
 libmcrypt-2.5.7+(3)+(1).tar.gz
libmcrypt-2.5.7+(3)+(1).tar.gz'job > linux' 카테고리의 다른 글
| unauthenticated user (0) | 2018.09.03 |
|---|---|
| centos 4점대 yum repo (0) | 2018.09.03 |
| no more recursive clients: quota reached (0) | 2018.09.03 |
| mhash-0.9.9 (0) | 2018.09.03 |
| root 계정 ssh접속 안되게 (0) | 2018.08.31 |
| unauthenticated user (0) | 2018.09.03 |
|---|---|
| centos 4점대 yum repo (0) | 2018.09.03 |
| no more recursive clients: quota reached (0) | 2018.09.03 |
| mhash-0.9.9 (0) | 2018.09.03 |
| root 계정 ssh접속 안되게 (0) | 2018.08.31 |
별로 사용하는것도 없는데 트래픽이 많이 나올때
이것 저것 죽여봤다. 아파치 에스큐엘 에프티피등등 named를 죽이니 트래픽이 정상이 됐다.
message 로그를 보니 특정 아이피가 계속 접근을 한다.
두 아이피를 차단하니 트래픽이 정상이 됐다.
그런데 이 두 아이피가 다른 서버에서도 찍힌다. 그래서 아에 백본에서 차단했다.
아래는 메세지 로그
Apr 2 10:11:04 ns named[25359]: client 199.250.62.3#54445: no more recursive clients: quota reached
Apr 2 10:11:04 ns named[25359]: client 193.23.181.38#33974: no more recursive clients: quota reached
Apr 2 10:11:04 ns named[25359]: client 199.250.62.3#29829: no more recursive clients: quota reached
Apr 2 10:11:04 ns named[25359]: client 193.23.181.38#6069: no more recursive clients: quota reached
구글링을 해보니 ..
http://ttend.tistory.com/203
| centos 4점대 yum repo (0) | 2018.09.03 |
|---|---|
| libmcrypt-2.5.7 (0) | 2018.09.03 |
| mhash-0.9.9 (0) | 2018.09.03 |
| root 계정 ssh접속 안되게 (0) | 2018.08.31 |
| pop3 login error (0) | 2018.08.31 |
| libmcrypt-2.5.7 (0) | 2018.09.03 |
|---|---|
| no more recursive clients: quota reached (0) | 2018.09.03 |
| root 계정 ssh접속 안되게 (0) | 2018.08.31 |
| pop3 login error (0) | 2018.08.31 |
| disk fatal error (0) | 2018.08.31 |
$0 실행된 쉘 스크립트 이름
$# 인자의 갯수
$$ 쉘 스크립트의 PID
$1~ $nnn $1은 첫번째 인자 $2는 두번째 n 은 n번째
$* 스크립트에 입력된 인자들의 목록
$@ $*과 같다. 다만 구분자가 IFS변수의 영향을 받지 않는다.
$? 마지막 명령의 결과값(결과값이 없으면 0 , 있으면 1,2 등)
$! 백그라운드 PID
[root@ns dong]# sh test1.sh 1 2 3 4 5 6 7
[$0] 실행된 쉘 스크립트 이름 : test1.sh
[$#] 인자의 갯수 : 7
[$$] 쉘 스크립트의 PID : 25114
[$1 $2 $3 $4] $1은 첫번째 인자 $2는 두번째 n 은 n번째 : 1 2 3 4
[$*] 스크립트에 입력된 인자들의 목록 : 1 2 3 4 5 6 7
[$@] $*과 같다. 다만 구분자가 IFS변수의 영향을 받지 않는다. : 1 2 3 4 5 6 7
[$?] 마지막 명령의 결과값(결과값이 없으면 0 있으면 0말고 다른숫자 ) : 0
[$!] 백그라운드 PID :
---------------------------------------------------
\a 경고음
\b 백스페이스
\n 개행,줄바꿈
\t 수평 탭
\v 수직 탭
| 메모리 실제 장착돼있는 갯수 확인 (0) | 2018.09.03 |
|---|---|
| awk -F 구분자 복수개 지정 가능 (0) | 2018.09.03 |
| 쉘스크립트 비교 연산자 (0) | 2018.09.03 |
| putty psftp 파일 업다운로드 (0) | 2018.09.03 |
| Hdd하드와 ssd 하드에 따른 dbms 속도 비교 (0) | 2018.08.31 |
-eq 같음
-ne 같지 않음
-gt 더 큼
-ge 더 크거나 같음
-lt 더 작음
-le 더 작거나 같음
[ "$A" -ne "$B" ]
< 더 작음
<= 더 작거나 같음
> 더 큼
>= 더 크거나 같음
(("$A" >= "$B"))
문자열 비교
= 같음
== 같음(= 와 동의어)
!= 같지 않음
if [ "$A" = "$B" ]
< 아스키 알파벳 순서에서 더 작음
if [[ "$A" < "$B" ]]
or
if [ "$A" \< "$B" ]
> 아스키 알파벳 순서에서 더 큼
if [[ "$A" > "$B" ]]
or
if [ "$A" \> "$B" ]
-z 문자열이 "null"임. 즉, 길이가 0
-n 문자열이 "null"이 아님.
| awk -F 구분자 복수개 지정 가능 (0) | 2018.09.03 |
|---|---|
| 쉘스크립트 변수 설명 (0) | 2018.09.03 |
| putty psftp 파일 업다운로드 (0) | 2018.09.03 |
| Hdd하드와 ssd 하드에 따른 dbms 속도 비교 (0) | 2018.08.31 |
| warning: unmappable character for encoding UTF8 (0) | 2018.08.31 |
psftp 들어가서
open 아이피
접속하고
help 명령어 치면 대충 보임
get test.txt
다운로드
put etst.txt
업로드
| 쉘스크립트 변수 설명 (0) | 2018.09.03 |
|---|---|
| 쉘스크립트 비교 연산자 (0) | 2018.09.03 |
| Hdd하드와 ssd 하드에 따른 dbms 속도 비교 (0) | 2018.08.31 |
| warning: unmappable character for encoding UTF8 (0) | 2018.08.31 |
| rpmforge (0) | 2018.08.31 |
Hdd하드와 ssd 하드에 따른 dbms 속도 비교..
Dbms는 데이터 버퍼링(페이지 버퍼링_일종의 캐시)을 하고 있기 때문에
데이터 버퍼링이 효과적으로 수행되는 환경이라면(캐시 시스템의 히트율이 높다면)저장 매체(hdd나 ssd)의 i/o 실행 성능이 상대적으
로 중요하지 않게 된다.
그래서 hdd를 ssd로 바꿔서 효과를 얻고 싶다면 dbms의 데이터 버퍼링이 효율적으로 동작하고 있는지 파악하는게 중요하다. 저장 매체를 ssd가 아니여도 데이버 버퍼 설정만으로도 효과적인 성능 향상이 가능하다.
결론은 hdd에서 sdd로 바꿔봐야 거의 차이가 없다는거고 dbms의 성능을 올리려면 메모리를 늘려서 데이터 버퍼를 늘려주자
네이버 d2 사이트에서 본건데 데이터 버퍼 사이즈가 10g 이상 넘어가면 hdd에서 ssd로 바꾸는게 더 효과적이라고 한다.
요새는 ssd 워낙 싸졌으니까 그냥 ssd 쓰자
| 쉘스크립트 비교 연산자 (0) | 2018.09.03 |
|---|---|
| putty psftp 파일 업다운로드 (0) | 2018.09.03 |
| warning: unmappable character for encoding UTF8 (0) | 2018.08.31 |
| rpmforge (0) | 2018.08.31 |
| ssl 인즉서 적용 확인하는곳 (0) | 2018.08.31 |
root 계정 ssh 접속 안되게끔
vi /etc/ssh/sshd_config
열어서 PermitRootLogin no
vi /etc/pam.d/su
열어서
32비트는 auth required /lib/security/pam_wheel.so debug group=wheel
64비트는 auth required /lib64/security/pam_wheel.so debug group=wheel
넣어주고
vi /etc/group
wheel 그룹에다가 수권한 획들할 계정 넣어준다.
| no more recursive clients: quota reached (0) | 2018.09.03 |
|---|---|
| mhash-0.9.9 (0) | 2018.09.03 |
| pop3 login error (0) | 2018.08.31 |
| disk fatal error (0) | 2018.08.31 |
| Connection closed by foreign host 또는 Broken pipe (0) | 2018.08.31 |
Httperr log_number .log 파일은 \System32\LogFiles\HTTPERR
| linux inode window fileid (0) | 2019.01.11 |
|---|---|
| iis 백업 복원 이전 (0) | 2018.09.03 |
| 윈도우 2012 원격 세션 제한 (0) | 2018.09.03 |
| 윈도우 tail 명령어 사용하기 / 현재 디렉토리 에서 cmd 창 열기 (0) | 2018.08.31 |
| install media player on windows server 2012 (0) | 2018.08.31 |
pop3 로그인 에러
로그
pop3-login: Disconnected (tried to use disabled plaintext auth):
해결
vi /etc/dovecot/conf.d/10-ssl.conf
# SSL/TLS support: yes, no, required. <doc/wiki/SSL.txt>
ssl = no
vi /etc/dovecot/conf.d/10-auth.conf
# connection is considered secure and plaintext authentication is allowed.
disable_plaintext_auth = no
| mhash-0.9.9 (0) | 2018.09.03 |
|---|---|
| root 계정 ssh접속 안되게 (0) | 2018.08.31 |
| disk fatal error (0) | 2018.08.31 |
| Connection closed by foreign host 또는 Broken pipe (0) | 2018.08.31 |
| eth0: Error reading PHY register (0) | 2018.08.31 |
/var/log/messages
Buffer I/O error
EXT3-fs error
ext3_abort called
ext2_check_page: bad
Attempting host reset
dmesg | grep 'I/O error'
attempt to access beyond end of device
| root 계정 ssh접속 안되게 (0) | 2018.08.31 |
|---|---|
| pop3 login error (0) | 2018.08.31 |
| Connection closed by foreign host 또는 Broken pipe (0) | 2018.08.31 |
| eth0: Error reading PHY register (0) | 2018.08.31 |
| 파티션 용량 5% 깍이는거 (0) | 2018.08.31 |
ssh root 접속 막아놓고 일반 계정으로 접속해서 su 권한 획득하는 서버에서
Connection closed by foreign host 또는 Broken pipe
라는 에러가 난다. 구글링 해보면 여러가지 이유가 있는데 다 안됐다.
root 바로 접속되게 ssh 설정파일에서 수정해주고 root로 접속하면 잘 된다.
원인은
vi
/etc/security/limits.d/90-nproc.conf
* soft nproc 1024
root soft nproc unlimited
여기서 일반 계정은 프로세스 제한이 1024 고 루트는 무한대
내가 수권한 획득할 계정 A의 프로세스가 1024개가 꽉찬 상태였다.
ex)루트 권한 획득할 계정에서 java라던가 하여튼 어떤 프로세스를 1024개 이상 실행키기면 접속할때 필요한 프로세스들을 생성을 못해서 ssh가 붙지 않는다
앞으로 수권한 획득할 계정은 그냥 로그인 용도로만 사용하자.
| pop3 login error (0) | 2018.08.31 |
|---|---|
| disk fatal error (0) | 2018.08.31 |
| eth0: Error reading PHY register (0) | 2018.08.31 |
| 파티션 용량 5% 깍이는거 (0) | 2018.08.31 |
| No space left on device ( df -i , i-node) (0) | 2018.08.31 |
vi/etc/grub.conf
v
kernel /vmlinuz-2.6.32-504.16.2.el6.x86_64 ro root=/dev/sda2 rd_NO_LUKS LANG=en_US.UTF-8 rd_NO_MD crashkernel=auto KEYBOARDTYPE=pc KEYTABLE=us rd_NO_LVM rd_NO_DM pcie_aspm=off rhgb quiet
pcie_aspm=off 이거 추가
저걸 켜놓으면 실제 서버에서 저 기능을 지원을 안해도 강제로 지원되는것처럼해서 뭐 장애를 유발시키는 그런건가..
저 기능은 무슨 파워 전력 뭐 그런거랑 관련있는거라고함
| disk fatal error (0) | 2018.08.31 |
|---|---|
| Connection closed by foreign host 또는 Broken pipe (0) | 2018.08.31 |
| 파티션 용량 5% 깍이는거 (0) | 2018.08.31 |
| No space left on device ( df -i , i-node) (0) | 2018.08.31 |
| vi 에디터에서 utf8, euc-kr 전환하기 (펌글) (0) | 2018.08.31 |
리눅스 시스템에서 root 계정이 예비로 사용할수 있도록 각 파티션의 5%를 예비블록으로 빼놈
ex)해당 파티션에 용량이 꽉찼을때 루트가 접속해서 그걸 정리를 하든 삭제를하든 뭔가 작업을 해야하는데 그런걸 대비해서 5% 빼놈
이거는 다른계정은 사용할수 없고 root 만 사용할수 있다. (용량이 꽉차도 어느정도의 복사 이동이 루트계정은 가능)
각 파티션에 tune2fs -l /dev/sda1 | grep -i "block count" 로 어느정도 때갔는지 확인가능
http://unix.stackexchange.com/questions/7950/reserved-space-for-root-on-a-filesystem-why
| Connection closed by foreign host 또는 Broken pipe (0) | 2018.08.31 |
|---|---|
| eth0: Error reading PHY register (0) | 2018.08.31 |
| No space left on device ( df -i , i-node) (0) | 2018.08.31 |
| vi 에디터에서 utf8, euc-kr 전환하기 (펌글) (0) | 2018.08.31 |
| 커널 패닉,행업,크래쉬 kernel panic crash hangup 분석 (0) | 2018.08.31 |
warning: unmappable character for encoding UTF8
인코딩한 PC 환경이 ANSI(euckr) 에서 서버가 UTF8 형식에서 실행할때 에러난다.(여튼 인코딩 언어가 달르면 저런 에러)
쉽게는 파일안에 한글로 주석돼있는것들 다 없애면 된다.
