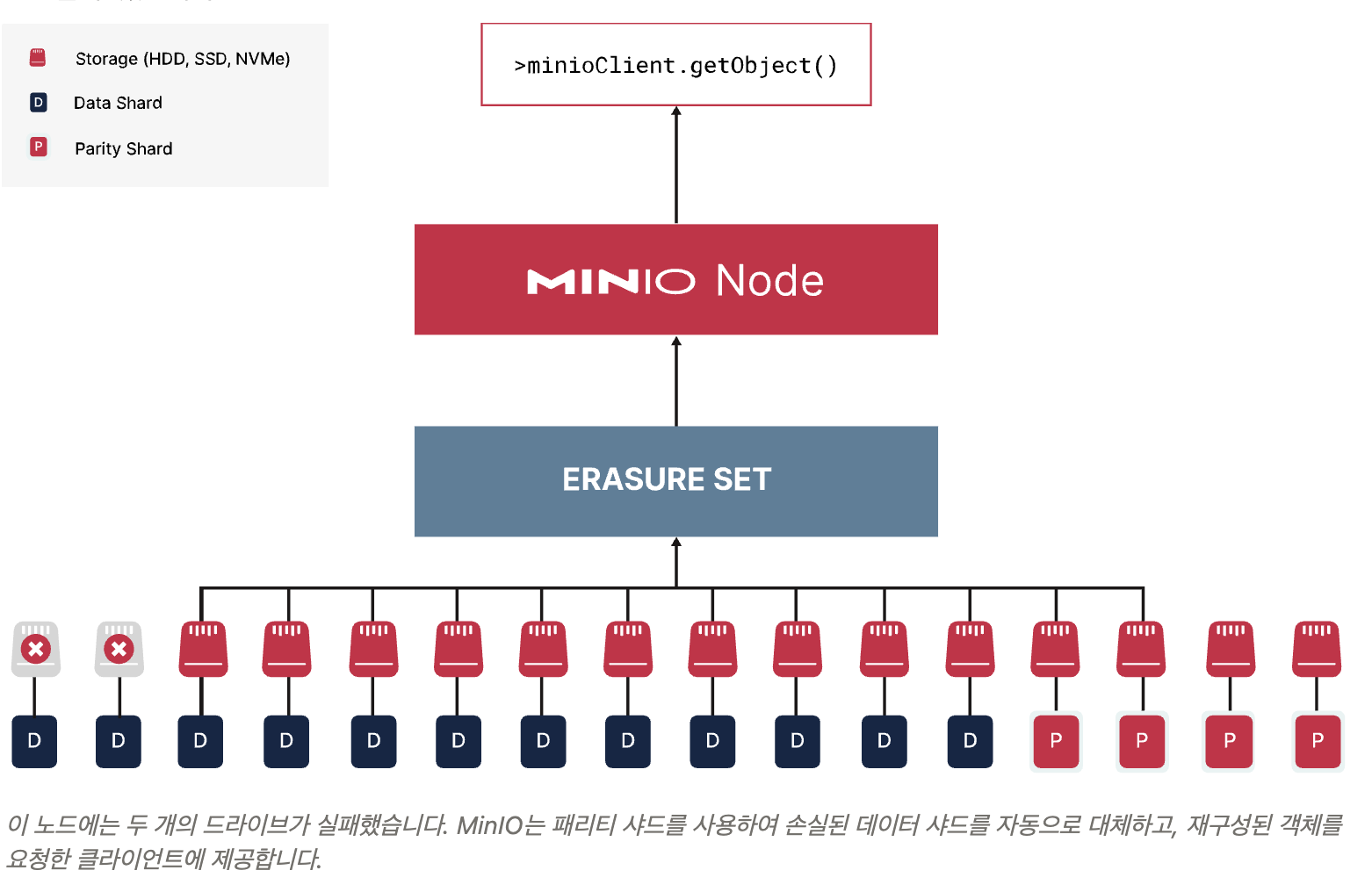
패리티 4개가 있는데, 2개 장애니까 정상동작
삭제 코딩(Erasure Coding) 개념
Erasure Coding은 데이터를 여러 조각(Data Shard)과 보호용 조각(Parity Shard)으로 나누어 저장하는 기술입니다.
'Erasure'는 ‘지움’ 또는 ‘손실’을 의미하며, 일부 데이터 조각이 손실되어도 원래 데이터를 복구할 수 있도록 코딩하는 과정입니다.
MinIO는 모든 객체를 데이터와 패리티 샤드로 분할하고, 이를 삭제 세트(Erasure Set)라는 그룹의 여러 드라이브에 균등하게 분배합니다.
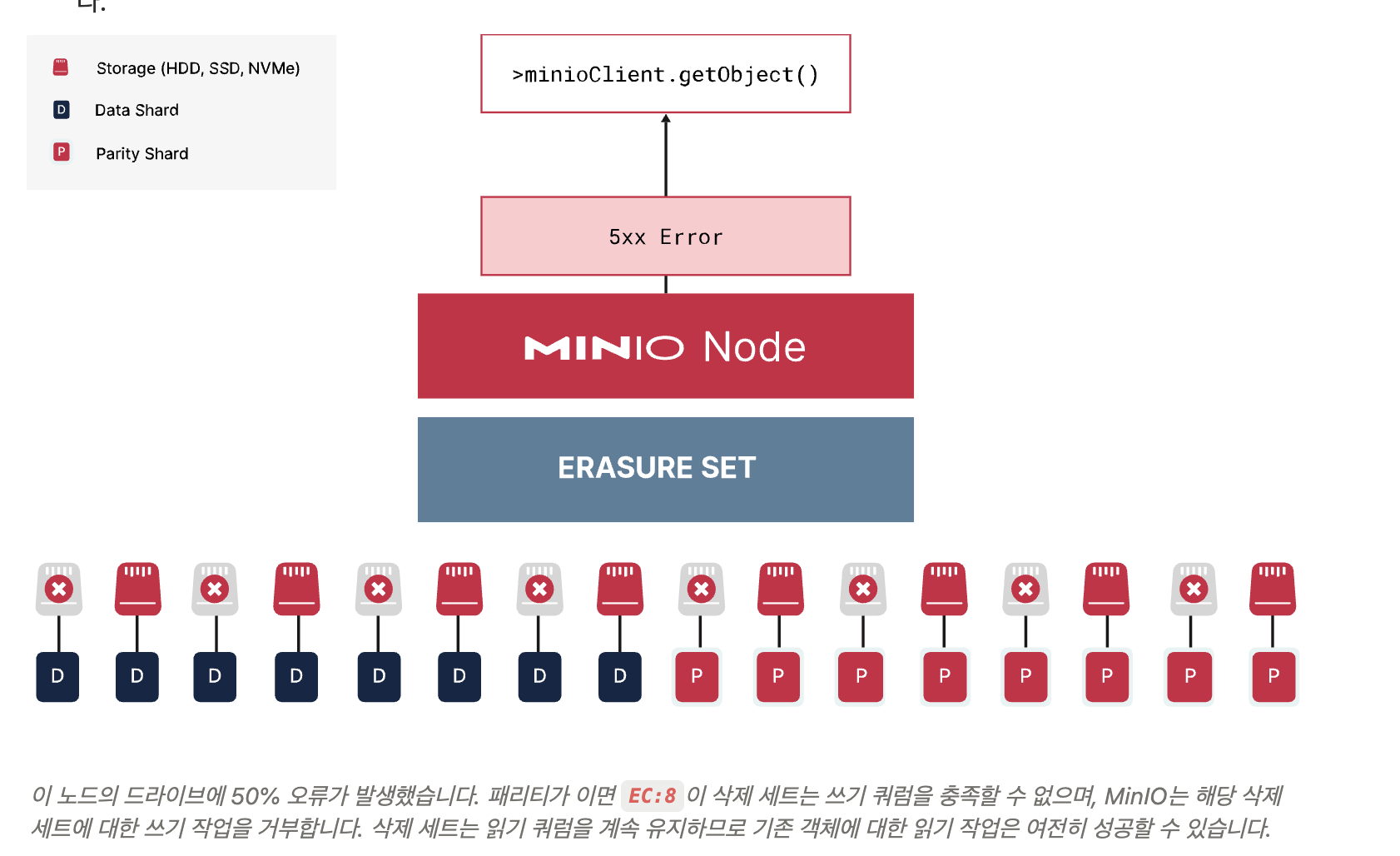
예를 들어, 16 드라이브 삭제 세트에서 기본 패리티는 4개입니다(EC:4). 이는 최대 4개의 드라이브 장애에도 데이터를 복구할 수 있다는 뜻입니다.
패리티 수는 가용성과 저장 효율 간 트레이드오프가 있습니다. 패리티가 많으면 장애 허용량이 커지지만 저장 공간 효율은 감소합니다.
Bitrot 보호
Bitrot은 저장장치에 저장된 데이터가 시간이 지나면서 내부적으로 무형식 손상되는 현상입니다.
MinIO는 고속 해시 알고리즘(HighwayHash)을 이용해 데이터를 읽을 때마다 무결성 검사를 수행하고, 데이터 손상이 감지되면 Erasure Coding으로 자동 복구합니다.
이런 자동 검증과 복구 덕분에 사용자나 시스템이 알지 못하는 데이터 손상도 사전에 방지됩니다.
MinIO 배포(도커 컨테이너)
#
mkdir /tmp/data
tree -h /tmp/data
#
docker ps -a
docker run -itd -p 9000:9000 -p 9090:9090 --name minio -v /tmp/data:/data \
-e "MINIO_ROOT_USER=admin" -e "MINIO_ROOT_PASSWORD=minio123" \
quay.io/minio/minio server /data --console-address ":9090"
docker ps
#
docker exec -it minio env
docker inspect minio | jq
...
"Env": [
"MINIO_ROOT_USER=admin",
"MINIO_ROOT_PASSWORD=miniopasswd",
"PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin",
"MINIO_ACCESS_KEY_FILE=access_key",
"MINIO_SECRET_KEY_FILE=secret_key",
"MINIO_ROOT_USER_FILE=access_key",
"MINIO_ROOT_PASSWORD_FILE=secret_key",
"MINIO_KMS_SECRET_KEY_FILE=kms_master_key",
"MINIO_UPDATE_MINISIGN_PUBKEY=RWTx5Zr1tiHQLwG9keckT0c45M3AGeHD6IvimQHpyRywVWGbP1aVSGav",
"MINIO_CONFIG_ENV_FILE=config.env",
"MC_CONFIG_DIR=/tmp/.mc"
],
...
#
docker logs minio
INFO: Formatting 1st pool, 1 set(s), 1 drives per set.
INFO: WARNING: Host local has more than 0 drives of set. A host failure will result in data becoming unavailable.
MinIO Object Storage Server
Copyright: 2015-2025 MinIO, Inc.
License: GNU AGPLv3 - https://www.gnu.org/licenses/agpl-3.0.html
Version: RELEASE.2025-07-23T15-54-02Z (go1.24.5 linux/arm64)
API: http://172.17.0.2:9000 http://127.0.0.1:9000
RootUser: admin
RootPass: miniopasswd
WebUI: http://172.17.0.2:9090 http://127.0.0.1:9090
RootUser: admin
RootPass: miniopasswd
CLI: https://min.io/docs/minio/linux/reference/minio-mc.html#quickstart
$ mc alias set 'myminio' 'http://172.17.0.2:9000' 'admin' 'miniopasswd'
Docs: https://docs.min.io
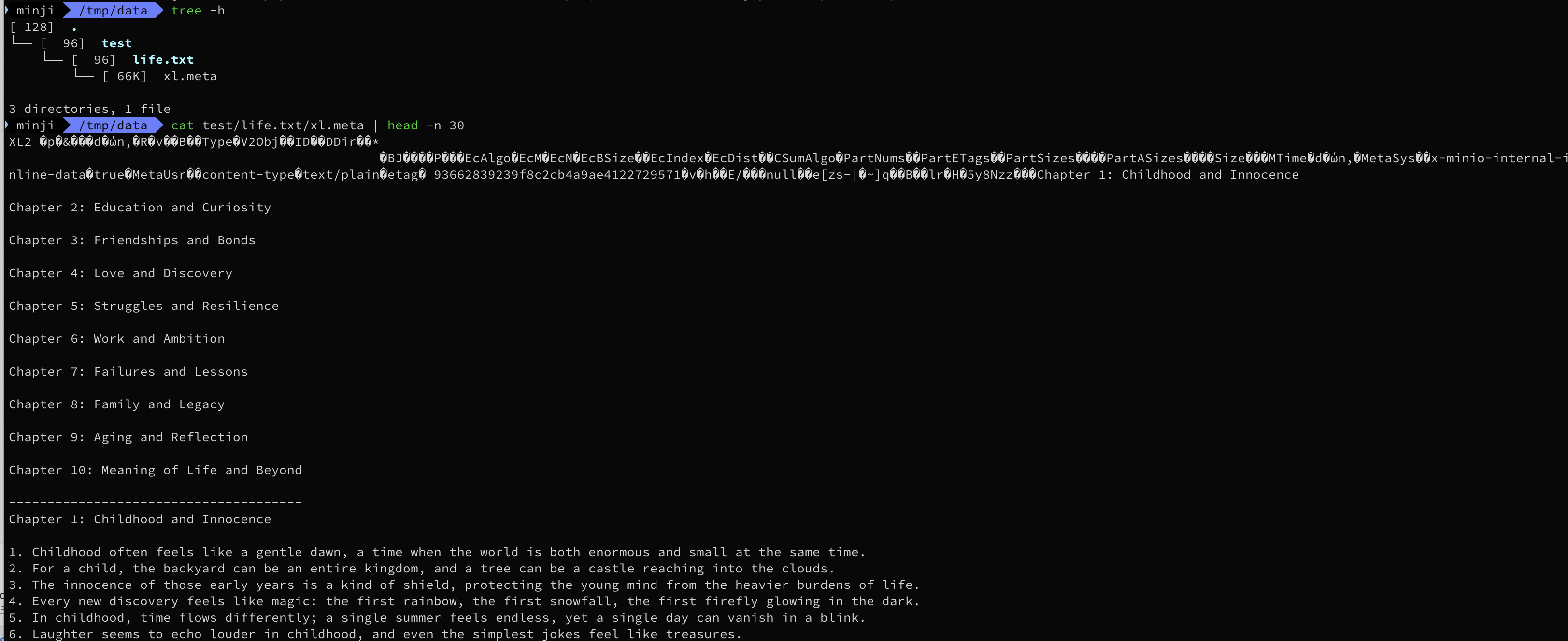
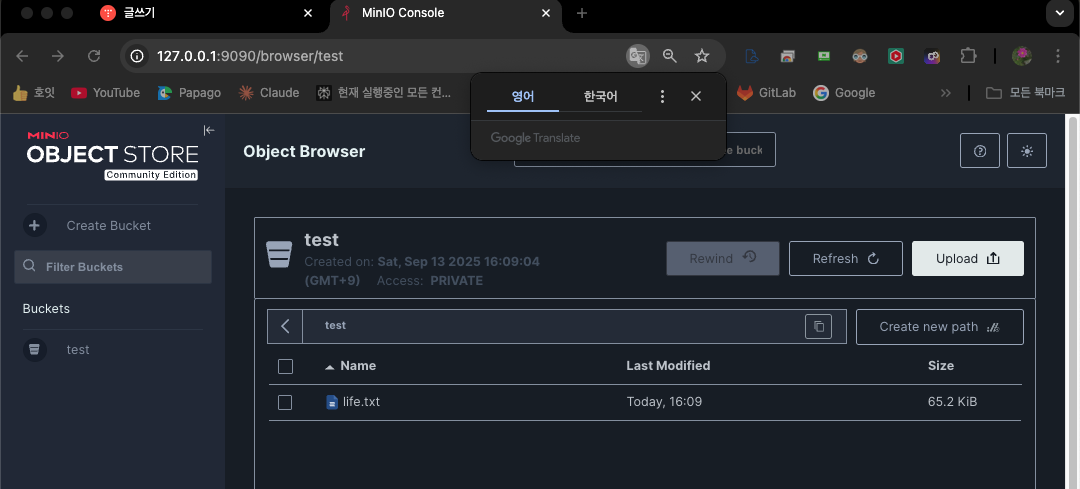
MinIO 웹으로 접속해서 test 버킷 만들고 life.txt(1000줄짜리 소설) 업로드
life.txt라는 디렉토리가 생성되고 하위에 xl.meta 파일이 생성된것이 확인된다.