아니면 윈도우 인코딩 언어를 utf8로 맞추든가..
여튼 다른곳에서 작업했다면 해당 서버의 인코딩 언어 맞춰줘야함
아니면 서버에서 vi .vimrc 열어서
set fileencodings=utf8,euc-kr
넣어노면 지가 자동으로 utf8 이나 euc-kr 알아서 연다
| putty psftp 파일 업다운로드 (0) | 2018.09.03 |
|---|---|
| Hdd하드와 ssd 하드에 따른 dbms 속도 비교 (0) | 2018.08.31 |
| rpmforge (0) | 2018.08.31 |
| ssl 인즉서 적용 확인하는곳 (0) | 2018.08.31 |
| ncdu 명령어 (0) | 2018.08.31 |
no space left on device
용량 부족할때 이런 에러메세지 출력된다. 근데 df -h 했을때 실제 용량은 많다. 그럴땐 df -i 를 해보자.
용량은 충분한데 i-node 공간이 꽉차도 저런 에러가 뜬다. // i-node 란 각 파일 혹은 디렉토리의 정보를 가지고 있는 자료구조라는데.. 뭐랄까 주민번호 ? 여튼 64byte다.
이럴땐 rm 으로 쓰잘때기없는 파일(불필요한 세션파일이나 뭐 그런 안쓰는 옛날 파일들 ) 직접 삭제하면 삭제한 갯수만큼 i-node 공간이 늘어난다.
아니면 파일시스템을 튜닝해서 기본 i-node 값을 늘리면 되는데(디폴트는 16384) blocksize보다 커야하낟.
ex) mkfs -t ext3 -i 4096 /dev/sda8
기본이 16384에서 4096으로 주면 실제 inode 는 4배 늘어난다.
| eth0: Error reading PHY register (0) | 2018.08.31 |
|---|---|
| 파티션 용량 5% 깍이는거 (0) | 2018.08.31 |
| vi 에디터에서 utf8, euc-kr 전환하기 (펌글) (0) | 2018.08.31 |
| 커널 패닉,행업,크래쉬 kernel panic crash hangup 분석 (0) | 2018.08.31 |
| centos 5.9 64bit geoip iptables 설치 (0) | 2018.08.31 |
| linux inode window fileid (0) | 2019.01.11 |
|---|---|
| iis 백업 복원 이전 (0) | 2018.09.03 |
| 윈도우 2012 원격 세션 제한 (0) | 2018.09.03 |
| iis 에러 로그 (0) | 2018.08.31 |
| install media player on windows server 2012 (0) | 2018.08.31 |
update ABCDE set column1='xyz' where no='3'
'ABCDE' 테이블의
'column1' 컬럼 값을 'xyz' 으로 수정한다.
수정대상은 'no' 컬럼값이 '3' 인 레코드 전부이다.
update ABCDE set column1='xyz' where no>3
'ABCDE' 테이블의
'column1' 컬럼 값을 'xyz' 으로 수정한다.
수정대상은 'no' 컬럼값이 '3' 보다 큰 레코드 전부이다.
update ABCDE set point=(point+50) where no<>3
'ABCDE' 테이블의
'point' 컬럼 값을 현재 값보다 50을 더한 값으로 수정한다.
수정대상은 'no' 컬럼값이 '3' 이 '아닌' 레코드 전부이다.
update ABCDE set column1='xyz',column2='1234' where point>3 and point<100
'ABCDE' 테이블의
'column1' 컬럼 값을 'xyz' 으로, 'column2' 컬럼 값을 '1234' 로 수정한다.
수정대상은 'point' 컬럼값이 '3' 보다 크고 100 보다 작은 레코드 전부이다.
update ABCDE set column1='xyz' where no>3 order by uid limit 20
'ABCDE' 테이블의
'column1' 컬럼 값을 'xyz' 으로 수정한다.
수정대상은 'no' 컬럼값이 '3' 보다 큰 레코드이고,
전체목록을 uid 컬럼값을 기준으로 정렬해서 상위 20 개를 수정한다.
update ABCDE set column1=replace(column1,'코리아','한국')
'ABCDE' 테이블의
'column1' 컬럼 값에 '코리아' 라는 단어가 포함되어 있다면 모두 '한국' 으로 수정한다.
update ABCDE set column1=replace(column1,'코리아','한국') where wdate>1159454960
'ABCDE' 테이블의
'column1' 컬럼 값에 '코리아' 라는 단어가 포함되어 있는 것은 '한국' 으로 수정한다.
수정대상은 wdate 컬럼의 값이 1159454960 보다 큰 레코드 이다.
update ABCDE set column1=concat(column1,'hellow') where no>5
'ABCDE' 테이블의
'column1' 컬럼 값에 'hellow' 라는 단어를 덧붙인다.
수정대상은 no 컬럼의 값이 5 보다 큰 레코드 이다.
출처
https://www.technote.co.kr/php/technote1/board.php?board=faq&command=body&no=14
| mysql 로그 설정 (0) | 2018.09.03 |
|---|---|
| mysql 계정생성등 (0) | 2018.09.03 |
| 데이터 원본 이름이 없고 기본 드라이버를 지정하지 않았습니다. (0) | 2018.08.31 |
| FATAL ERROR: Could not find ./bin/my_print_defaults (0) | 2018.08.31 |
| innodb memcached plugin 설치 (0) | 2018.08.31 |
vi로 웹문서를 열어 보면 한글이 깨어져 있고
<meta http-equiv=Content-Type Content="text/html; charset=euc-kr">이 보인다면
리눅스 콘솔창에 env 해 볼때 LANG=ko_KR.UTF-8 으로 나온면 utf8 환경입니다.
Q) 그럼 한글이 깨어져 보이는 utf-8 시스템 환경에서 euc-kr 웹문서를 제대로 볼 수 없는 것인가?
A) 리눅스 환경이라면 vi 환경설정 파일인 .vimrc 파일에 set fileencodings=utf8,euc-kr 를 추가하면 문서를 열때 자동적으로 fileencoding이 utf8인지 euc-kr 인지 encoding에 맞게 열고 저장을 합니다.
계정 로그아웃(재접속)하지 않고 vi 설정을 적용할려면 콘솔에서 source .vimrc 하고 엔터키를 누르면 됩니다.
Q) 그럼 euc-kr 파일 웹문서를 utf8 파일로 변경을 하고 싶다면 어떻게 하죠?
A) vi로 파일을 열고 나서
:set fileencoding=utf-8
:w
하면 됩니다. 저장 후 종료를 할려면 :wq 엔터를 하면 됩니다.
반대로 utf8 문서를 euc-kr로 변경 할려면 :set fileencoding=euc-kr을 하면 됩니다.
euc-kr 웹문서를 utf8로 변경 하고 저장 했다면
<meta http-equiv=Content-Type Content="text/html; charset=utf-8">
로 하지 않으면 웹브라우저에서 확인시에는 다시 한글이 깨어져 보이겠죠.
Q) vi 에디터로 열지 않고 euc-kr 웹문서를 utf8로 변경 할려고 합니다. 어떻게 해야 하죠?
A) iconv 명령어로 가능합니다.
iconv -f euc-kr -t utf-8 euc-kr.html --output utf8.html
or
iconv -f euc-kr -t utf-8 euc-kr.html > utf8.html
Q)한개 파일이 아니라 여러개의 html 파일을 동시에 변경 할려면 어떻게 하죠?
백업 파일처럼 utf8.html로 할 필요없이 그냥 utf-8 파일로 변환 되면 좋겠는데요??
A)
변경을 원하는 경로로 이동을 하고 아래와 같은 명령어로 한방에 그럼 변경해 보겠습니다.
cd /web/files
for I in ./-.html ; do iconv -c -f euc-kr -t utf-8 $I > $I.tmp && mv $I.tmp $I ; done
작업 완료 전에는 무조건 백업본을 유지하는 것이 좋습니다. 그냥 원본폴더를 tar로 묶어 두면 되죠.
시스템 환경에 따라 작업 환경에 따라 charset encoding은 테스트 작업을 하고 본격적으로 진입 하는 것이 바람직합니다.
Q) recode 명령어로 한번에 변경 할 수 있다고 하는데 어떻게 하나요?
A) 먼저 시스템에 recode 명령어를 사용할 수 있는지 확인 해야 하는데
rpm -qi recode 해서 아무것도 안나오면 설치 해야합니다.
yum install recode recode-devel 또는 rpm을 찾아서 설치 하거나
http://recode.progiciels-bpi.ca/index.html 접속해서 파일을 받아서 설치합니다.
recode 명령어로 얼마나 많은 charset 변경을 할 수 있는지 확인은
recode -l 로 살펴 보면 됩니다. 그럼 euc-kr에서 utf-8로 변경 명령어는 아래와 같습니다.
recode -v <소스 CHARSET>...<변환 CHARSET> <파일명>
recode -v EUC-KR...UTF-8 *.html
Q) php에서 특정 문자열만 euc-kr 또는 utf8로 할려면 어떻게 하죠?
A) iconv 함수를 이용하면 됩니다.
iconv("euc-kr", "utf-8", $str); // euc-kr을 utf8로 encoding 됩니다.
iconv("utf-8", "euc-kr", $str); // utf8을 euc-kr로 encoding 됩니다.
참조 URL : http://www.php.net/manual/en/function.iconv.php
Q) java,jsp에서 문자열 encoding 전환은?
A)
StringBuffer szBuffer = new StringBuffer();
String str = new String(szBuffer.toString().getBytes("UTF-8"), "EUC-KR");
http://download.oracle.com/javase/1.5.0/docs/guide/intl/encoding.doc.html
여전히 한글이 깨어진다면 아래 상황을 체크 해 봅니다.
추가 옵션으로 export CATALINA_OPTS='-Dencoding.default=euc-kr -Dfile.encoding=euc-kr'
Q) 윈도우 노트패드(notepad)에서 encoding 변환 작업은 할 수 없나요?
A) 윈도우에서 작업 가능한 무료 에디터 notepad++를 소개 해 드립니다.
http://notepad-plus-plus.org/ 접속 후 다운로드(DOWNLOAD) 메뉴에서 받으시면 됩니다.
윈도우에서 생성한 ANSI Encoding 파일을 상단 메뉴 Encoding 에서
Convert to UTF-8 without BOM (UTF-8 형식으로 변환 BOM 없음) 으로 선택하시면 UTF-8 Charset 으로 변환이 됩니다.
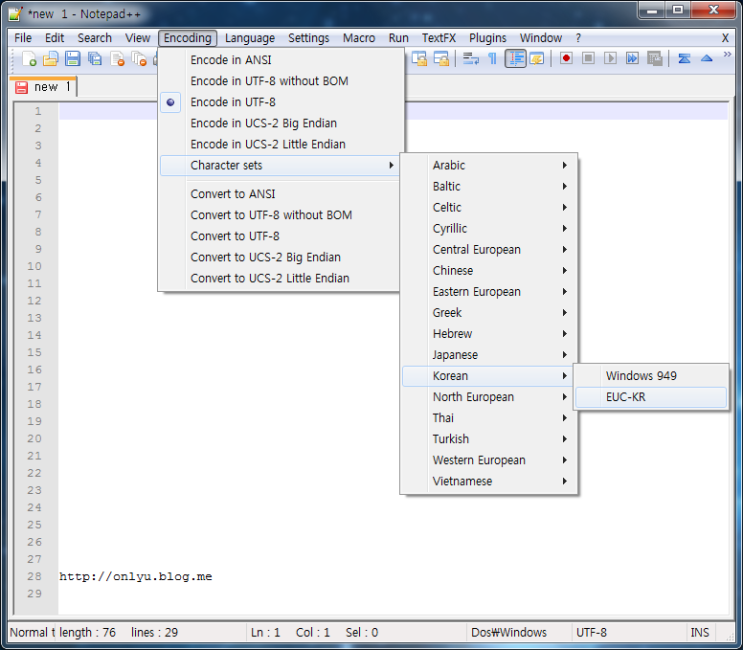
(notepad++ 메뉴를 한글로 변경 Settings > Preferences > General Localization 셀렉터 항목에 한국어를 선택하면 됩니다.)
(추가)
Q) 여러 사이트에서 넘어 오는 값이 각각 다른데 utf8 인지 euc-kr 인지 어떻게 알죠?
A) php 경우라면 mb_detect_encoding($str); 로 찍어 보면 압니다.
하여 각각 원하는 encoding을 iconv로 변환을 해 주면 됩니다.
원문
http://egloos.zum.com/indirock/v/3791689
install media player on windows server 2012
윈도우 서버 2012 에 wmp ( windwos media player ) 윈도우 미디어 플레이어 설치하기
윈도우 2008에서는 데스크톱 경험 설치하면된다.
윈도우 2012도 똑같다.
근데 위치가 다르다.
서버관리자-대시보드에서 기능 클릭하고 ## 여기서부터 다르다##
사용자 인터페이스 및 인프라 안에 데스크톱 경험이 있다.
그거 설치하면 됨
| linux inode window fileid (0) | 2019.01.11 |
|---|---|
| iis 백업 복원 이전 (0) | 2018.09.03 |
| 윈도우 2012 원격 세션 제한 (0) | 2018.09.03 |
| iis 에러 로그 (0) | 2018.08.31 |
| 윈도우 tail 명령어 사용하기 / 현재 디렉토리 에서 cmd 창 열기 (0) | 2018.08.31 |
데이터 원본 이름이 없고 기본 드라이버를 지정하지 않았습니다.
mysql connector/odbc 사용할때 로컬 pc 비트수에 상관없이 접속할 서버에 맞춰서 다운받아야한다.
ex)pc 32bit고 db서버가 64bit면 64비트용 받아야함 반대로 pc가 64비트 db서버가 32비트면 32비트용
| mysql 계정생성등 (0) | 2018.09.03 |
|---|---|
| mysql update (0) | 2018.08.31 |
| FATAL ERROR: Could not find ./bin/my_print_defaults (0) | 2018.08.31 |
| innodb memcached plugin 설치 (0) | 2018.08.31 |
| ERROR 1238 (HY000): Variable 'log_slow_queries' is a read only variable (0) | 2018.08.31 |
커널 크래쉬(패닉) 혹은 Hangup 상태에서의 매직키 ( sysrq + m, t ) 등을 통한 코어덤프 생성후,
그 덤프파일을 분석하는 과정을 설명하는 문서이다.
Document Ver. - 2.1
Version History : 2009/5/5 - 1.0, 2009/12/16 - 2.0,2010/03/04 - 2.1
Written by Mirr at LDS ( Linuxdata system.co.ltd )
Test Enviroment - RedHat Enterprise Linux 계열
필요한 툴 : crash ( crash 패키지 ), kernel-debug 패키지, kernel-devel 혹은 kernel-source 패키지. (코드분석을 위함)
햄버거 + 콜라 혹은 감자칩 + Beer.
커널 디버깅을 쉽게 할 수 있도록 제작된 레드햇에서 제공하는 툴.
sys - 시스템의 일반적인 정보를 출력해 준다.
bt - Backtrace 명령. 스택의 내용들을 순차적으로 출력해준다.
ps - Process list 출력.
free - Memory 및 스왑 상태 출력.
mount - 마운트 상태 출력
irq - 각 장치의 ( irq ) 상태를 출력.
kmem - 메모리 상태 출력 ( kmalloc, valloc 등 메모리 할당 상태도 보여줌 )
log - dmesg 의 내용을 출력.
mod - 로딩된 모듈 리스트 출력.
net - Network 상태 출력.
runq - 실행중인 task 리스트 출력.
task - 작업목록 출력.
rd - 메모리 번지수에 대한 상세정보 출력.
foreach - 모든 task, process 등 디버깅 정보에 대한 상세한 출력이 가능함.
set - 설정된 주소 및 PID 등을 기본 컨텍스트로 설정.
struct - 구조화된 메모리 내부의 변수들을 출력해 준다.
files - task 가 열고있는 파일디스크립터들을 출력해준다.
Usage: crash {namelist} {dumpfile}
[root@Test DUMP]# crash vmlinux vmcore
Crash 로 코어덤프를 분석하기 위해선 Debug 모드가 활성화 된 상태의 커널이 필요하다. ( kernel-debug )
실제론 동일 버젼의 커널 디버그패키지의 vmlinuz 를 합축해제한 vmlinux 파일을 필요로 한다.
debug 커널의 vmlinux 추출 방법은 다음과 같다.
[root@Test DUMP]# rpm2cpio kernel-debug-{version}.rpm | cpio -idh
[root@Test DUMP]# cd boot && od -A d -t x1 vmlinuz | grep '1f 8b 08 00'
0019296 40 db 20 00 18 00 00 00 42 e1 0f 00 1f 8b 08 00
[root@Test boot]# dd if=vmlinuz bs=1 skip=19308 | zcat > vmlinux
간단히 설명하자면 rpm2cpio 로 rpm 의 내용을 추출 후,
vmlinuz 파일을 dd 명령으로 압축 해제 하는 것이다.
od 명령은 octaldump 로 file 을 특정 진법으로 덤프시켜주는 툴인데,
이것을 통해 압축코드 (1f 8b 08 00) 가 시작되는 주소를 찾아내어
압축되지 않은 vmlinux 를 추출하기 위한 작업이며, dd 명령을 통해 압축코드시작주소 ((0019296 + 12 ) 부터
덤프를 뜬뒤, zcat 으로 추출하는 과정이다. ( 역시 풀어설명하는게 더 복잡하다 그냥 명령어 코드 보자 )
[root@Test boot]$ crash vmlinux vmcore
crash 4.0-7
Copyright (C) 2002, 2003, 2004, 2005, 2006, 2007, 2008 Red Hat, Inc.
Copyright (C) 2004, 2005, 2006 IBM Corporation
Copyright (C) 1999-2006 Hewlett-Packard Co
Copyright (C) 2005, 2006 Fujitsu Limited
Copyright (C) 2006, 2007 VA Linux Systems Japan K.K.
Copyright (C) 2005 NEC Corporation
Copyright (C) 1999, 2002, 2007 Silicon Graphics, Inc.
Copyright (C) 1999, 2000, 2001, 2002 Mission Critical Linux, Inc.
This program is free software, covered by the GNU General Public License,
and you are welcome to change it and/or distribute copies of it under
certain conditions. Enter "help copying" to see the conditions.
This program has absolutely no warranty. Enter "help warranty" for details.
GNU gdb 6.1
Copyright 2004 Free Software Foundation, Inc.
GDB is free software, covered by the GNU General Public License, and you are
welcome to change it and/or distribute copies of it under certain conditions.
Type "show copying" to see the conditions.
There is absolutely no warranty for GDB. Type "show warranty" for details.
This GDB was configured as "i686-pc-linux-gnu"...
WARNING: kernels compiled by different gcc versions:
vmlinux: 3.4.6
vmcore kernel: 3.4.4
KERNEL: vmlinux
DUMPFILE: vmcore
CPUS: 4
DATE: Sun Apr 19 00:01:01 2009
UPTIME: 171 days, 10:40:23
LOAD AVERAGE: 0.07, 0.15, 0.11
TASKS: 252
NODENAME: node1
RELEASE: 2.6.9-22.ELsmp
VERSION: #1 SMP Mon Sep 19 18:32:14 EDT 2005
MACHINE: i686 (3392 Mhz)
MEMORY: 12.5 GB
PANIC: "kernel BUG at include/asm/spinlock.h:146!"
PID: 12339
COMMAND: "run-parts"
TASK: f3f02c30 [THREAD_INFO: cd001000]
CPU: 0
STATE: TASK_RUNNING (PANIC)
crash>
실제 코어분석중 주로 사용하게 되는 명령어들과 그것들에 대한 실제 사용법을 Case 별로 보여준다.
커널 패닉 혹은 Hangup 이 잦은 서버로써, 대부분의 스펙은 동일한 서버이나,
지역적으로 서로 떨어져 있으며, 산발적으로 일어나는 현상이라며 고객이 징징대고 있는 상황이다..... ㅜ.,ㅜ
OS : RedHat Enterprise Linux 4 Update 2 ( Kernel Ver. 2.6.9-22.ELsmp )
KERNEL: vmlinux
DUMPFILE: vmcore
CPUS: 4
DATE: Sun Apr 19 00:01:01 2009
UPTIME: 171 days, 10:40:23
LOAD AVERAGE: 0.07, 0.15, 0.11
TASKS: 252
NODENAME: node1
RELEASE: 2.6.9-22.ELsmp
VERSION: #1 SMP Mon Sep 19 18:32:14 EDT 2005
MACHINE: i686 (3392 Mhz)
MEMORY: 12.5 GB
PANIC: "kernel BUG at include/asm/spinlock.h:146!"
PID: 12339
COMMAND: "run-parts"
TASK: f3f02c30 [THREAD_INFO: cd001000]
CPU: 0
STATE: TASK_RUNNING (PANIC)
crash> bt -t
위의 과정들을 거친 끝에 우리는 irq_balance 등이 이루어져 cpu 자원의 (멀티코어 및 멀티CPUs) 할당이 이루어지는 도중
spinlock 의 문제로 커널패닉이 떨어졌음을 확인 할 수 있다.
위 문제에 대한 해답은 뚜렷하게 얻지 못했지만, SMP 커널의 spinlock 문제라는 것을 알았으므로,
kernel.org 혹은 redhat 에서 버그를 찾아 볼 힌트가 생겼으며, 커널의 업데이트를 고객에게 권고할 수 있게 되었다.
kernel.org 등에서 리포팅되어있는 버그로 보여지며, 완전한 해결책은 나와있지 않았으나,
RHEL 이므로 RedHat 의 패치가 이루어 졌을 수도 있으니, 정식 update 를 권장하였다.
Mailserver 가 자꾸 뻗습니다... 라는 고객의 다소 황망스러운 요청....
결국 히스토리나 기타 정보들이 없다보니 덤프분석뿐이라는 결론으로 덤프 분석에 들어간다.
OS : RHEL 3 Update 8 ( Kernel Ver. 2.4.21-47.ELhugemem
KERNEL: vmlinux2.4.2147.ELhugemem
DEBUGINFO: ./vmlinux2.4.2147.ELhugemem.debug
DUMPFILE: vmcore
CPUS: 8
DATE: Wed Apr 16 06:52:58 2008
UPTIME: 14:34:12
LOAD AVERAGE: 0.48, 0.21, 0.13
TASKS: 206
NODENAME: ***min02.*****.co.kr
RELEASE: 2.4.2147.ELhugemem
VERSION: #1 SMP Wed Jul 5 20:30:35 EDT 2006
MACHINE: i686 (3669 Mhz)
MEMORY: 16.8 GB
PANIC: ""
PID: 20093
COMMAND: "save"
TASK: bd0c0000
CPU: 1
STATE: TASK_RUNNING (PANIC)
crash> bt
PID: 20093 TASK: bd0c0000 CPU: 1 COMMAND: "save"
#0 [bd0c1cf0] netconsole_netdump at f9384783
#1 [bd0c1d04] try_crashdump at 2129783
#2 [bd0c1d14] die at 210cdc2
#3 [bd0c1d28] do_invalid_op at 210cfd2
#4 [bd0c1dc8] error_code (via invalid_op) at 22ad29d
EAX: 00000053 EBX: 00000010 ECX: 000f6000 EDX: 0015b8f0 EBP: 0817586c
DS: 0068 ESI: 023a9408 ES: 0068 EDI: 023a8200
CS: 0060 EIP: 02159f7d ERR: ffffffff EFLAGS: 00010006
#5 [bd0c1e04] rmqueue at 2159f7d
#6 [bd0c1e40] __alloc_pages_limit at 215a268
#7 [bd0c1e58] __alloc_pages at 215a36f
........ 중략 ............
#14 [bd0c1fc0] system_call at 22ad091
EAX: 00000003 EBX: 0000000e ECX: 08324000 EDX: 00010000
DS: 002b ESI: 0814c790 ES: 002b EDI: fefff440
SS: 002b ESP: feff10c8 EBP: 00000000
CS: 0023 EIP: f65deb7e ERR: 00000003 EFLAGS: 00000246
crash> rd 08175860 40
175860: 44445320 362e3120 302e322e 3220312d SDD 1.6.2.01 2
8175870: 322e342e 37342d31 634c452e 6f747375 .4.2147.ELcusto
8175880: 4d53206d 53202050 31207065 30322032 m SMP Sep 12 20
8175890: 32203630 37313a30 2037323a 20294328 06 20:17:27 (C)
81758a0: 204d4249 70726f43 00000a2e 00000000 IBM Corp........
81758b0: 00000000 00000000 00000000 00000000 ................
81758c0: 02001000 00000000 00000000 00000000 ................
81758d0: 00000000 00000000 00000000 00000000 ................
81758e0: 00000000 00000000 00000000 00000000 ................
81758f0: 00000000 00000000 00000000 02001000 ................
crash>
사실 이번 케이스는 과정을 매우 중략시켰다. 왜?? 사실 이 케이스는 내가 직접 코어분석을 한 부분이아니고,
다른 사람의 분석자료를 긁어다 붙혔기때문이랄까...(먼산 ㅡ.,ㅡ:: )
아무튼 이 분석의 결과는 IBM sdd 드라이버의 문제로 추정되었고, 고객에게 IBM sdd 드라이버를 업데이트
하는 것으로 마무리 되었다.
뭐 자세한 이유를 설명하자면 위에서 bt 과정에서 rmqueue 부분에서 시스템 패닉이 발생되었음을
알 수 있었고, rmqueue 는 장치(block)를 해제(free)시켜주는 시스템 콜인데, 정상적으로 해제 하지 못한 장치가
있었다는 의미며, 이때당시의 EBP 메모리 주소의 내용을 넓은 범위로 까보니 ( rd 08175860 40 )
SDD 드라이버의 버젼정보가 남아있는 것으로 보아, 커널에서 이 드라이버와 관계된 작업을 정상적으로
Page 재할당 혹은 해제 하지 못했음을 추정 할 수 있었던 게다.....
기존 1번 상황과 같은 엔드유저.
상황은 저번과 다르나 nfs 관련된 서버들이 이상하게 자꾸 뻗는 현상 발생.
역시 그냥 뻗었다면서 sysreport 와 커널덤프파일만 보내온상황..
시스템 (OS) : RedHat Enterprise Linux 4 WS
Kernel Ver. : 2.6.9-22.ELsmp
Machine : i686
Memory : 2G
길다. 대략 요즘 보면 RedHat 에스컬레이션 시 분석엔지니어가 log 명령을 통해 상세한 로그를 얻어서 분석하던데,
나도 따라해 봤다. 일반 sysreport 에서 남겨지는 message 로그와는 확연히 다른 상세 로그가 남았다.
역시 가장 마지막 실행된 데몬 혹은 명령은 nodemon 이라는 녀석이다.