MinIO MC(MinIO Client) 설치
# https://docs.min.io/enterprise/aistor-object-store/reference/cli/ 각자 실습 환경 OS에 맞는 mc 설치 할 것!
brew install minio/stable/mc
mc --help
# mc alias
mc alias list
mc alias set 'myminio' 'http://127.0.0.1:9000' 'admin' 'minio123'
Added `myminio` successfully.
mc alias list
myminio
URL : http://127.0.0.1:9000
AccessKey : admin
SecretKey : miniopasswd
API : s3v4
Path : auto
Src : /Users/gasida/.mc/config.json
cat ~/.mc/config.json
# admin info
mc admin info play
mc admin info myminio
● 127.0.0.1:9000
Uptime: 1 hour
Version: 2025-07-23T15:54:02Z
Network: 1/1 OK
Drives: 1/1 OK
Pool: 1
┌──────┬────────────────────────┬─────────────────────┬──────────────┐
│ Pool │ Drives Usage │ Erasure stripe size │ Erasure sets │
│ 1st │ 44.0% (total: 460 GiB) │ 1 │ 1 │
└──────┴────────────────────────┴─────────────────────┴──────────────┘
27 KiB Used, 1 Bucket, 1 Object
1 drive online, 0 drives offline, EC:0
# ls : lists buckets and objects on MinIO or another S3-compatible service
mc ls
mc ls myminio/test
[2025-09-07 12:21:09 KST] 27KiB STANDARD life.txt
# tree
mc tree --files myminio/test
myminio/test
└─ life.txt
# find
mc find myminio/test --name "*.txt"
myminio/test/life.txt
# stat
mc stat myminio/test
Name : test
Date : 2025-09-07 12:48:49 KST
Size : N/A
Type : folder
Properties:
Versioning: Un-versioned
Location: us-east-1
Anonymous: Disabled
ILM: Disabled
Usage:
Total size: 27 KiB
Objects count: 1
Versions count: 0
Object sizes histogram:
1 object(s) BETWEEN_1024B_AND_1_MB
1 object(s) BETWEEN_1024_B_AND_64_KB
0 object(s) BETWEEN_10_MB_AND_64_MB
0 object(s) BETWEEN_128_MB_AND_512_MB
0 object(s) BETWEEN_1_MB_AND_10_MB
0 object(s) BETWEEN_256_KB_AND_512_KB
0 object(s) BETWEEN_512_KB_AND_1_MB
0 object(s) BETWEEN_64_KB_AND_256_KB
0 object(s) BETWEEN_64_MB_AND_128_MB
0 object(s) GREATER_THAN_512_MB
0 object(s) LESS_THAN_1024_B
mc stat myminio/test/life.txt
Name : life.txt
Date : 2025-09-07 12:21:09 KST
Size : 27 KiB
ETag : f7593a23177b30a86197e83197d99acd
Type : file
Metadata :
Content-Type: text/plain
# 그외 mb/rb, mv, cp, rm, mirror 등은 직접 해볼 것!
MinIO Policy
# IAM 기본 정책 및 커스텀 정책 확인
mc admin policy list myminio
consoleAdmin
diagnostics
readonly
readwrite
writeonly
# IAM 정책 세부 (대상 지정)
mc admin policy info myminio consoleAdmin | jq
{
"PolicyName": "consoleAdmin",
"Policy": {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"admin:*"
]
},
{
"Effect": "Allow",
"Action": [
"kms:*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:*"
],
"Resource": [
"arn:aws:s3:::*"
]
}
]
}
}
# 버킷 외부 공개 정책 확인(private)
mc anonymous get myminio/test
Access permission for `myminio/test` is `private`
# 객체 접근 (외부 사용자)
curl http://127.0.0.1:9000/test/life.txt
<?xml version="1.0" encoding="UTF-8"?>
<Error><Code>AccessDenied</Code><Message>Access Denied.</Message><Key>life.txt</Key><BucketName>test</BucketName><Resource>/test/life.txt</Resource><RequestId>1862E3D962D137B2</RequestId><HostId>dd9025bab4ad464b049177c95eb6ebf374d3b3fd1af9251148b658df7ac2e3e8</HostId></Error>
# 버킷 외부 공개 정책 수정(public) : GET, PUT, LIST
mc anonymous set public myminio/test
mc anonymous get myminio/test
Access permission for `myminio/test` is `public`
# 객체 접근 (외부 사용자)
curl http://127.0.0.1:9000/test/life.txt
...
# 버킷 외부 공개 정책 원복(private)
mc anonymous set private myminio/test
mc anonymous get myminio/test
# 4개의 로컬 디렉토리를 생성하여 각각을 MinIO 컨테이너의 별도의 디스크 볼륨으로 마운트 준비
mkdir -p /tmp/disk1 /tmp/disk2 /tmp/disk3 /tmp/disk4
# 생성된 디렉토리 구조 확인 (tree 명령어가 있으면 디렉토리 크기 정보 포함 출력)
tree -h /tmp
# 실행 중인 모든 도커 컨테이너 리스트 확인
docker ps -a
# MinIO 컨테이너 실행 (백그라운드, 9000포트 - S3 API, 9090포트 - 콘솔 UI 포트)
# 4개의 로컬 경로를 컨테이너 내부 /data1, /data2, /data3, /data4로 각각 마운트
# 환경변수 설정: 루트 계정(admin), 비밀번호(minio123), Erasure Coding 패리티 1 (EC:1) 기본 저장소 클래스
# 서버 시작 명령어 : /data{1...4} 경로를 데이터 저장소로 지정하고, 콘솔 UI는 9090 포트 오픈
docker run -itd -p 9000:9000 -p 9090:9090 --name minio \
-v /tmp/disk1:/data1 \
-v /tmp/disk2:/data2 \
-v /tmp/disk3:/data3 \
-v /tmp/disk4:/data4 \
-e "MINIO_ROOT_USER=admin" -e "MINIO_ROOT_PASSWORD=minio123" -e "MINIO_STORAGE_CLASS_STANDARD=EC:1" \
quay.io/minio/minio server /data{1...4} --console-address ":9090"
# 현재 실행 중인 컨테이너 상태 출력 (정상 실행 여부 확인)
docker ps
# 컨테이너 내 환경변수 확인 (MINIO_ROOT_USER, MINIO_ROOT_PASSWORD, 스토리지 클래스 등 환경 정보)
docker exec -it minio env
# 컨테이너 상세 정보 조회 후 jq로 JSON 포맷팅 출력 (볼륨 마운트 정보, 네트워크, 포트 등)
docker inspect minio | jq
# MinIO 컨테이너 로그 확인 (삭제 코딩 적용된 1개의 풀, 4드라이브 구성, 드라이브가 동일 호스트에 위치한다는 경고 포함)
docker logs minio
INFO: Formatting 1st pool, 1 set(s), 4 drives per set.
INFO: WARNING: Host local has more than 1 drives of set. A host failure will result in data becoming unavailable.
...
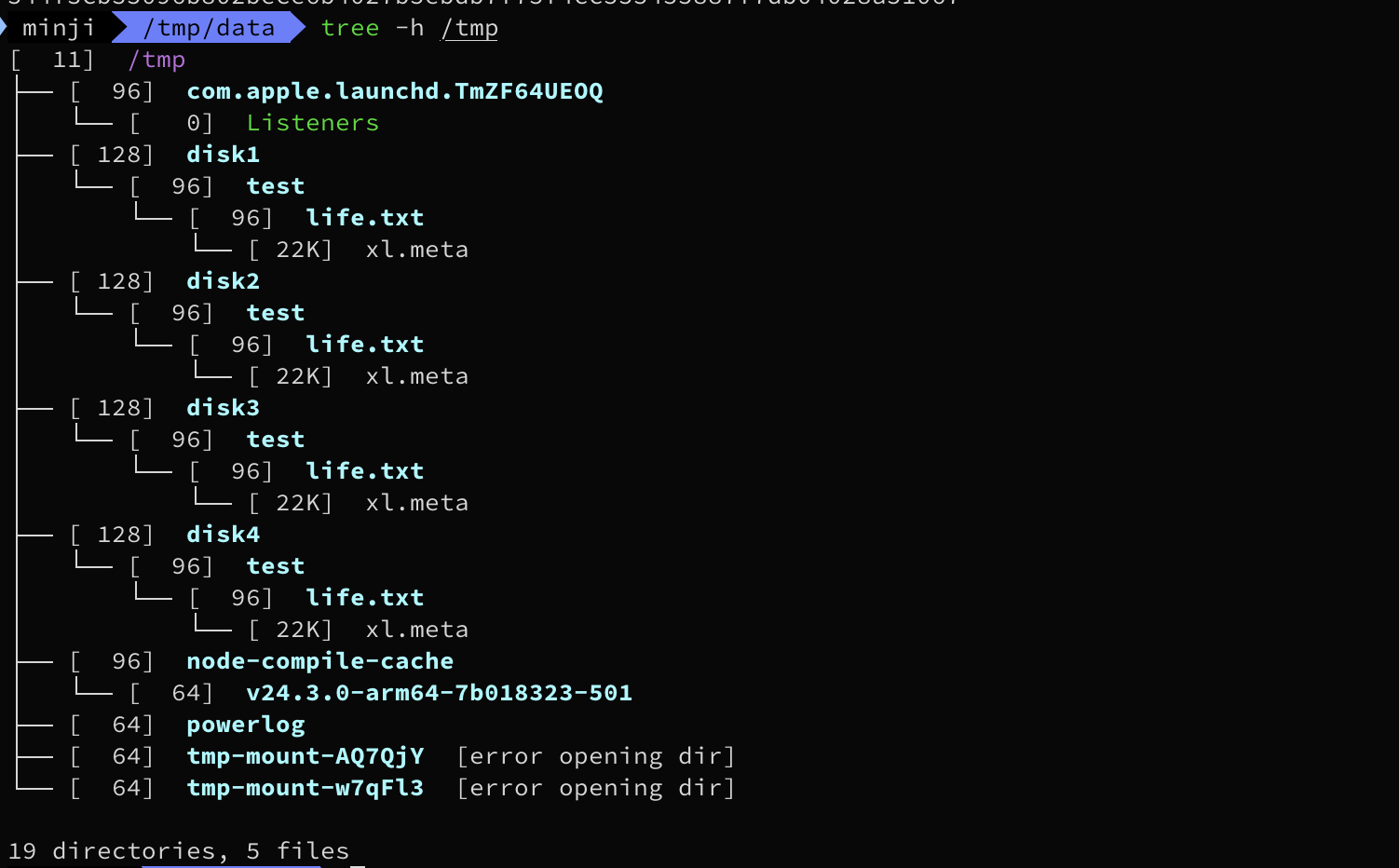
life.txt 파일 업로드
멀티디스크로 배포했기에 erasure coding이 동작하게된다.