....중략.....
ps 로 확인 해 보았을 때 역시 표시가 있고,
backtrace 로 찍어 보았다. 잘 보면 스택부분에 크게 의심될만한 호출은 없는 것 같다.
한가지 있다면 backlog 부분과 page_fault ... 약간 의심이 가기 시작한다.
... 중략 ...
rlim = {{
rlim_cur = 4294967295,
rlim_max = 4294967295
.... 생략 ...
task 를 찍어보았더니 너무 길다. 저번과 같이 deadbeef 같은 번지수는 찾아지지 않았다.
다만 rlim 값이 current 와 max 가 동일한 듯한 느낌이 든다.
잘모르겠는데 타이머를 한번 찍어보았다.
역시 대략 특이한 점은 찾을 수 없었다.
bt 로 나왔던 몇몇 주소들을 dis 명령으로 disassembler 해본다.
딱히 이상해 보이는 어셈부분은 없었다.
이번 사례는 아직 에스컬레이션 진행중이고 답은 아직 멀었지만 R 모사의 분석이 나오기 전에
케이스 연습삼아 작성 해 보았다.
일단 내가 예상하는 원인으로는 일단 selinux 가 동작중이며,
nodemon 이라는 녀석이 selinux 로 인해 네트워크쪽 오버헤드를 일으키는 부분이 있는 것 같고,
그로 인한 백로그 상승등이 시스템 Hang Up 상황을 만들지 않았을까 하는데,
어플리케이션의 버그 일수도 있지 않나 싶다.
일단 어떤 해결안에 대한 권고를 해야한다면 selinux 를 꺼보시고 커널파라메터튜닝등을 통해
백로그를 조금 더 잡아주는 것을 권고 해 봐야 겠지...
레드햇 답변 나오면 확인해봐야겠다.. 이렇게 커널분석부분도 케이스를 모아놓으면 도움이 되지 않을까 한다.
-> 레드햇 답변으로는 버그질라 477202 와 동일상황으로 보았다. ( net_rx_action 함수의 race condition 버그 )
즉 커널 업데이트를 권고하는데 4.8 이상으로 음....EIP 에서 나온 함수를 버그질라에서 검색한건가 보네...
미처 생각 못했던 건데....아무튼 대단하긴 하다 ㅡ,.ㅡ::
이번 엔드유저는 다른 엔드유저. 64G, 64비트 환경의 오라클 디비 서버란다.
한달사이에 세번이나 연속되서 리부팅이 이루어 졌다.
시스템 (OS) : RedHat Enterprise Linux 5 Server update 3
Kernel Ver. : 2.6.18-128.ELsmp
Machine : x86_64
Memory : 64G
KERNEL: /usr/lib/debug/lib/modules/2.6.18-128.el5/vmlinux
DUMPFILE: vmcore
CPUS: 24
DATE: Thu Dec 10 22:26:28 2009
UPTIME: 34 days, 09:18:38
LOAD AVERAGE: 0.18, 0.12, 0.03
TASKS: 476
NODENAME: *******
RELEASE: 2.6.18-128.el5
VERSION: #1 SMP Wed Dec 17 11:41:38 EST 2008
MACHINE: x86_64 (2665 Mhz)
MEMORY: 63.1 GB
PANIC: ""
PID: 29298
COMMAND: "oracle"
TASK: ffff8110760ea040 [THREAD_INFO: ffff810f2965a000]
CPU: 0
STATE: TASK_RUNNING (PANIC)
더럽게 길다. 게다가 자꾸 I/O 및 파일시스템 관련 시스템콜만 더럽게 불러대끼고 있으며,
우리가 원하는 EIP 등은 눈을 씻고 찾아봐도 나오질 않는다.
그렇다 이건 64비트..확장된 레지스터를 사용하기 때문에 기존 E 자들은 R 자로 변경되었다 (쉽게쉽게~)
자 RIP 가 보인다. 보면 page_writeback 시스템콜등 디스크에 기록하는 부분들에서 멈춰댔다.
실제 이 것들만 보면 리부팅의 원인은 페이지 기록 즉 디스크에 기록하는 작업에서 문제가 발생한것으로
생각할 수 있다. 로그를 보자.
usb-storage: device scan complete
usb 1-7: USB disconnect, address 4
----------- [cut here ] --------- [please bite here ] ---------
Kernel BUG at mm/filemap.c:568
invalid opcode: 0000 [1] SMP
last sysfs file: /devices/pci0000:00/0000:00:1c.0/resource
CPU 0
Modules linked in: vfat fat usb_storage iptable_mangle iptable_nat ip_nat ip_con
ntrack nfnetlink iptable_filter ip_tables x_tables ipv6 xfrm_nalgo crypto_api au
tofs4 sunrpc ib_iser rdma_cm ib_cm iw_cm ib_sa ib_mad ib_core ib_addr iscsi_tcp
libiscsi scsi_transport_iscsi dm_mirror dm_round_robin dm_multipath scsi_dh vide
o hwmon backlight sbs i2c_ec i2c_core button battery asus_acpi acpi_memhotplug a
c parport_pc lp parport joydev sg shpchp ide_cd cdrom e1000e bnx2 pcspkr dm_raid
45 dm_message dm_region_hash dm_log dm_mod dm_mem_cache lpfc scsi_transport_fc a
ta_piix libata megaraid_sas sd_mod scsi_mod ext3 jbd uhci_hcd ohci_hcd ehci_hcd
Pid: 29298, comm: oracle Not tainted 2.6.18-128.el5 #1
RIP: 0010:[<ffffffff80039b4c>] [<ffffffff80039b4c>] end_page_writeback+0x24/0x4
7
RSP: 0018:ffffffff80425c40 EFLAGS: 00010246
RAX: 0000000000000000 RBX: ffff8101393e8690 RCX: 0000000000000034
RDX: ffff81105b1d02b0 RSI: 0000000000000286 RDI: ffff81105fa99868
RBP: ffff81105b1d02b0 R08: ffff8108120495b0 R09: ffff81107ef0b000
R10: ffff810743c7f540 R11: ffffffff800419ac R12: 0000000000000202
R13: ffff8101393e8690 R14: 00000001b11317db R15: 0000000000003000
FS: 00002b24e5219c40(0000) GS:ffffffff803ac000(0000) knlGS:0000000000000000
CS: 0010 DS: 0000 ES: 0000 CR0: 000000008005003b
CR2: 0000000071009fac CR3: 0000000f29821000 CR4: 00000000000006e0
Process oracle (pid: 29298, threadinfo ffff810f2965a000, task ffff8110760ea040)
Stack: ffff81105b1d02b0 ffffffff80045431 ffff810743c7f340 0000000000000246
0000000000000001 ffff810743c7f340 ffff810743c7f340 ffff8107343965c0
ffff810752d02ec0 0000000000000001 0000000000000001 ffffffff800419db
Call Trace:
<IRQ> [<ffffffff80045431>] end_buffer_async_write+0xff/0x126
[<ffffffff800419db>] end_bio_bh_io_sync+0x2f/0x3b
[<ffffffff88182386>] :dm_mod:dec_pending+0x170/0x194
[<ffffffff8818255a>] :dm_mod:clone_endio+0x97/0xc5
[<ffffffff88182386>] :dm_mod:dec_pending+0x170/0x194
[<ffffffff8818255a>] :dm_mod:clone_endio+0x97/0xc5
[<ffffffff88182386>] :dm_mod:dec_pending+0x170/0x194
[<ffffffff8818255a>] :dm_mod:clone_endio+0x97/0xc5
[<ffffffff8002ca64>] __end_that_request_first+0x265/0x5df
[<ffffffff8005bd2f>] blk_run_queue+0x28/0x72
[<ffffffff88079fb4>] :scsi_mod:scsi_end_request+0x27/0xcd
[<ffffffff8807a1a8>] :scsi_mod:scsi_io_completion+0x14e/0x324
[<ffffffff880a67cd>] :sd_mod:sd_rw_intr+0x21d/0x257
[<ffffffff88125117>] :lpfc:lpfc_intr_handler+0x53d/0x580
[<ffffffff8807a43d>] :scsi_mod:scsi_device_unbusy+0x67/0x81
[<ffffffff800376ff>] blk_done_softirq+0x5f/0x6d
[<ffffffff80011fbc>] __do_softirq+0x89/0x133
[<ffffffff8005e2fc>] call_softirq+0x1c/0x28
[<ffffffff8006cada>] do_softirq+0x2c/0x85
[<ffffffff8006c962>] do_IRQ+0xec/0xf5
[<ffffffff8005d615>] ret_from_intr+0x0/0xa
<EOI> [<ffffffff80146083>] cfq_latter_request+0x0/0x1d
[<ffffffff88183d5b>] :dm_mod:dm_table_put+0x14/0xc5
[<ffffffff8818394c>] :dm_mod:dm_request+0x115/0x124
[<ffffffff8001bd3d>] generic_make_request+0x1d2/0x1e9
[<ffffffff88182465>] :dm_mod:__map_bio+0xbb/0x119
[<ffffffff88182f3c>] :dm_mod:__split_bio+0x188/0x3be
[<ffffffff8818394c>] :dm_mod:dm_request+0x115/0x124
[<ffffffff8001bd3d>] generic_make_request+0x1d2/0x1e9
[<ffffffff80022ba3>] mempool_alloc+0x31/0xe7
[<ffffffff80032e58>] submit_bio+0xcd/0xd4
[<ffffffff8001a357>] submit_bh+0xf1/0x111
[<ffffffff8001bf4a>] __block_write_full_page+0x1f6/0x301
[<ffffffff8804eca5>] :ext3:ext3_get_block+0x0/0xf9
[<ffffffff88050457>] :ext3:ext3_ordered_writepage+0xf1/0x198
[<ffffffff8001cab3>] mpage_writepages+0x1ab/0x34d
[<ffffffff88050366>] :ext3:ext3_ordered_writepage+0x0/0x198
[<ffffffff8005a795>] do_writepages+0x29/0x2f
[<ffffffff8004f4f0>] __filemap_fdatawrite_range+0x50/0x5b
[<ffffffff800c29b8>] sync_page_range+0x3d/0xa1
[<ffffffff8002117e>] generic_file_aio_write+0xa6/0xc1
[<ffffffff8804c18e>] :ext3:ext3_file_write+0x16/0x91
[<ffffffff80017d2d>] do_sync_write+0xc7/0x104
[<ffffffff8009db21>] autoremove_wake_function+0x0/0x2e
[<ffffffff80063097>] thread_return+0x62/0xfe
[<ffffffff8001659e>] vfs_write+0xce/0x174
[<ffffffff80043876>] sys_pwrite64+0x50/0x70
[<ffffffff8005d116>] system_call+0x7e/0x83
Code: 0f 0b 68 af b7 29 80 c2 38 02 48 89 df e8 f1 0b fe ff 48 89
RIP [<ffffffff80039b4c>] end_page_writeback+0x24/0x47
RSP <ffffffff80425c40>
crash>
다 생략하고 끝에 컷 히얼~ 여기만 붙혔다.
역시나 end_page_writeback 즉 page 기록 중에 생긴 문제란다.
결국 dm 사용이 되고 있는지, 벤더 제공 디스크관련 모듈을 사용하고 있지 않은지 확인해 봐야 겠다.