위와같이 파일이 쪼개져서 들어간것을 볼 수 있고, 패리티는 3번 디스크에 반영된것을 알 수 있다.
#
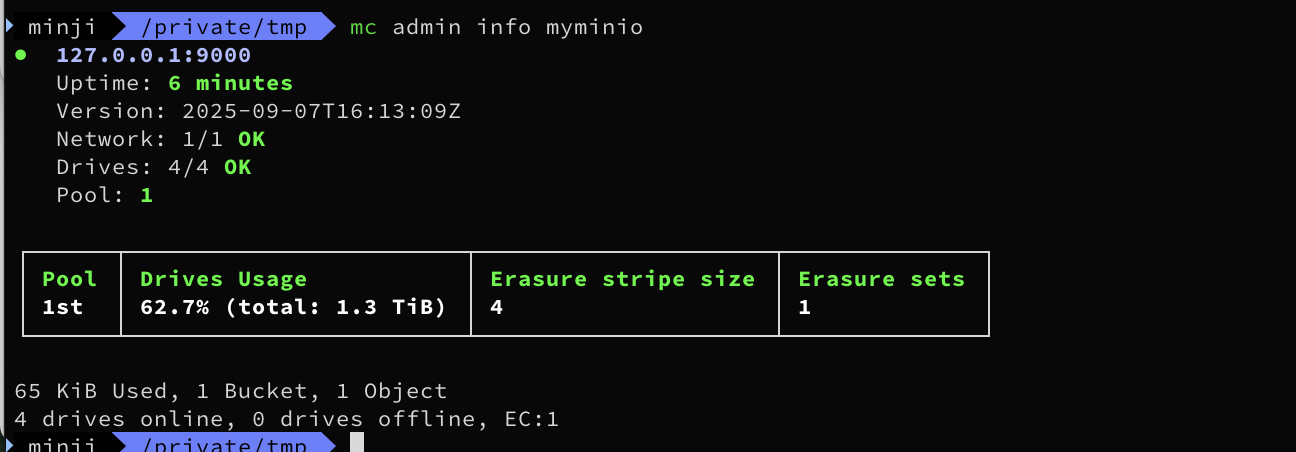
mc admin info myminio
● 127.0.0.1:9000
Uptime: 3 minutes
Version: 2025-07-23T15:54:02Z
Network: 1/1 OK
Drives: 4/4 OK
Pool: 1
┌──────┬────────────────────────┬─────────────────────┬──────────────┐
│ Pool │ Drives Usage │ Erasure stripe size │ Erasure sets │
│ 1st │ 44.0% (total: 1.3 TiB) │ 4 │ 1 │
└──────┴────────────────────────┴─────────────────────┴──────────────┘
65 KiB Used, 1 Bucket, 1 Object
mc stat myminio/test
mc stat myminio/test/life.txt
# 강제로 (패리티 아닌)디렉터리 1개 제거
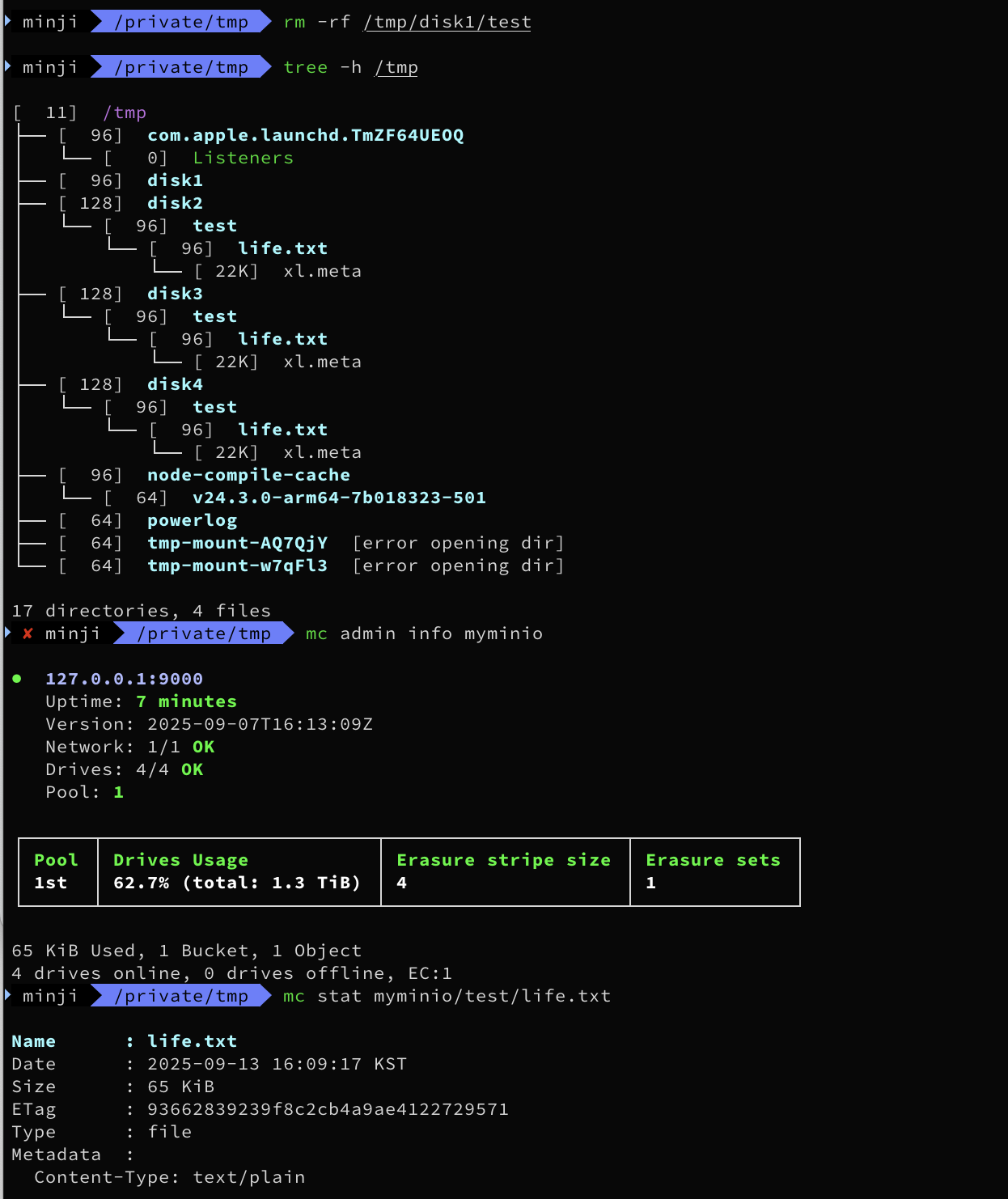
rm -rf /tmp/disk1/test
tree -h /tmp
#
mc admin info myminio
mc stat myminio/test/life.txt
# 버킷 힐
mc admin heal myminio/test
# 약간의 시간 걸림
mc stat myminio/test/life.txt
tree -h /tmp
cat /tmp/disk1/test/life.txt/xl.meta
위 코드로 유실 재현 및 복구를 확인해보자.
위와같이 삭제된 상태에서,
heal 해서 다시 데이터가 살아난것을 볼 수 있다.