crash> mod
MODULE NAME SIZE OBJECT FILE
ffffffff88007e80 ehci_hcd 65741 (not loaded) [CONFIG_KALLSYMS]
ffffffff88017800 ohci_hcd 55925 (not loaded) [CONFIG_KALLSYMS]
ffffffff88026e00 uhci_hcd 57433 (not loaded) [CONFIG_KALLSYMS]
ffffffff8803fd80 jbd 94257 (not loaded) [CONFIG_KALLSYMS]
ffffffff8806ae00 ext3 168017 (not loaded) [CONFIG_KALLSYMS]
ffffffff8809ca80 scsi_mod 196569 (not loaded) [CONFIG_KALLSYMS]
ffffffff880aba00 sd_mod 56385 (not loaded) [CONFIG_KALLSYMS]
ffffffff880bc880 megaraid_sas 72445 (not loaded) [CONFIG_KALLSYMS]
ffffffff880f2c80 libata 208721 (not loaded) [CONFIG_KALLSYMS]
ffffffff88101c00 ata_piix 56901 (not loaded) [CONFIG_KALLSYMS]
ffffffff88114e00 scsi_transport_fc 73801 (not loaded) [CONFIG_KALLSYMS]
ffffffff8816ce00 lpfc 352909 (not loaded) [CONFIG_KALLSYMS]
ffffffff88178600 dm_mem_cache 38977 (not loaded) [CONFIG_KALLSYMS]
ffffffff88191d80 dm_mod 100369 (not loaded) [CONFIG_KALLSYMS]
ffffffff8819ed00 dm_log 44865 (not loaded) [CONFIG_KALLSYMS]
ffffffff881ab200 dm_region_hash 46145 (not loaded) [CONFIG_KALLSYMS]
ffffffff881b5b00 dm_message 36161 (not loaded) [CONFIG_KALLSYMS]
ffffffff881cf080 dm_raid45 99025 (not loaded) [CONFIG_KALLSYMS]
ffffffff881d9b80 pcspkr 36289 (not loaded) [CONFIG_KALLSYMS]
ffffffff8820e300 bnx2 210249 (not loaded) [CONFIG_KALLSYMS]
ffffffff8821a900 joydev 43969 (not loaded) [CONFIG_KALLSYMS]
ffffffff88242700 e1000e 145809 (not loaded) [CONFIG_KALLSYMS]
ffffffff88256600 cdrom 68713 (not loaded) [CONFIG_KALLSYMS]
ffffffff88269a00 ide_cd 73825 (not loaded) [CONFIG_KALLSYMS]
ffffffff8827d200 shpchp 70765 (not loaded) [CONFIG_KALLSYMS]
ffffffff8828ff00 sg 69993 (not loaded) [CONFIG_KALLSYMS]
ffffffff882a3b00 parport 73165 (not loaded) [CONFIG_KALLSYMS]
ffffffff882b0080 lp 47121 (not loaded) [CONFIG_KALLSYMS]
ffffffff882c1000 parport_pc 62312 (not loaded) [CONFIG_KALLSYMS]
ffffffff882cc500 ac 38729 (not loaded) [CONFIG_KALLSYMS]
ffffffff882d7a80 acpi_memhotplug 40133 (not loaded) [CONFIG_KALLSYMS]
ffffffff882e5480 asus_acpi 50917 (not loaded) [CONFIG_KALLSYMS]
ffffffff882f1900 battery 43849 (not loaded) [CONFIG_KALLSYMS]
ffffffff882fcc00 button 40545 (not loaded) [CONFIG_KALLSYMS]
ffffffff8830b900 i2c_core 56129 (not loaded) [CONFIG_KALLSYMS]
ffffffff88316480 i2c_ec 38593 (not loaded) [CONFIG_KALLSYMS]
ffffffff88324080 sbs 49921 (not loaded) [CONFIG_KALLSYMS]
ffffffff8832f980 backlight 39873 (not loaded) [CONFIG_KALLSYMS]
ffffffff88339c80 hwmon 36553 (not loaded) [CONFIG_KALLSYMS]
ffffffff88347d80 video 53197 (not loaded) [CONFIG_KALLSYMS]
ffffffff88353080 scsi_dh 41665 (not loaded) [CONFIG_KALLSYMS]
ffffffff88362580 dm_multipath 55257 (not loaded) [CONFIG_KALLSYMS]
ffffffff8836cd80 dm_round_robin 36801 (not loaded) [CONFIG_KALLSYMS]
ffffffff8837ad80 dm_mirror 53193 (not loaded) [CONFIG_KALLSYMS]
ffffffff8838c400 scsi_transport_iscsi 67153 (not loaded) [CONFIG_KALLSYMS]
ffffffff8839d600 libiscsi 63553 (not loaded) [CONFIG_KALLSYMS]
ffffffff883ad200 iscsi_tcp 58433 (not loaded) [CONFIG_KALLSYMS]
ffffffff883b9180 ib_addr 41929 (not loaded) [CONFIG_KALLSYMS]
ffffffff883d1b80 ib_core 93637 (not loaded) [CONFIG_KALLSYMS]
ffffffff883e4180 ib_mad 70629 (not loaded) [CONFIG_KALLSYMS]
ffffffff883f7f80 ib_sa 74441 (not loaded) [CONFIG_KALLSYMS]
ffffffff88404780 iw_cm 43465 (not loaded) [CONFIG_KALLSYMS]
ffffffff88416400 ib_cm 67305 (not loaded) [CONFIG_KALLSYMS]
ffffffff88428380 rdma_cm 67157 (not loaded) [CONFIG_KALLSYMS]
ffffffff8843a280 ib_iser 66873 (not loaded) [CONFIG_KALLSYMS]
ffffffff88468800 sunrpc 197897 (not loaded) [CONFIG_KALLSYMS]
ffffffff8847bc80 autofs4 57033 (not loaded) [CONFIG_KALLSYMS]
ffffffff88487580 crypto_api 42945 (not loaded) [CONFIG_KALLSYMS]
ffffffff88493700 xfrm_nalgo 43333 (not loaded) [CONFIG_KALLSYMS]
ffffffff884f9f80 ipv6 424609 (not loaded) [CONFIG_KALLSYMS]
ffffffff8850a280 x_tables 50377 (not loaded) [CONFIG_KALLSYMS]
ffffffff88518d80 ip_tables 55329 (not loaded) [CONFIG_KALLSYMS]
ffffffff88523b00 iptable_filter 36161 (not loaded) [CONFIG_KALLSYMS]
ffffffff8852eb80 nfnetlink 40457 (not loaded) [CONFIG_KALLSYMS]
ffffffff88545800 ip_conntrack 91109 (not loaded) [CONFIG_KALLSYMS]
ffffffff88554400 ip_nat 52845 (not loaded) [CONFIG_KALLSYMS]
ffffffff8855fd00 iptable_nat 40773 (not loaded) [CONFIG_KALLSYMS]
ffffffff88569a80 iptable_mangle 36033 (not loaded) [CONFIG_KALLSYMS]
ffffffff88587100 usb_storage 116641 (not loaded) [CONFIG_KALLSYMS]
ffffffff8859dd00 fat 85873 (not loaded) [CONFIG_KALLSYMS]
ffffffff885aa300 vfat 46401 (not loaded) [CONFIG_KALLSYMS]
crash>
그래. 멀티패스 사용한다. HP 스토리지이며 lpfc 모듈이 올라가 있다.
자 lpfc 모듈등을 점검해 보자고 하자.
sosreport 에서 보여지는 module 정보에선 lpfc의 버젼은 8.2.0.33.3p 로 나온다.
이 모듈의 버그 혹은 업데이트 버젼이 있는지 확인해 보라고 해야한다.
일단 디스크가 떨어지는 버그는 버그질라에 보고되고 있다.
( https://bugzilla.redhat.com/show_bug.cgi?id=470610 )
그런데 큰일이 생겼다.
한참 분석중인상태에서 다시 리부팅이 이루어졌다.
보여진 메시지는 다음과 같다고 한다.
Dec 15 11:38:22 udb kernel: Bad page state in process 'oracle'
Dec 15 11:38:22 udb kernel: page:ffff810126fed270 flags:0x0b20100000000008 mapping:ffff811038016598 mapcount:0 count:0 (Tainted: G B)
Dec 15 11:38:22 udb kernel: Trying to fix it up, but a reboot is needed
Dec 15 11:38:22 udb kernel: Backtrace:
Dec 15 11:38:22 udb kernel:
Dec 15 11:38:22 udb kernel: Call Trace:
Dec 15 11:38:22 udb kernel: [<ffffffff800c4570>] bad_page+0x69/0x91
Dec 15 11:38:22 udb kernel: [<ffffffff8000a76a>] get_page_from_freelist+0x262/0x3fa
Dec 15 11:38:22 udb kernel: [<ffffffff8000f10b>] __alloc_pages+0x65/0x2ce
Dec 15 11:38:22 udb kernel: [<ffffffff80010e8c>] do_wp_page+0x2fa/0x6b5
Dec 15 11:38:22 udb kernel: [<ffffffff80009406>] __handle_mm_fault+0xd9b/0xe5c
Dec 15 11:38:22 udb kernel: [<ffffffff80066b9a>] do_page_fault+0x4cb/0x830
Dec 15 11:38:22 udb kernel: [<ffffffff8001c8db>] vma_link+0xd0/0xfd
Dec 15 11:38:22 udb kernel: [<ffffffff8000de64>] do_mmap_pgoff+0x66c/0x7d7
Dec 15 11:38:22 udb kernel: [<ffffffff8002fd5e>] __up_write+0x27/0xf2
Dec 15 11:38:22 udb kernel: [<ffffffff8005dde9>] error_exit+0x0/0x84
Dec 15 11:38:22 udb kernel:
Dec 15 11:38:22 udb kernel: Bad page state in process 'oracle'
Dec 15 11:38:22 udb kernel: page:ffff810126fed2a8 flags:0x0b2010000000002c mapping:0000000000000000 mapcount:0 count:1 (Tainted: G B)
Dec 15 11:38:22 udb kernel: Trying to fix it up, but a reboot is needed
Dec 15 11:38:22 udb kernel: Backtrace:
Dec 15 11:38:22 udb kernel:
Dec 15 11:38:22 udb kernel: Call Trace:
Dec 15 11:38:22 udb kernel: [<ffffffff800c4570>] bad_page+0x69/0x91
Dec 15 11:38:22 udb kernel: [<ffffffff8000a76a>] get_page_from_freelist+0x262/0x3fa
Dec 15 11:38:22 udb kernel: [<ffffffff8000f10b>] __alloc_pages+0x65/0x2ce
Dec 15 11:38:22 udb kernel: [<ffffffff80010e8c>] do_wp_page+0x2fa/0x6b5
Dec 15 11:38:22 udb kernel: [<ffffffff80009406>] __handle_mm_fault+0xd9b/0xe5c
Dec 15 11:38:22 udb kernel: [<ffffffff80066b9a>] do_page_fault+0x4cb/0x830
Dec 15 11:38:22 udb kernel: [<ffffffff8001c8db>] vma_link+0xd0/0xfd
Dec 15 11:38:22 udb kernel: [<ffffffff8000de64>] do_mmap_pgoff+0x66c/0x7d7
Dec 15 11:38:23 udb kernel: [<ffffffff8002fd5e>] __up_write+0x27/0xf2
Dec 15 11:38:23 udb kernel: [<ffffffff8005dde9>] error_exit+0x0/0x84
멋지다. 커널 개발자들도 눈을 씻고 봐야 한다는 Bad Page state 라는 에러가 보인다.
커널 개발의 수많은 부분중 메모리 관련된 mm 을 패칭하는 mm guy 들은 꼼꼼하기로 소문이 자자한데,
가장 많이 신경 쓰는 것이 Bad Page 부분이다.
lkml.org 를 보면 리누즈와 Gene 이란 사람의 bad page 관련 주고받는 내용이 있다.
( http://lkml.org/lkml/2009/8/1/66 http://lkml.org/lkml/2009/8/2/300 )
거기서 리누즈는 몇번의 테스트 요청 끝에 커널 버그가 아니라고 선언했다.
왜냐면 항상 동일 메모리 번지에 문제가 생겼기 때문이다. 그는 메모리 테스트를 해야하고,
Gene 은 메모리 테스트를 통해 메모리 문제를 확인 하였다. 이부분에 대한 메일링리스트도 있었던걸로
기억하는데 지금 찾아보니 없다. 8월 25일경이였는데.......
어쨋든 이 메시지를 받은 순간 고민하였으나,
바로 오늘만 다시 저 메시지와함께 세번의 리부팅이 있었다.
역시 거기서 나오는 Page 주소는 page:ffff810126fed270.
처음 호출시 tainted 라고 뿌려지며 오늘 보내준 메시지 역시 다음과 같다.
oracle@udb.kpetro.or.kr:/oracle>
Message from syslogd@ at Thu Dec 17 16:00:55 2009 ...
udb kernel: Bad page state in process 'tar'
Message from syslogd@ at Thu Dec 17 16:00:56 2009 ...
udb kernel: page:ffff810137c95e70 flags:0x0ff0100000000008 mapping:ffff81104fedc850 mapcount:0 count:0 (Not tainted)
Message from syslogd@ at Thu Dec 17 16:00:58 2009 ...
udb kernel: Trying to fix it up, but a reboot is needed
Message from syslogd@ at Thu Dec 17 16:01:00 2009 ...
udb kernel: Backtrace:
Message from syslogd@ at Thu Dec 17 16:01:01 2009 ...
udb kernel: Bad page state in process 'tar'
Message from syslogd@ at Thu Dec 17 16:01:01 2009 ...
udb kernel: page:ffff810137c95ea8 flags:0x0ff010000000082c mapping:0000000000000000 mapcount:0 count:2 (Tainted: G B)
Message from syslogd@ at Thu Dec 17 16:01:01 2009 ...
udb kernel: Trying to fix it up, but a reboot is needed
Message from syslogd@ at Thu Dec 17 16:01:01 2009 ...
udb kernel: Backtrace:
잘 봐라 역시 동일한 주소며 첫번째는 Tainted 가 없었지만 같은 buddy 에 있는 38번째 비트의 메모리번지에서
tainted 가 표시되고 있다.
이 경우는 분명히 메모리의 물리적 오류가 있다는 것을 알 수 있었다.
하지만 역시 Core 분석시 보여주던 부분도 있기 때문에 일단 memtest 를 해보고,
lpfc 관련 드라이버역시 최신 업데이트를 확인해 보라고 하였다.
디스크쪽과 메모리쪽의 중복된 문제들이 발견된 이상 하드웨어의 전반적인 점검또한 고객에게 권고 할 수 있을 것이다.
원래 처음엔 코어분석을 먼저 하지 않고 상기 Bad page 관련 메시지만 보았고,
백프로 메모리 테스트를 장담하였는데, Redhat 사의 커널 분석엔지니어역시 메모리 테스트를 동일하게 권고하였다.
VMware 에 올라가 있는 RHEL 4.7 Oracle Was 서버이다.
오전에 갑작스러운 셧다운이 일어났고, 덤프를 떴으나 덤프는 incompletement 라는 메시지와 함께
정상적으로 떨어지지 않았다.
이번엔 이럴 경우에 대해서 살펴 보기로 한다.
시스템 (OS) : RedHat Enterprise Linux 4 AS update 7
Kernel Ver. : 2.6.9-78.ELsmp
Machine : i686
Memory : 6G
일단 VMware 상에서의 넷덤프 및 디스크 덤프는 약간 정상적으로 작동하지 못하는 것 같다.
이 경우엔 Crash 툴을 통한 접근이 어렵다.
하지만 포기하지 말자. incompletement 코어를 가지고도 할 수 있는 일이 있으니,
그것은 바로 크래쉬 로그 뽑기이다.
strings 를 통해 문자열들을 뽑아보면 커널 크래쉬 로그가 남는다.
# ] strings vmcore-incomplement > core_strings
7.1G 정도 쌓여있던 코어파일에서 약 260메가 정도 되는 파일이 생성되었다.