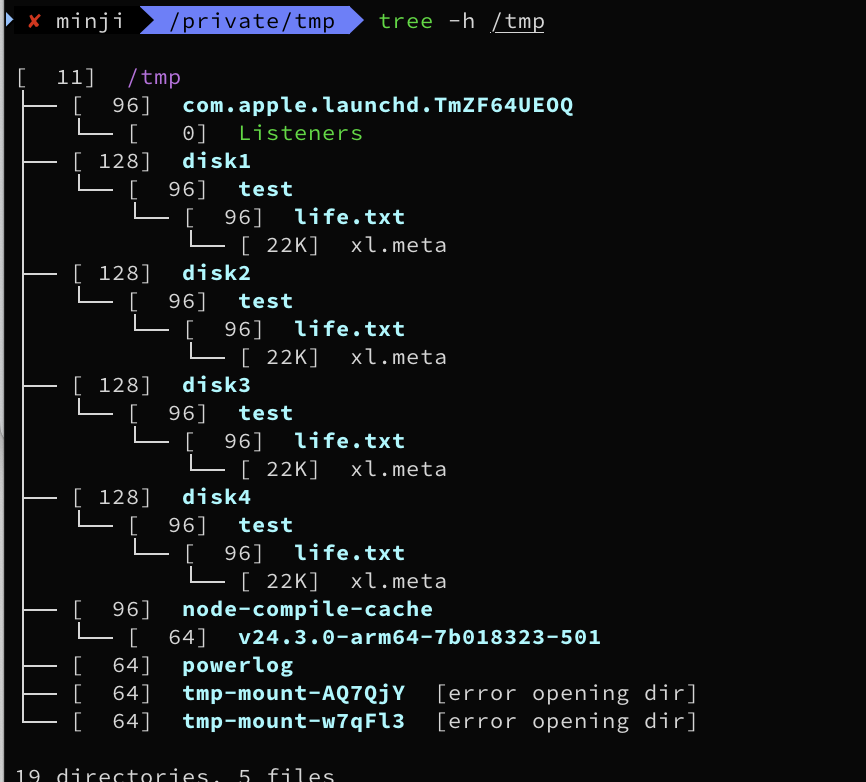
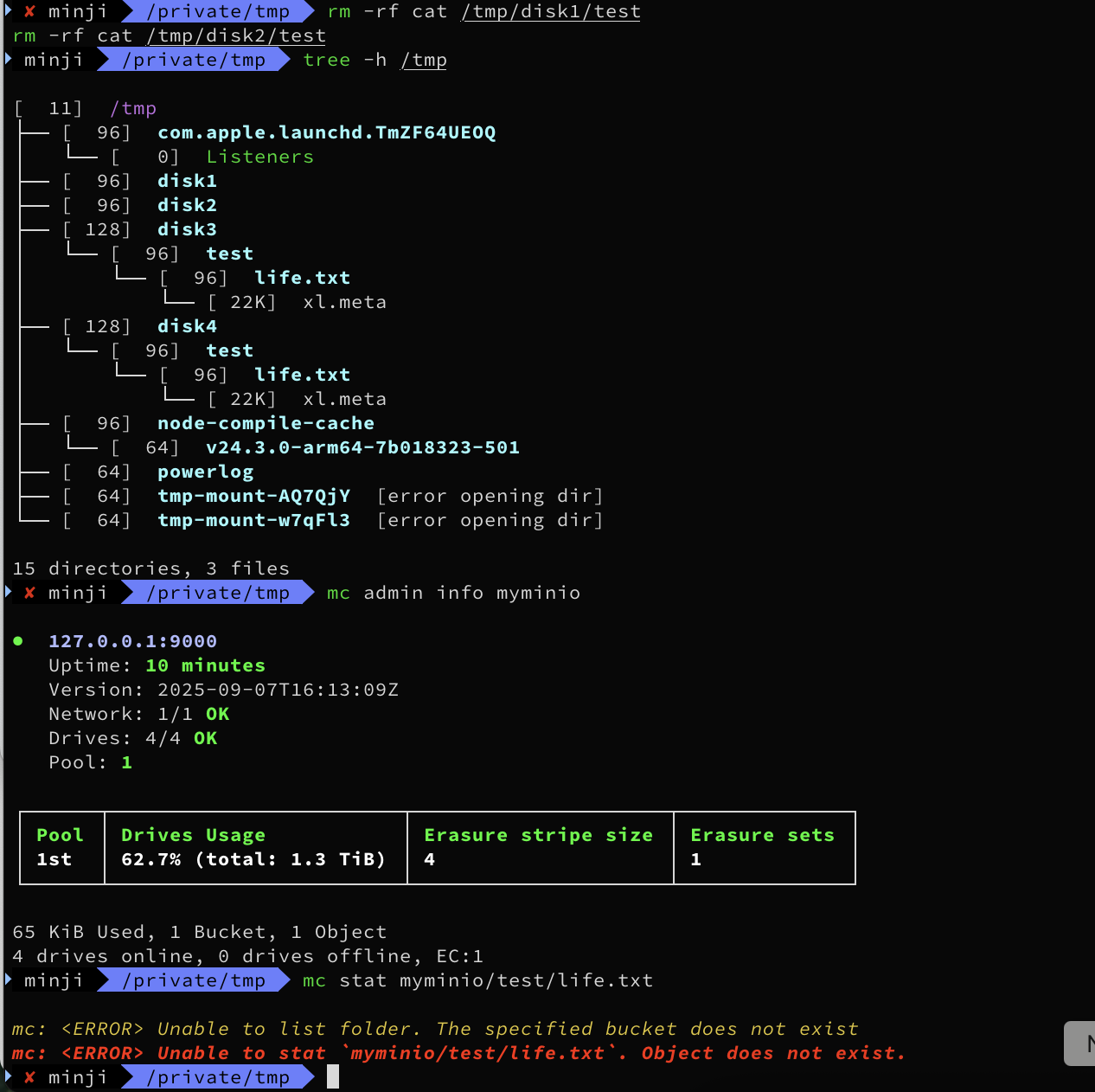
이번엔 2개를 날려보자(현재 패리티는 1개인 상황)
# 강제로 디렉터리 2개 제거
rm -rf cat /tmp/disk1/test
rm -rf cat /tmp/disk2/test
tree -h /tmp
#
mc admin info myminio
mc stat myminio/test/life.txt
# 버킷 힐 시도
mc admin heal myminio/test
tree -h /tmp
...
STS(Security Token Service) 환경변수(OPERATOR_STS_ENABLED=on) 설정 시
클러스터 상태 확인용 인증서 관리 등
# Add the MinIO Operator Repo to Helm
helm repo add minio-operator https://operator.min.io
helm repo update
helm search repo minio-operator
NAME CHART VERSION APP VERSION DESCRIPTION
minio-operator/minio-operator 4.3.7 v4.3.7 A Helm chart for MinIO Operator
minio-operator/operator 7.1.1 v7.1.1 A Helm chart for MinIO Operator
minio-operator/tenant 7.1.1 v7.1.1 A Helm chart for MinIO Operator
# Install the Operator : Run the helm install command to install the Operator.
# The following command specifies and creates a dedicated namespace minio-operator for installation.
# MinIO strongly recommends using a dedicated namespace for the Operator.
helm install \
--namespace minio-operator \
--create-namespace \
--set operator.replicaCount=1 \
operator minio-operator/operator
# 확인
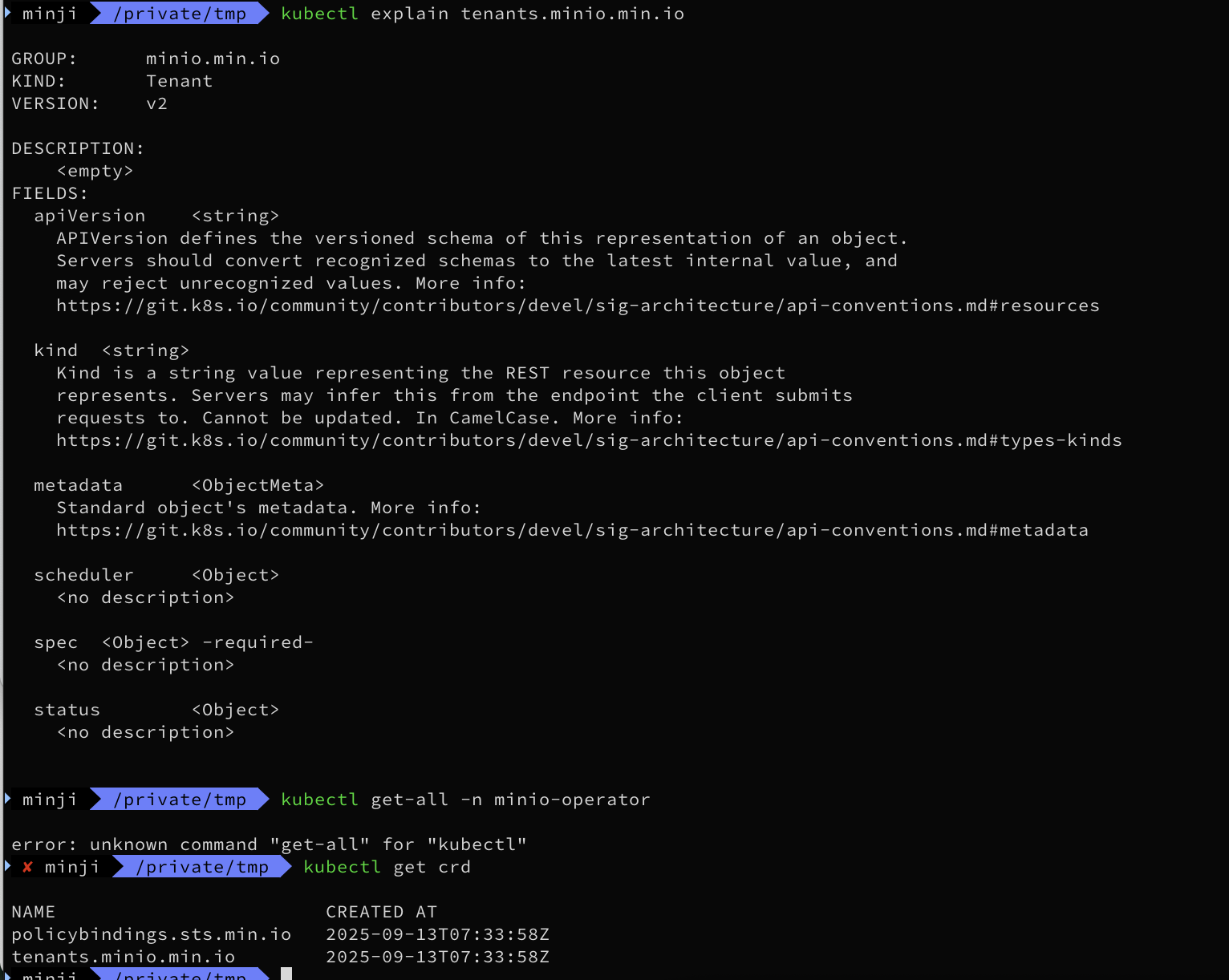
kubectl get all -n minio-operator
kubectl get-all -n minio-operator
kubectl get crd
NAME CREATED AT
policybindings.sts.min.io 2025-09-07T08:36:29Z
tenants.minio.min.io 2025-09-07T08:36:29Z
#
kubectl explain tenants.minio.min.io
kubectl explain tenants.minio.min.io.spec
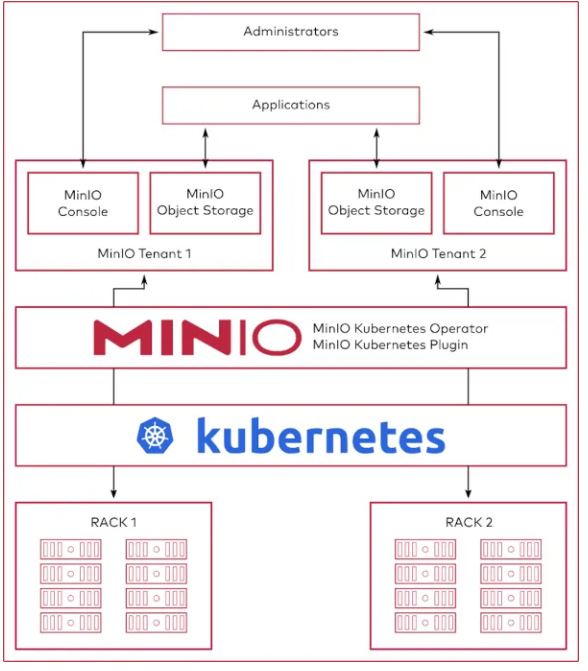
MinIO 테넌트 구성요소
MinIO 테넌트는 MinIO 오브젝트 스토리지 서비스를 지원하는 쿠버네티스 리소스를 특정 네임스페이스에 완전하게 배포한 세트입니다.
MinIO는 로컬에 직접 연결된 스토리지가 있는 쿠버네티스 워커 노드에 테넌트를 배포하는 것을 강력히 권장합니다. 워커 노드는 MinIO의 프로덕션용 하드웨어 체크리스트를 충족해야 합니다.
영구 볼륨(Persistent Volume)은 주로 ReadWriteOnce 액세스 모드를 지원하는 볼륨을 사용하며, MinIO의 일관성 보장을 위해 독점적 접근이 필요합니다. 영구 볼륨 클레임(PVC)에 대해 Retain 회수 정책 설정을 권고하며, 볼륨 포맷은 XFS가 성능상 최적입니다.
노드에 직접 연결된 스토리지가 있는 클러스터에서는 DirectPV CSI 드라이버 사용을 추천합니다. 이는 로컬 볼륨 수동 관리를 자동화합니다.
MinIO 테넌트는 반드시 자체 네임스페이스를 가져야 하고, 오퍼레이터가 이 네임스페이스 내에서 테넌트 운영에 필요한 파드(Pod)를 생성합니다.
각 테넌트 파드는 3개의 컨테이너를 실행합니다:
MinIO 컨테이너: 객체 저장 및 검색 기능 수행 (베어메탈 MinIO와 동일 기능)
InitContainer: 파드 시작 시 설정 비밀 관리, 시작 후 종료됨
SideCar 컨테이너: 구성 비밀과 루트 자격 증명을 지속 감시하며 변경 시 업데이트, 루트 자격 증명 미발견 시 오류 발생
MinIO Operator 버전 5.0.6부터는 추가 Pod 초기화를 위한 사용자 정의 init 컨테이너도 지원합니다.
테넌트는 영구 볼륨 클레임을 사용해 데이터를 저장하는 영구 볼륨과 통신합니다.
MinIO 배포 및 노드포트 설정
#
curl -sLo values.yaml https://raw.githubusercontent.com/minio/operator/master/helm/tenant/values.yaml
# VSCODE 수정 : 기본키(minio , minio123)
tenant:
pools:
- servers: 4
name: pool-0
volumesPerServer: 1 # The number of volumes attached per MinIO Tenant Pod / Server.
size: 1Gi # The capacity per volume requested per MinIO Tenant Pod.
env:
- name: MINIO_STORAGE_CLASS_STANDARD
value: "EC:1"
#
helm install \
--namespace tenant-0 \
--create-namespace \
--values values.yaml \
tenant-0 minio-operator/tenant
# 확인
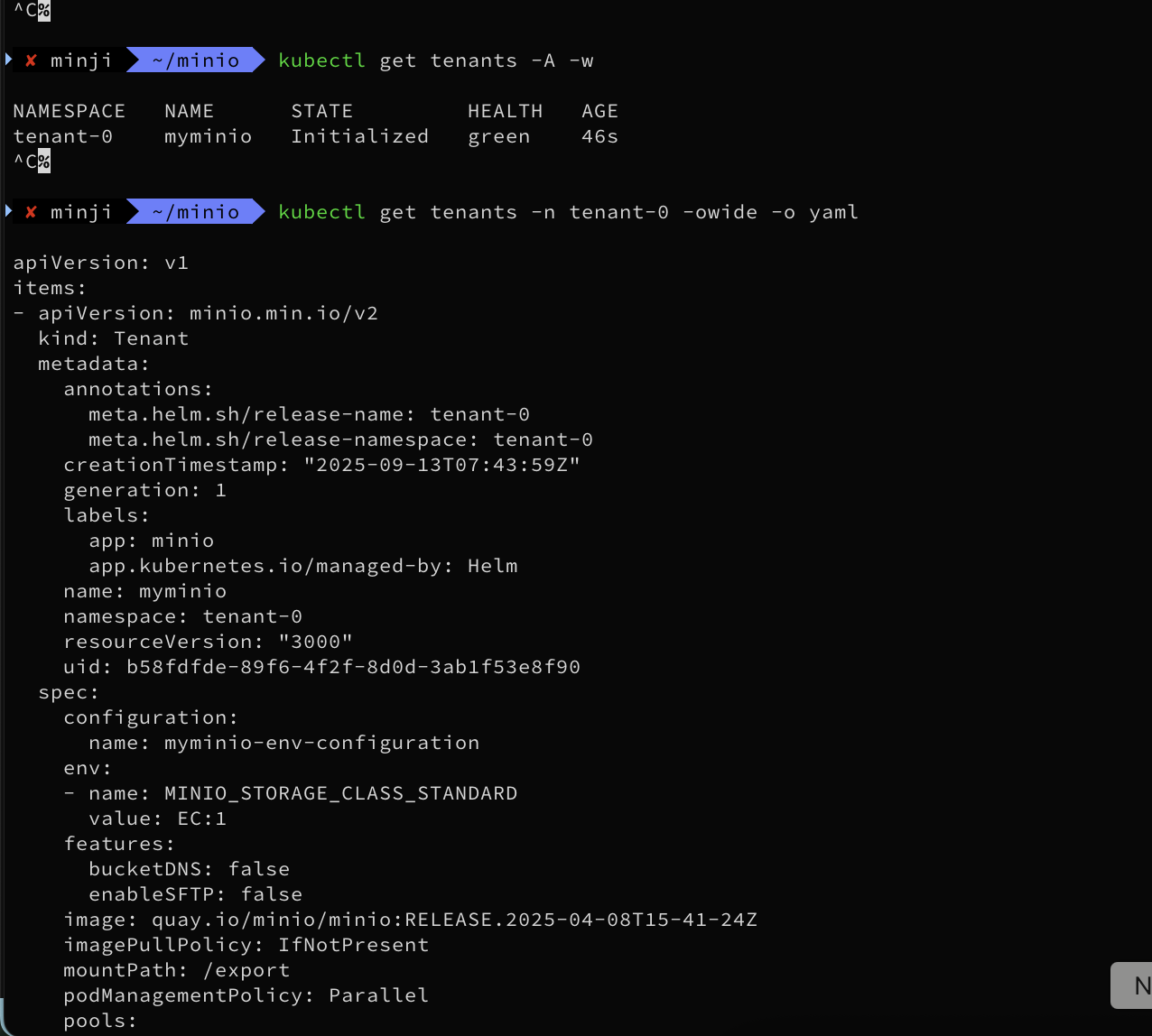
kubectl get tenants -A -w
NAMESPACE NAME STATE HEALTH AGE
tenant-0 myminio Waiting for MinIO TLS Certificate 24s
tenant-0 myminio Provisioning MinIO Cluster IP Service 28s
tenant-0 myminio Provisioning Console Service 28s
tenant-0 myminio Provisioning MinIO Headless Service 28s
tenant-0 myminio Provisioning MinIO Statefulset 29s
tenant-0 myminio Waiting for Tenant to be healthy 30s
tenant-0 myminio Waiting for Tenant to be healthy red 53s
tenant-0 myminio Waiting for Tenant to be healthy green 56s
tenant-0 myminio Initialized green 58s
kubectl get tenants -n tenant-0
NAME STATE HEALTH AGE
myminio Initialized green 3m13s
kubectl get tenants -n tenant-0 -owide -o yaml
...