이제 이 스트링파일을 열어보자. 이 용량역시 엄청나 VI 로 열기 버거울 수 도 있겠지만
어쩌겠냐...열어봐야지
앞에 막 들어가있는 가비지문자들은 전부버리자. 아마 케이스마다 다르겠지만,
난 앞의 약 5만줄을 날렸더니 그럭저럭 다음과 같은 볼만한 문자가 보이더라.
cpu_mask_to_apicid
cpu_mask_to_apicid
smp_call_function
wakeup_secondary_cpu
check_nmi_watchdog
timer_irq_works
unlock_ExtINT_logic
follow_hugetlb_page
load_balance
context_switch
interruptible_sleep_on
interruptible_sleep_on_timeout
sleep_on_timeout
migration_thread
__put_task_struct
자 좀 더 내리면 중간에 역시 마치 binary 스트링 뽑아냈을때 처럼 printf 포맷스트링들이 즐비해 있다.
다 무시하고 쭈~~~욱 내려가다보면 다음과 같은 눈에 확 들어오게 되는 문자열이 보이게 된다.
-------------[ cut here ]------------
많이 보던 문자 아닌가?
그렇다. crash 툴에서 찍어보던 log 를 나타내주는 문자열이였다.
자 이제 이 문자열을 검색해보자.
:/cut here
<4>------------[ cut here ]------------
<1>kernel BUG at kernel/exit.c:904!
<1>invalid operand: 0000 [#1]
<4>SMP
<4>Modules linked in: loop seos(U) eAC_mini(U) md5 ipv6 i2c_dev i2c_core vsock(U) vmmemctl(U) pvscsi(U) sunrpc cpufreq_powersave ide_dump scsi_dump diskdump zlib_deflate dm_mirror dm_mod button battery ac vmci(U) acpiphp pcnet32 mii floppy vmxnet(U) ext3 jbd ata_piix libata mptscsih mptsas mptspi mptscsi mptbase sd_mod scsi_mod
<4>CPU: 0
<4>EIP: 0060:[<c0124cc5>] Tainted: P VLI
<4>EFLAGS: 00010046 (2.6.9-78.ELsmp)
<4>EIP is at next_thread+0xc/0x3f
<4>eax: 00000000 ebx: ca340db0 ecx: 00717ff4 edx: dd4378f0
<4>esi: 000080aa edi: 00008551 ebp: b3a5c198 esp: e03d9f8c
<4>ds: 007b es: 007b ss: 0068
<4>Process emagent (pid: 27221, threadinfo=e03d9000 task=ca340db0)
<4>Stack: c012f536 00000246 00000000 b3a5c174 00000000 e03d9fa8 00000000 00000000
<4> c01265f5 b3a5c198 b7f98c34 b3a5c200 e03d9000 c02e09db b3a5c198 00717ff4
<4> b7f98c34 b7f98c34 b3a5c200 b3a5c1a8 0000002b c02e007b 0000007b 0000002b
위대한 탐험가들이여. 보이는가? 마치 crash 를 실행시켜 bt 나 log 를 찍었을 때와 동일한
EIP 와 콜 트레이스 및 스택의 위용이 느껴지는가?
emagent 프로세스에서 걸리는 저 문제는 명백히 예전에 있던 이슈였고,
Oracle 측에서 2.6.9-78.0.22 커널로 올리는것을 권고했었던 적이 있는 사이트였다.
업무담당자는 emagent 가 안올라갔다고 했었으나, sysreport 와 코어 스트링, 그리고
재부팅된 서버에 접속하여 확인 해 본 결과로는 emagent 가 떡! 하니 돌아가고 있었다.
녀석의 야욕을 빠르게 읽어내어 승자의 미소를 띄우며 담당자에게 보고가 가능했고,
담당자는 크게 만족하며 고개를 끄덕였다.
깨진 코어파일을 R사에 보내봤자, 완벽한 파일만 요구받을 뿐이라는 교훈을 명심하기 바란다.
이번엔 매우 난감한 경우였다. 무려 한달이 넘도록 길게 끌어오던 이슈였으니까...
역시 VMware 에 올라가 있는 서버이며, WAS + Java APP 가 돌아가는 시스템이다.
OS 는 올 10월 EOS 가 되는 RHEL3 이다.
이슈는 원래 Hugemem 에 작동 되던 시스템을 VMware 지원 문제로 인하여 SMP 로 돌린다는것... ( Ram 16G )
자. 일단 살펴보자
.
시스템 (OS) : RedHat Enterprise Linux 3 AS update 6 ( 커널은 3.9 커널 )
Kernel Ver. : 2.6.21-50.ELsmp
Machine : i686
Memory : 16G
문제는 실제 장애상황에서도 좀체로 덤프를 뜰수가 없었던 상황이였다.
결국 다시 장애상황 발생하여 sysrq 로 덤프를 떴다. 자 중요하다 sysrq 다
RHEL 3버젼의 경우 다음과 같이 crash 실행을 해야 한다.
STAE 를 보면 재밌게도 TASK_RUNNING (SYSRQ) 라고 써져 있는 것을 볼 수 있다.
시스템 행업상태는 아니지만 SYSRQ 로 덤프를 떴다는 의미이다.
늘 R 사에서 하듯 log 부터 찍어보자.
오옹... 여기 경고가 떡 하니 뜬다. Hugemem 을 권장하라는 얘기이다.
16기가라고 했는데, 실상 보니 약간 더 넘게 설정되어 있어 17G 로 인식한다 서버에서는...
자 재밌게 netdump 동작한 부분까지 나온다. crond 에서 걸려있다.
bt 를 걸어봐 봤자 crond 에 대한 것만 나올테니 이번엔 대체 왜 문제가 생겼는지 부터 보자.
핵심은 행업상태인줄 알고 있었다는것 ( 서버 무반응 ). 일단 프로세스부터 보자.
뭐 TASK 가 1600개 넘어가니 짜증이 난다. 대략 kscand 와 kswapd 가 보인다.
음... 이건 뭐 메모리부족인가? 하여 결국 bt 를 찍어보기로 한다. 여기서는 crond 에 걸려 그것만 나오기때문에,
foreach bt 를 사용하여 전체를 잘 살펴봐야 한다. ( 눈빠진다..하지만 걱정마라 금방 원인이 추정되어 나온다. )
커널 프로세스 위주로 Backtrace 해봤다. swapper 가 동작하는것 외에 특별한 스택을 볼순 없었다.
다시 이제 user 영역을 찍어보자
자 전반적으로다가 의심스러운 스택들이 튀어나와있다.
#0 [df775c18] schedule at c0124280
#1 [df775c5c] schedule_timeout at c01356f0
#2 [df775c94] wait_on_page_timeout at c0149545
#3 [df775cf0] rebalance_laundry_zone at c0156db5
#4 [df775d24] __alloc_pages at c015a119
#5 [df775d6c] __get_free_pages at c015a267
#6 [df775d70] kmem_cache_grow at c0152cc4
#7 [df775d98] __kmem_cache_alloc at c0153b2a
바로 위의 것들인데, 왜 의심스러운거냐 하면, 바로 메모리 관련하여 작업을 하고 있다는 것이기 때문이다.
전반적으로 많은 프로세스들에 rebalance_laundry_zone 과 kmem_cache_grow 등이 보이는데
이것들이 하는것은 메모리 사용량이 많아, 할당 가능한 메모리가 존재 하는지 안하는지 확인하는 것들이다.
결과적으로 전반적인 메모리 부족을 뜻하는 것인데, 할당 가능한 page 가 있는지 없는지 살펴보는 과정에서
wait_on_page_timeout 이 발생하여 page 를 기다리고, schedule_timeout 이 되어 프로세스가 계속
대기하게 되는 것이다.
이것이 장애와 어떤 연관이 있냐 하면, RHEL 3 의 경우 2.4 커널을 사용하며, 2.4 커널에서는
기본적으로 budy 알고리즘 만을 사용하도록 되어 있다. ( 알고리즘 설명은 따로 LDP 에서 뒤져봐라 )
이것은 연속된 특정 page 영역을 계속 찾고 검색하게 되있고. 이것은 곧 오버헤드를 발생시키는 것이 된다.
즉 위 상황에서 OS ( 커널 ) 는 메모리 할당을 위해 재사용할 메모리를 검색하는데 집중하느라 외부에서는
Hang-up 상태로 의심할만한 반응이 없는 상태가 되는것이다.
좀 더 찾아보니 다음과 같은 것도 있었다.
결국 위 httpd 프로세스는 메모리 확보를 하는 과정에 빠져있었다는 것인데,
아니 왜 이렇게 메모리를 많이써? 왜 할당을 안해? 스왑은 뭐한데? 라고 할수 있으므로 다시 좀 더 보자.
다음은 kmem 을 통해 메모리 정보들을 확인 해 보는 것이다. -f 는 프리 page 갯수를 나타낸다.
신기한가? 멀었다. 잘 보면 DMA 영역으로 16메가가 할당되어 있고,
Normal 즉 lowmem table ( kernel 영역 ) 에 4k 짜리 페이지 외에 다른 크기의 메모리 block 들은
하나도 존재하지 않은 상태다. 즉 다 할당해 주고 더이상 연속된 8k 이상 페이지를 갖고 있지 않다는 얘기이다.
자 SLAB 영역이 무려 364메가 이상이고, LOW 영역이 고작 539 정도에 51메가밖에 남아있지 않는다.
결과적으로 LOW 멤에서 메모리 관련 작업은 불가능한 상태라는 것이다.
자 그래, 그럼 SLAB 갯수가 얼마나 되는지 확인해 보자.
crash> kmem -s> slab.txt
CACHE NAME OBJSIZE ALLOCATED TOTAL SLABS SSIZE
c03ab900 kmem_cache 244 74 96 6 4k
f7592914 nfs_write_data 384 0 0 0 4k
f7592a08 nfs_read_data 384 0 0 0 4k
f7592afc nfs_page 128 0 0 0 4k
f7592bf0 ip_fib_hash 32 10 336 3 4k
d8982ce4 ext3_xattr 44 0 0 0 4k
f7592ce4 journal_head 48 196 22869 297 4k
f7592dd8 revoke_table 12 11 500 2 4k
f7592ecc revoke_record 32 0 1792 16 4k
d8982dd8 clip_arp_cache 256 0 0 0 4k
d8982ecc ip_mrt_cache 128 0 0 0 4k
d8a0b080 tcp_tw_bucket 128 0 25380 846 4k
d8a0b174 tcp_bind_bucket 32 627 2800 25 4k
d8a0b268 tcp_open_request 128 303 3150 105 4k
d8a0b35c inet_peer_cache 64 4 116 2 4k
d8a0b450 secpath_cache 128 0 0 0 4k
d8a0b544 xfrm_dst_cache 256 0 0 0 4k
d8a0b638 ip_dst_cache 256 252 4350 290 4k
d8a0b72c arp_cache 256 6 435 29 4k
d8a0b820 flow_cache 128 0 0 0 4k
d8a0b914 blkdev_requests 128 3072 4140 138 4k
d8a0ba08 kioctx 128 0 0 0 4k
d8a0bafc kiocb 128 0 0 0 4k
d8a0bbf0 dnotify_cache 20 0 0 0 4k
d8a0bce4 file_lock_cache 96 17 2920 73 4k
뭐, 간단히 SLAB 이란 원래 Solaris 계열에서 나온 정책인데, 쉽게 메모리 할당 후 혹시 쓰일지 모른다는 생각에
바로 폐기하지 않고, 남겨둔다는 것이다.
결국 커널은 동일한 크기의 연속된 메모리 (page) 를 요청하는 경향이 있기 때문에,
잦은 호출을 줄이기 위해 캐쉬 영역에 SLAB 을 둔다는 것이다.
결국 CACHE 에 SLAB 이 많이 존재 하게 되면 ( budy 를 자주 호출하게 되면 ) 직접적인 메모리 엑세스 타임에는
매우 큰 손실을 주게 되는 것이다. ( 캐쉬안에 존제된 연속된 채워진 혹은 비어있는 동일 크기의 페이지이므로 )
다시 한번 SLAB 부분 확인해 보고 결론을 들어가 보자.
[root@localhost root]# grep -E "sock|tcp" slab.txt
d8a0b080 tcp_tw_bucket 128 0 25380 846 4k
d8a0b174 tcp_bind_bucket 32 627 2800 25 4k
d8a0b268 tcp_open_request 128 303 3150 105 4k
d8acfce4 sock 1408 1805 2402 1201 4k
결과적으로 위 장애는 lowmem 의 부족으로 lowmem 영역 확보를 위해 캐쉬되있는 메모리를 검색하고,
반환하며, 또한 새로 할당하기 위해 일련의 과정들을 격는 중이였다는 것이며,
( 그러나 실제 캐쉬에서 사용가능한 부분은 없어 Lowmem 확보에 어려움이 있었던 것으로 판단. )
httpd 및 java 프로세스는 TCP 통신을 하기 때문에 Lowmem 을 많이 사용하였을 것이라는 결론.
특히 .text.lock.vmscan 은 HTTP 에서만 발생하였다.
Hugemem 으로 간다면 모르겠지만 그럴 수 있는 상황이 아니므로 ( VMware not support Hugemem )
즉 위의 문제는 장애가 아닌 튜닝이나 부하분산에 촛점을 맞춰야 한다는 것이다.
아래는 R 사의 답변 요약이다.
실제 Cached 메모리 자체 및 사용량은 12G 에 불과하므로 메모리를 줄이는것이 오히려 메모리 확보과정에
오버헤드를 줄일 수 있다는 내용인데. 큰 의미는 없다고 보여 진다.... ㅡ.,ㅡ::
@ 결론
- 시스템에서 실행 중인 프로세스가 많으며 대부분의 프로세스들이 비슷한 동작 즉,
지속적으로 lowmem을 요구하고 있습니다.