spec:
configuration:
name: myminio-env-configuration
env:
- name: MINIO_STORAGE_CLASS_STANDARD
value: EC:1
features:
bucketDNS: false
enableSFTP: false
image: quay.io/minio/minio:RELEASE.2025-04-08T15-41-24Z
imagePullPolicy: IfNotPresent
mountPath: /export
podManagementPolicy: Parallel
pools:
- containerSecurityContext:
allowPrivilegeEscalation: false
capabilities:
drop:
- ALL
runAsGroup: 1000
runAsNonRoot: true
runAsUser: 1000
seccompProfile:
type: RuntimeDefault
name: pool-0
securityContext:
fsGroup: 1000
fsGroupChangePolicy: OnRootMismatch
runAsGroup: 1000
runAsNonRoot: true
runAsUser: 1000
servers: 4
volumeClaimTemplate:
metadata:
name: data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
volumesPerServer: 1
poolsMetadata:
annotations: {}
labels: {}
prometheusOperator: false
requestAutoCert: true
subPath: /data
status:
availableReplicas: 4
certificates:
autoCertEnabled: true
customCertificates: {}
currentState: Initialized
drivesOnline: 4
healthStatus: green
pools:
- legacySecurityContext: false
ssName: myminio-pool-0
state: PoolInitialized
revision: 0
syncVersion: v6.0.0
usage:
capacity: 2991747305472
rawCapacity: 3988996407296
rawUsage: 115434881024
usage: 86576160768
writeQuorum: 3
테넌트 배포 완료
NodePort 설정 및 접속 , mc alias 와 버킷 생성
#
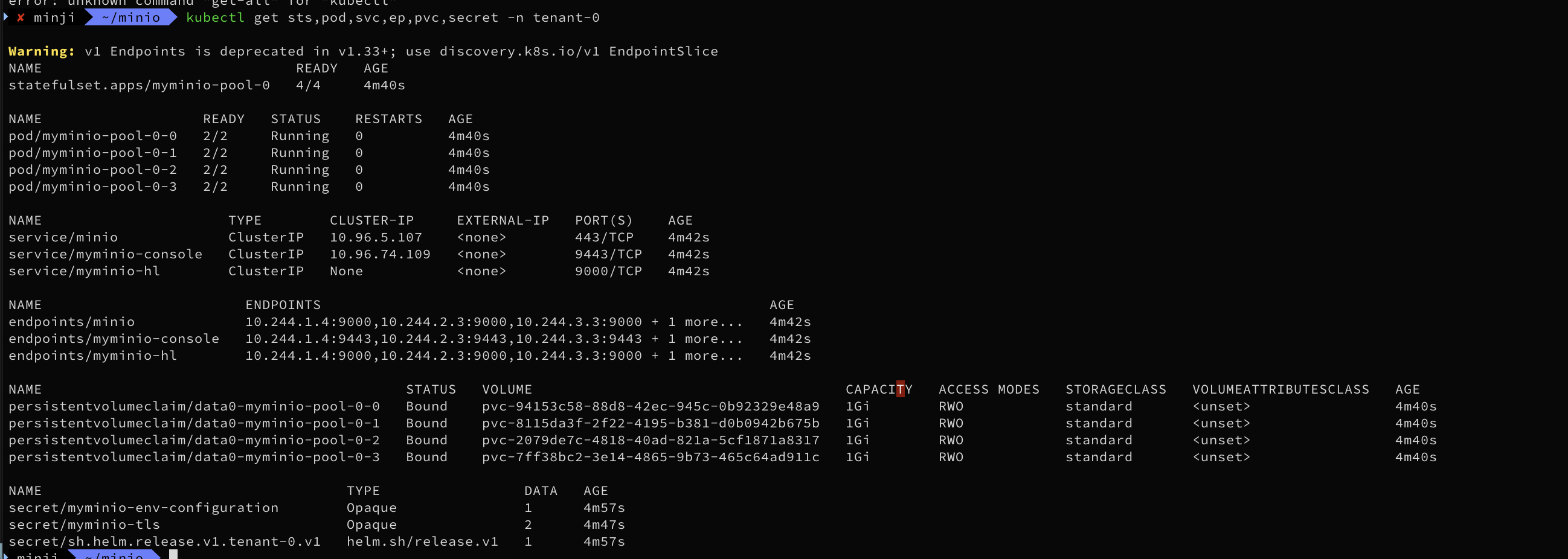
kubectl get-all -n tenant-0
kubectl get sts,pod,svc,ep,pvc,secret -n tenant-0
NAME READY AGE
statefulset.apps/myminio-pool-0 4/4 84s
NAME READY STATUS RESTARTS AGE
pod/myminio-pool-0-0 2/2 Running 0 84s
pod/myminio-pool-0-1 2/2 Running 0 84s
pod/myminio-pool-0-2 2/2 Running 0 84s
pod/myminio-pool-0-3 2/2 Running 0 84s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/minio ClusterIP 10.96.17.142 <none> 443/TCP 85s
service/myminio-console ClusterIP 10.96.252.107 <none> 9443/TCP 85s
service/myminio-hl ClusterIP None <none> 9000/TCP 85s
...
#
kubectl get pod -n tenant-0 -l v1.min.io/pool=pool-0 -owide
kubectl describe pod -n tenant-0 -l v1.min.io/pool=pool-0
kubectl logs -n tenant-0 -l v1.min.io/pool=pool-0
#
kubectl exec -it -n tenant-0 sts/myminio-pool-0 -c minio -- id
uid=1000 gid=1000 groups=1000
kubectl exec -it -n tenant-0 sts/myminio-pool-0 -c minio -- env
...
MINIO_CONFIG_ENV_FILE=/tmp/minio/config.env
...
kubectl exec -it -n tenant-0 sts/myminio-pool-0 -c minio -- cat /tmp/minio/config.env
export MINIO_ARGS="https://myminio-pool-0-{0...3}.myminio-hl.tenant-0.svc.cluster.local/export/data"
export MINIO_PROMETHEUS_JOB_ID="minio-job"
export MINIO_ROOT_PASSWORD="minio123"
export MINIO_ROOT_USER="minio"
export MINIO_SERVER_URL="https://minio.tenant-0.svc.cluster.local:443"
export MINIO_STORAGE_CLASS_STANDARD="EC:1"
export MINIO_UPDATE="on"
export MINIO_UPDATE_MINISIGN_PUBKEY="RWTx5Zr1tiHQLwG9keckT0c45M3AGeHD6IvimQHpyRywVWGbP1aVSGav"
#
kubectl get secret -n tenant-0 myminio-env-configuration -o jsonpath='{.data.config\.env}' | base64 -d ; echo
export MINIO_ROOT_USER="minio"
export MINIO_ROOT_PASSWORD="minio123"
#
kubectl get secret -n tenant-0 myminio-tls -o jsonpath='{.data.public\.crt}' | base64 -d
kubectl get secret -n tenant-0 myminio-tls -o jsonpath='{.data.public\.crt}' | base64 -d | openssl x509 -noout -text
...
Issuer: CN=kubernetes
Validity
Not Before: Sep 10 12:37:02 2025 GMT
Not After : Sep 10 12:37:02 2026 GMT
Subject: O=system:nodes, CN=system:node:*.myminio-hl.tenant-0.svc.cluster.local
...