(CPU 4개 중 3개에서 httpd 프로세스가 TCP 통신을 위해 lowmem에서 buffer를 요청하고 있었습니다.)
- 커널에서는 분주히 lowmem 메모리 확보를 위한 작업을 수행하고 있습니다. (lowmem 영역은 swap 될 수 없습니다.)
- 이 때문에 시스템의 반응 속도가 현저히 줄어드는 것(Hang 상태이거나 Crash된 것이 아님)이며,
다시 말하면 시스템이 수용할 수 있는 한계보다 높은 부하로 인해 동작이 원활히 이루어지지 않는 것 입니다.,
- 이는 정상적인 반응이고 Red Hat Enterprise Linux 또는 커널의 문제가 아닙니다.
- 특별한 이슈가 없는 한, 이 이슈는 시스템 문제가 아닌 성능 튜닝이나 부하 관리 차원에서
다뤄져야 할 것으로 판단됩니다.
@ 권고 사항
- 현재 조건에서는 시스템 로드를 줄여주는 방법밖에는 없습니다.
- 현재 시스템 메모리가 17GB으로 보여집니다. 16GB 이하로 줄이시기 바랍니다.
- 현재 상황에서는 16GB는 다 사용하지도 못하고 있으므로, 8GB 또는 12GB 정도로 줄여 lowmem에서
physical memory mapping에 사용되는 공간(mem_map[])을 줄일 수 있을 것으로 생각됩니다.
이미 예전에 한번 CPU timer interrupt 방식 문제로 이슈가 발생 되었던 시스템이다.
문제는 약 6개월만에 또다시 터졌다는건데...
시스템 (OS) : RedHat Enterprise Linux 4 AS update 5 ( 커널은 4.8 커널 )
Kernel Ver. : 2.6.9-89.ELsmp
Machine : x86_64
Memory : 8G
간단하게 코어 바로 열고 log 찍어보았다.
KERNEL: vmlinux-2.6.9-89.ELsmp.x86_64
DUMPFILE: var/crash/127.0.0.1-2010-05-11-09:51/vmcore
CPUS: 8
DATE: Tue May 11 09:51:17 2010
UPTIME: 205 days, 20:36:24
LOAD AVERAGE: 0.22, 0.13, 0.07
TASKS: 342
NODENAME: ******02
RELEASE: 2.6.9-89.ELsmp
VERSION: #1 SMP Mon Apr 20 10:33:05 EDT 2009
MACHINE: x86_64 (3169 Mhz)
MEMORY: 8 GB
PANIC: "Kernel panic - not syncing: nmi watchdog"
PID: 15652
COMMAND: "scopeux"
TASK: 1006b7de7f0 [THREAD_INFO: 1000eef4000]
CPU: 0
STATE: TASK_RUNNING (NMI)
crash >
로그 보자....
crash > log
warning: many lost ticks
Your time source seems to be instable or some driver is hogging interupts
rip __do_softirq+0x4d/0xd0
Falling back to HPET
NMI Watchdog detected LOCKUP, CPU=0, registers:
CPU 0
Modules linked in: snapapi26(U) i2c_dev i2c_core md5 ipv6 ide_dump scsi_dump diskdump zlib_deflate
dm_mirror dm_mod emcpvlumd(U) emcpxcrypt(U) emcpdm(U) emcpgpx(U) emcpmpx(U) emcp(U) button
battery ac ohci_hcd ehci_hcd tg3 e1000 bonding(U) sg ext3 jbd qla2300 aacraid qla2xxx scsi_transport_fc sd_mod scsi_mod
Pid: 15652, comm: scopeux Tainted: P 2.6.9-89.ELsmp
RIP: 0010:[<ffffffff80141400>] <ffffffff80141400>{do_timer+197}
RSP: 0018:ffffffff8046dce0 EFLAGS: 00000012
RAX: 000000000001e7fc RBX: 000000006b1833d6 RCX: 000000000001e7fc
RDX: 0000000000000000 RSI: 00000000000f41a8 RDI: ffffffff8046ddc8
RBP: 0000000072a55f4d R08: 0000000000000008 R09: 0000000000000000
R10: 0000000000000000 R11: 0000000000000008 R12: 00000000d73c7987
R13: 0000000072a55f4b R14: ffffffff8046ddc8 R15: 000000000000c3f0
FS: 0000000000000000(0000) GS:ffffffff80504500(005b) knlGS:00000000f7d7c6c0
CS: 0010 DS: 002b ES: 002b CR0: 0000000080050033
CR2: 00000000f7ad8000 CR3: 0000000000101000 CR4: 00000000000006e0
Process scopeux (pid: 15652, threadinfo 000001000eef4000, task 000001006b7de7f0)
Stack: 00000005241efada 0000000000000000 000000000000037d ffffffff801167ee
ffffffff8046dd60 ffffffff801340e4 0000000000000044 00000004b1799b8e
000000018046ddc8 0000000000000000
Call Trace:<IRQ> <ffffffff801167ee>{timer_interrupt+587} <ffffffff801340e4>{rebalance_tick+133}
<ffffffff80112ff6>{handle_IRQ_event+41} <ffffffff80113270>{do_IRQ+197}
<ffffffff801108c3>{ret_from_intr+0} <ffffffff8013d859>{__do_softirq+77}
<ffffffff8013d90d>{do_softirq+49} <ffffffff80110c85>{apic_timer_interrupt+133}
<EOI> <ffffffff801656ca>{s_show+515} <ffffffff801656ca>{s_show+515}
<ffffffff80199fae>{seq_read+445} <ffffffff8017c2ec>{vfs_read+207}
<ffffffff8017c548>{sys_read+69} <ffffffff801266fc>{sysenter_do_call+27}
Code: 81 e1 ff 0f 00 00 48 c1 f8 0c 48 89 0d 37 0a 36 00 48 01 c6
Kernel panic - not syncing: nmi watchdog
----------- [cut here ] --------- [please bite here ] ---------
Kernel BUG at panic:77
invalid operand: 0000 [1] SMP
CPU 0
Modules linked in: snapapi26(U) i2c_dev i2c_core md5 ipv6 ide_dump scsi_dump diskdump zlib_deflate
dm_mirror dm_mod emcpvlumd(U) emcpxcrypt(U) emcpdm(U) emcpgpx(U) emcpmpx(U) emcp(U) button
battery ac ohci_hcd ehci_hcd tg3 e1000 bonding(U) sg ext3 jbd qla2300 aacraid qla2xxx scsi_transport_fc sd_mod scsi_mod
Pid: 15652, comm: scopeux Tainted: P 2.6.9-89.ELsmp
RIP: 0010:[<ffffffff80138992>] <ffffffff80138992>{panic+211}
RSP: 0018:ffffffff80470ca8 EFLAGS: 00010082
RAX: 000000000000002c RBX: ffffffff803287ce RCX: 0000000000000046
RDX: 00000000000121c3 RSI: 0000000000000046 RDI: ffffffff803f6700
RBP: ffffffff80470e58 R08: 0000000000000002 R09: ffffffff803287ce
R10: 0000000000000000 R11: 0000ffff80411b20 R12: 0000000000000000
R13: 0000000072a55f4b R14: ffffffff8046ddc8 R15: 000000000000c3f0
FS: 0000000000000000(0000) GS:ffffffff80504500(005b) knlGS:00000000f7d7c6c0
CS: 0010 DS: 002b ES: 002b CR0: 0000000080050033
CR2: 00000000f7ad8000 CR3: 0000000000101000 CR4: 00000000000006e0
Process scopeux (pid: 15652, threadinfo 000001000eef4000, task 000001006b7de7f0)
Stack: 0000003000000008 ffffffff80470d88 ffffffff80470cc8 0000000000000013
0000000000000000 0000000000000046 0000000000012197 0000000000000046
0000000000000002 ffffffff8032af27
Call Trace:<ffffffff801118f4>{show_stack+241} <ffffffff80111a1e>{show_registers+277}
<ffffffff80111d25>{die_nmi+130} <ffffffff8011de1b>{nmi_watchdog_tick+276}
<ffffffff801125f6>{default_do_nmi+116} <ffffffff8011df05>{do_nmi+115}
<ffffffff80111203>{paranoid_exit+0} <ffffffff80141400>{do_timer+197}
<EOE> <IRQ> <ffffffff801167ee>{timer_interrupt+587}
<ffffffff801340e4>{rebalance_tick+133} <ffffffff80112ff6>{handle_IRQ_event+41}
<ffffffff80113270>{do_IRQ+197} <ffffffff801108c3>{ret_from_intr+0}
<ffffffff8013d859>{__do_softirq+77} <ffffffff8013d90d>{do_softirq+49}
<ffffffff80110c85>{apic_timer_interrupt+133} <EOI> <ffffffff801656ca>{s_show+515}
<ffffffff801656ca>{s_show+515} <ffffffff80199fae>{seq_read+445}
<ffffffff8017c2ec>{vfs_read+207} <ffffffff8017c548>{sys_read+69}
<ffffffff801266fc>{sysenter_do_call+27}
Code: 0f 0b 4e 8d 32 80 ff ff ff ff 4d 00 31 ff e8 2f bb fe ff 83
RIP <ffffffff80138992>{panic+211} RSP <ffffffff80470ca8>
이번 분석은 여기서 끝난다. 간단하게 로그에 나오듯이 TSC 를 기본 인터럽트 방식으로 사용하고 있는 Linux 에서
정상적으로 CPU time 을 인터럽트 하지 못했을 경우에는 HPET 라는 방식으로 자동 전환하여
CPU time 을 가져오려고 한다.
그런데 여기선 HPET 방식으로의 전환이 불가능 했고, 그로 인해 30초 이상의 CPU time 을 얻어오지 못함으로,
NMI_Watchdog 에서 커널 패닉으로 감지 한 것이다.
@결론
일전에 Redhat 에서 이 이슈가 있었을때 grub.conf 에 clocksource=hpet 을 커맨드라인에 넣어주어,
시작시부터 HPET 타이머를 이용하도록 하라는 권고가 있었고 적용 된 줄 알았었다...
하지만 clocksource 는 RHEL5 에서 적용 가능한 커맨드라인이였고, 보시다시피 이 시스템은 RHEL4
결국 고객에게 죄송하다는 말과 함께 clock=hpet 으로 수정..적용은 아직 안되고 있다 (리부팅해야하므로)
왜 RHEL5 에 적용되는걸 알려줘서 난감하게 만든겁니까~? ㅠㅠ
오랜만인데...SCTP 프로토콜 관련 문제로 이미 예전부터 RedHat 과 함께 공조하여 패치를 만들어오던
상황이다...패치적용된 테스트 커널을 만들어 레드햇에서 고객에 전달해 준 뒤, 사용 후 문제가 생기는지에대한
피드백을 요청하는등 작업이 이루어 졌었다가, 이번에 다시 커널패닉이 발생한 부분이다.
시스템 (OS) : RedHat Enterprise Linux 5
Kernel Ver. : 2.6.18-194.3.1.el5.it801213
Machine : x86_64
Memory : 12G
간단하게 코어 바로 열고 log 찍어보았다.
root@~]# crash /usr/lib/debug/lib/modules/2.6.18-194.3.1.el5/vmlinux vmcore20110128
.............생략................
KERNEL: /usr/lib/debug/lib/modules/2.6.18-194.3.1.el5/vmlinux
DUMPFILE: vmcore20110128
CPUS: 16
DATE: Fri Jan 28 10:39:19 2011
UPTIME: 35 days, 21:31:59
LOAD AVERAGE: 0.00, 0.09, 0.18
TASKS: 368
NODENAME: C**F2
RELEASE: 2.6.18-194.3.1.el5.it801213
VERSION: #1 SMP Mon May 31 04:01:01 EDT 2010
MACHINE: x86_64 (2666 Mhz)
MEMORY: 11.8 GB
PANIC: "Oops: 0000 [1] SMP " (check log for details)
PID: 21246
COMMAND: "MUXD"
TASK: ffff81016fb5b100 [THREAD_INFO: ffff810123b10000]
CPU: 2
STATE: TASK_RUNNING (PANIC)
crash >
Backtrace 부터 찍어보자..
crash> bt
PID: 21246 TASK: ffff81016fb5b100 CPU: 2 COMMAND: "MUXD"
#0 [ffff810123b11a00] crash_kexec at ffffffff800ada85
#1 [ffff810123b11ac0] __die at ffffffff80065157
#2 [ffff810123b11b00] do_page_fault at ffffffff80066dd7
#3 [ffff810123b11bf0] error_exit at ffffffff8005dde9
[exception RIP: list_del+8]
RIP: ffffffff80153f77 RSP: ffff810123b11ca8 RFLAGS: 00010246
RAX: 0000000000200200 RBX: ffff81028b3220d0 RCX: ffff810123b11c88
RDX: ffff8100a4597380 RSI: ffff81031f03d222 RDI: ffff81028b3220d0
RBP: ffff8101fd7fe140 R8: ffff81019c550680 R9: ffff81028b322000
R10: ffff8103077f4880 R11: 00000000000000c8 R12: ffff8101fd7fe140
R13: ffff8100a4597380 R14: 0000000000000000 R15: ffff8100a4597380
ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0018
#4 [ffff810123b11cb0] sctp_association_free at ffffffff885133cd
#5 [ffff810123b11cd0] sctp_do_sm at ffffffff885106ae
#6 [ffff810123b11e30] sctp_primitive_ABORT at ffffffff8851f0e3
#7 [ffff810123b11e50] sctp_close at ffffffff8851de4c
#8 [ffff810123b11eb0] inet_release at ffffffff80263694
#9 [ffff810123b11ed0] sock_release at ffffffff800553a1
#10 [ffff810123b11ef0] sock_close at ffffffff80055592
#11 [ffff810123b11f00] __fput at ffffffff80012a96
#12 [ffff810123b11f40] filp_close at ffffffff80023b84
#13 [ffff810123b11f60] sys_close at ffffffff8001dfa6
#14 [ffff810123b11f80] tracesys at ffffffff8005d28d (via system_call)
RIP: 00000039a040d637 RSP: 00007fff077d4e80 RFLAGS: 00000206
RAX: ffffffffffffffda RBX: ffffffff8005d28d RCX: ffffffffffffffff
RDX: 0000000000000002 RSI: 0000000000000000 RDI: 0000000000000004
RBP: 0000000000000000 R8: 00002ac6ddf1ceb0 R9: 000000399f919840
R10: 203a4e4e4f435349 R11: 0000000000000206 R12: 00007fff077d4ec0
R13: 00000000013e2360 R14: ffffffff8001dfa6 R15: ffff8100245eb680
ORIG_RAX: 0000000000000003 CS: 0033 SS: 002b
crash>
이번엔 로그 확인은 안할것이다. 어차피 모듈관련 로그만 떨어져있다...백트레이스와 비슷하게 나온다.