X509v3 extensions:
X509v3 Key Usage: critical
Digital Signature, Key Encipherment
X509v3 Extended Key Usage:
TLS Web Server Authentication
X509v3 Basic Constraints: critical
CA:FALSE
X509v3 Authority Key Identifier:
23:2A:4E:1A:BF:D1:BB:14:D7:2B:E4:93:EF:CF:DF:98:D0:22:23:A3
X509v3 Subject Alternative Name:
DNS:myminio-pool-0-{0...3}.myminio-hl.tenant-0.svc.cluster.local, DNS:minio.tenant-0.svc.cluster.local, DNS:minio.tenant-0, DNS:minio.tenant-0.svc, DNS:*.myminio-hl.tenant-0.svc.cluster.local, DNS:*.tenant-0.svc.cluster.local
...
kubectl get secret -n tenant-0 myminio-tls -o jsonpath='{.data.private\.key}' | base64 -d
-----BEGIN PRIVATE KEY-----
MIGHAgEAMBMGByqGSM49AgEGCCqGSM49AwEHBG0wawIBAQQgwWq28PCWou2keOFw
rJk4KPRn/Z8xFqob34bDq4dHFBehRANCAASWSrORD9HFR11Jq4z6/PgWMyl2xFbY
WCQeeX46Oadkm5YvEu3boOrt2ibEz/8MddvNtRTGhOO28rVw5kV3p3ME
-----END PRIVATE KEY-----
#
kubectl patch svc -n tenant-0 myminio-console -p '{"spec": {"type": "NodePort", "ports": [{"port": 9443, "targetPort": 9443, "nodePort": 30001}]}}'
# 기본키(minio , minio123)
open https://127.0.0.1:30001
#
kubectl patch svc -n tenant-0 minio -p '{"spec": {"type": "NodePort", "ports": [{"port": 443, "targetPort": 9000, "nodePort": 30002}]}}'
# mc alias
mc alias set k8sminio https://127.0.0.1:30002 minio minio123 --insecure
mc alias list
mc admin info k8sminio --insecure
# 버킷 생성
mc mb k8sminio/mybucket --insecure
mc ls k8sminio --insecure
파일 업로드까지 완료
# 노드에 기본 툴 설치
docker ps
docker exec -it myk8s-control-plane sh -c 'apt update && apt install tree -y'
for node in worker worker2 worker3 worker4; do echo "node : myk8s-$node" ; docker exec -it myk8s-$node sh -c 'apt update && apt install tree -y'; echo; done
#
kubectl describe pv
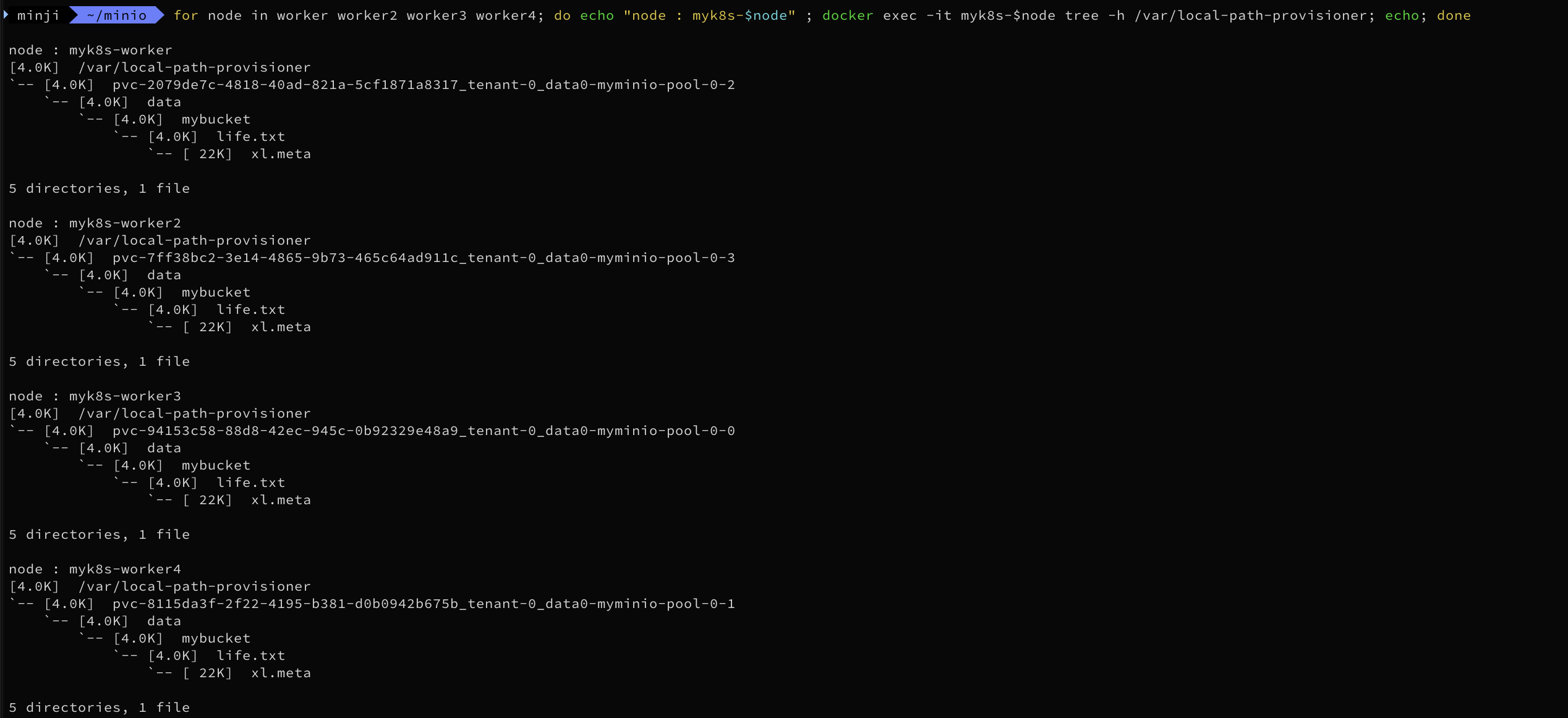
for node in worker worker2 worker3 worker4; do echo "node : myk8s-$node" ; docker exec -it myk8s-$node tree -h /var/local-path-provisioner; echo; done
#
docker exec -it myk8s-worker sh -c 'cat /var/local-path-provisioner/*/data/mybucket/life.txt/xl.meta'
docker exec -it myk8s-worker2 sh -c 'cat /var/local-path-provisioner/*/data/mybucket/life.txt/xl.meta'
docker exec -it myk8s-worker3 sh -c 'cat /var/local-path-provisioner/*/data/mybucket/life.txt/xl.meta'
docker exec -it myk8s-worker4 sh -c 'cat /var/local-path-provisioner/*/data/mybucket/life.txt/xl.meta'
# 혹은 pool-0 파드 내에서 확인
kubectl exec -it -n tenant-0 sts/myminio-pool-0 -c minio -- ls -l /export/data/mybucket/life.txt
total 24
-rw-r--r-- 1 1000 1000 22680 Sep 7 13:51 xl.meta
kubectl exec -it -n tenant-0 sts/myminio-pool-0 -c minio -- cat /export/data/mybucket/life.txt/xl.meta
...
#
mc stat k8sminio/mybucket --insecure
mc stat k8sminio/mybucket/life.txt --insecure
파일 확인 : MNMD 경우 데이터가 Multi Drives 나 Server 로 분산 저장
MinIO의 인증 및 인가 개요
1. 인증 (Authentication)
클라이언트가 MinIO에 연결할 때 본인임을 증명하는 과정입니다.
MinIO는 AWS Signature 버전 4 프로토콜을 사용해 액세스 키(access key)와 비밀 키(secret key)를 검증합니다.
모든 S3 및 MinIO 관리 API 요청(PUT,GET,DELETE등)은 유효한 키가 있어야만 접근할 수 있습니다.
2. 인가 (Authorization)
인증된 사용자에게 어떤 작업과 리소스에 접근할 수 있는 권한을 제한하는 과정입니다.
MinIO는 정책 기반 액세스 제어(PBAC)를 사용하여, 각 사용자나 그룹이 수행 가능한 작업과 접근 가능한 리소스를 정책으로 정의합니다.
명시적으로 허용되지 않은 작업이나 리소스는 기본적으로 거부합니다.
ID 관리 (Identity Management)
MinIO는 내부 ID 관리와 외부 ID 관리 모두 지원합니다.
지원하는 ID 공급자(IDP)는 다음과 같습니다:
IDP 종류설명
MinIO 내부 IDP
MinIO 내장 ID 관리 기능 제공
OpenID Connect (OIDC)
OIDC 호환 서비스 통해 사용자 관리
MinIO Authentication Plugin
사용자 정의 외부 인증 플러그인 지원
Active Directory / LDAP
AD 또는 LDAP 기반 사용자 관리 지원
MinIO Access Management Plugin
사용자 정의 외부 접근 관리 플러그인 지원
인증이 완료되면, MinIO는 해당 사용자가 작업 수행 권한이 있는지 판단해 허용/거부합니다.
upload failed: s1 to s3://s1 An error occurred (AccessDenied) when calling the PutObject operation: Access Denied
권한설정을 잘 줘도 위와 같이 에러가 나는 경우
AWS CLI 및 SDK 특정 버전(예: AWS CLI v2.23.0, boto3 1.36) 이후 버전에서는 Object Storage에서 지원하지 않는 새로운 체크섬 알고리즘이 기본적으로 활성화되기 때문에 요청에 실패한다. 따라서 이전 버전을 사용하거나, 최신 버전에서 해당 체크섬 설정을 비활성화가 필요하다.