즉 Tainted 된 모듈은 없으며, 위에 BT 에서 보듯 SCTP 프로토콜의 Closing 후 Socket Descriptor 나 모듈을 해제할때
linked list 에서 엔트리제거과정에 오류가 발생하여 커널패닉이 떨어진 것 같다.
가장 마지막 스택들에 들어가있는 시스템콜을 보자면, sctp_association_free 인데, 이 이후에 list_del 에서
RIP 가 떨어져 있다... 즉 sctp_association_free 함수 호출 후, list 정리 함수에서 RIP 를 남기고 error_exit 를 호출한 것이므로,
list_del 에서 떨어진 패닉으로 확정 할 수 있겠다...
일단 RedHat bugzilla 에서 sctp 를 통한 검색을 해보았을땐 특별한 버그리포트를 찾을 수 없었다. ( 치사하게시리 ㅠㅠ )
분석 자체는 좀 많이 했는데 ( 대략 4시간가량 ) 실제 문서에서는 귀찮아서 간단하게 정리하겠다.
list_del+8 위치의 메모리번지에서 뻗은것이기 때문에, disassemble 을통해 살짝 살펴보자.
그래도 일단 list_del 이전의 호출되는 함수인 sctp_association_free 부분도 디스어셈코드를 보도록 하자 :)
특별히 배드스테이터스라고 할만한 코드는 보이지 않는데... 좀 이상한게 list_del 부분이 두번이나 호출된다는 점이다...
이건 sctp 모듈의 코드를 봐야 할것 같으나, 이 문서에서 그부분은 숙제로 남겨놓겠다.
chunk_free 도 두번이나 하는걸 보면 어쩌면 Double Chunk Free 버그일수도 있겠는데.......... :P
( 사실 소스를 난 봤는데 sctp 쪽을 잘 몰라서 모르겠더라 )
자..그럼 이제 list_del 의 디스어셈코드를 확인 해 보자.
길게 볼 필요는 없다. 사실 list_del 의 함수호출주소는 0xffffffff80153f68 이지만, +8 되는 오프셋 주소에서 문제가 생긴것이니,
0xffffffff80153f77 에서 찍어본 것이다. ( 앞쪽은 void 함수선언영역부분이 다이다. )
참고로 단순하게 dis list_del 이라고 해도 쭈욱 나온다. :)
자..list+8 부분에서 뻗은걸 기억해라.
그 아래부터 rd 명령으로 쭉 뿌려보면 16진수와 Ascii 문자들이 뿌려지는데 의미없는 문자들이 대부분이다.
printk 부분 메모리 영역을 자꾸 찍어보면 의미가 있는 소스구문이 발견된다.
(printk 는 kernel 에 문자를 출력하는 시스템콜인거 설명해야되나 ㅡ.,ㅡ:: )
자 잘보면 next->prev 의 구문등이 보일것이다.
list_del 의 소스를 확인해 보자. (소스위치등이랑 struct 등의 확인은 직접 해보아라 재밌다.. )
일단 list 라는 명령을 사용해 메모리상에서 list_del 함수의 Linked List 상태를 확인 할 수 있다.
짜잔~ 여기선 gdb 의 명령이 나오게 된다. crash 툴에서 gdb 명령을 추가호출하여 사용이 가능한데.
gdb 에서 소스코드를 보여주는 명령은 list 이다.
Linked List 상태를 보여주는 명령과 동일하므로 gdb 명령을 이용해야한다.. :)
gdb list list_del 을 하면 안타깝게도 10줄만 딸랑 보여준다.. 원래는 인자를 넣어서 몇줄씩 볼 수 있으나,
crash 에서 제공하는 gdb 는 인자를 안먹는다 샹샹바...어쨋든 대신 그러면 아까 list_del+8 이 가르치는 주소가 어떤소스인지
확인을 해보도록 한다.
주소를 입력하면 저렇게 몇재쭐의 코드를 가르키는 메모리주소인지 알려준다! :)
역시 커널버그일때의 코드를 가르키고있다.
간단히 설명하자면, list_head 스트럭쳐에 있는 entry 중 prev->next 영역이 엔트리에서 참조되지 않고 있는것 같을때
list 해제에 대한 버그임을 뿌려주라는 것이다.
* unlikely 는 커널 매크로로 (함수아님) True 가능성이 높은지, False 가능성이 높은지 러프하게 추정하여 동작 할 수 있게
하는 일종의 확률매크로라고 볼 수 있다. 즉 조건문에 대해서 false 가 떨어질 가능성이 높다면 이라는 조건분기라고 할 수 있다.
빨간색 표시된 부분중 첫번째인 메모리 접근이 불가능하다는 것을 보았을때, 메모리 해제과정에서 더블프리버그 혹은,
메모리 참조포인터를 잃어서 정상적인 링크드리스트 처리가 되지 않아 커널패닉이 떨어진 것으로 확정 할 수 있다.
자 여기까지 분석했으니 이제 남은건 모듈개발자 혹은 커널 개발자가 패치해줘야 하는것이겠지.....
너무 많은걸 바라진 말자..나에게.. 힘이들다... ㅠㅠ
레드햇 답변 올때까지 기다려 봐야지뭐... 언젠간 나도 내공을 충분히 쌓아 실제 문제가 되는 모듈코드도 찾아서 수정하고
할 수 있겠지!!!! :)
이번엔 페도라 14 사용중인 내 노트북에서 발생한 커널 패닉이다.
자세한 상황설명은 GFS 테스트를 위해 KVM 을 이용하여 RHEL 5 노드 2개를 생성 후, 노트북에 iscsi 바인딩데몬을 올렸고,
각 노드에서 이것을 활용 할 수 있게끔 iscsi initiator 를 설정하던중 발생한 패닉이다.
정확하게 노트북 (편의상 Host 라고 하겠다.) 에서 작동하는 iptables 에 3260 포트가 오픈되지 않아,
포트오픈 룰을 추가 후 iptables restart 명령을 내리자 갑자기 패닉되며 코어덤프를 떠버리던 상황이다.
시스템 (OS) : Fedora 14 ( Laughlin)
Kernel Ver. : 2.6.35.12-88.fc14
Machine : x86_64
Memory : 4G
KERNEL: /usr/lib/debug/lib/modules/2.6.35.12-88.fc14.x86_64/vmlinux
자.. 일단 여기서 보여주는 정보..매우 좋다.
PANIC 의 원인은 일단 PID 8762 를 할당받은 qemu-kvm 커맨드에서 kernel stack 이 잘못된 주소를 참조하여 stack-protector 가 동작해 싱크가 불가했다는 얘기이다.
어렵나? 일단 BT 찍어보자. 로그먼저 찍어보아도 좋다.
[ 9137.459831] Kernel panic - not syncing: stack-protector: Kernel stack is corrupted in: ffffffff81417249
[ 9137.459836]
[ 9137.459846] Pid: 8762, comm: qemu-kvm Not tainted 2.6.35.12-88.fc14.x86_64 #1
[ 9137.459852] Call Trace:
[ 9137.459857] <IRQ> [<ffffffff81468e1f>] panic+0x8b/0x10d
[ 9137.459877] [<ffffffff81417249>] ? icmp_send+0x50a/0x51c
[ 9137.459885] [<ffffffff8104de59>] get_taint+0x0/0x12
[ 9137.459890] [<ffffffff81417249>] icmp_send+0x50a/0x51c
[ 9137.459899] [<ffffffff81039d8f>] ? __wake_up_common+0x4e/0x84
[ 9137.459908] [<ffffffff81053a38>] ? local_bh_enable+0xe/0x10
[ 9137.459916] [<ffffffff8142bcfd>] ? ipt_do_table+0x590/0x6e7
[ 9137.459930] [<ffffffffa046821d>] ? br_dev_queue_push_xmit+0x82/0x88 [bridge]
[ 9137.459943] [<ffffffffa046d27e>] ? br_nf_dev_queue_xmit+0x0/0x83 [bridge]
[ 9137.459954] [<ffffffffa046d2ff>] ? br_nf_dev_queue_xmit+0x81/0x83 [bridge]
[ 9137.459965] [<ffffffffa046d277>] ? NF_HOOK_THRESH+0x4b/0x52 [bridge]
[ 9137.459973] [<ffffffff811e2f7b>] ? selinux_ip_forward+0x60/0x1c5
[ 9137.459982] [<ffffffff8142d8d0>] ? iptable_filter_hook+0x5c/0x60
[ 9137.459989] [<ffffffff813e1b8d>] ? nf_iterate+0x46/0x89
[ 9137.460001] [<ffffffffa046d5a1>] ? br_nf_forward_finish+0x0/0xa9 [bridge]
[ 9137.460006] [<ffffffff813e1c3a>] ? nf_hook_slow+0x6a/0xd0
[ 9137.460017] [<ffffffffa046d5a1>] ? br_nf_forward_finish+0x0/0xa9 [bridge]
[ 9137.460029] [<ffffffffa046d5a1>] ? br_nf_forward_finish+0x0/0xa9 [bridge]
[ 9137.460040] [<ffffffffa046d26d>] ? NF_HOOK_THRESH+0x41/0x52 [bridge]
[ 9137.460051] [<ffffffffa046d46c>] ? nf_bridge_pull_encap_header+0x25/0x31 [bridge]
[ 9137.460063] [<ffffffffa046ded1>] ? br_nf_forward_ip+0x1e0/0x1f4 [bridge]
[ 9137.460069] [<ffffffff813e3c5c>] ? __nf_conntrack_find+0x8d/0xea
[ 9137.460078] [<ffffffff813e1b8d>] ? nf_iterate+0x46/0x89
[ 9137.460087] [<ffffffffa046827c>] ? br_forward_finish+0x0/0x25 [bridge]
[ 9137.460093] [<ffffffff813e1c3a>] ? nf_hook_slow+0x6a/0xd0
[ 9137.460101] [<ffffffffa046827c>] ? br_forward_finish+0x0/0x25 [bridge]
[ 9137.460111] [<ffffffffa046827c>] ? br_forward_finish+0x0/0x25 [bridge]
[ 9137.460119] [<ffffffffa0468269>] ? NF_HOOK.clone.2+0x46/0x59 [bridge]
[ 9137.460128] [<ffffffffa046833a>] ? __br_forward+0x73/0x75 [bridge]
[ 9137.460137] [<ffffffffa04683a9>] ? br_forward+0x3a/0x4d [bridge]
[ 9137.460146] [<ffffffffa046906e>] ? br_handle_frame_finish+0x155/0x1c7 [bridge]
[ 9137.460156] [<ffffffffa0468f19>] ? br_handle_frame_finish+0x0/0x1c7 [bridge]
[ 9137.460168] [<ffffffffa046d277>] ? NF_HOOK_THRESH+0x4b/0x52 [bridge]
[ 9137.460179] [<ffffffffa046d49d>] ? nf_bridge_push_encap_header+0x25/0x31 [bridge]
[ 9137.460191] [<ffffffffa046d908>] ? br_nf_pre_routing_finish+0x205/0x228 [bridge]
[ 9137.460197] [<ffffffff813e1c3a>] ? nf_hook_slow+0x6a/0xd0
[ 9137.460207] [<ffffffffa046d703>] ? br_nf_pre_routing_finish+0x0/0x228 [bridge]
[ 9137.460219] [<ffffffffa046d703>] ? br_nf_pre_routing_finish+0x0/0x228 [bridge]
[ 9137.460231] [<ffffffffa046d277>] ? NF_HOOK_THRESH+0x4b/0x52 [bridge]
[ 9137.460242] [<ffffffffa046d9c0>] ? setup_pre_routing+0x4b/0x76 [bridge]
[ 9137.460254] [<ffffffffa046e369>] ? br_nf_pre_routing+0x484/0x494 [bridge]
[ 9137.460259] [<ffffffff813e1b8d>] ? nf_iterate+0x46/0x89
[ 9137.460266] [<ffffffff81066a45>] ? autoremove_wake_function+0x16/0x39
[ 9137.460276] [<ffffffffa0468f19>] ? br_handle_frame_finish+0x0/0x1c7 [bridge]
[ 9137.460282] [<ffffffff813e1c3a>] ? nf_hook_slow+0x6a/0xd0
[ 9137.460291] [<ffffffffa0468f19>] ? br_handle_frame_finish+0x0/0x1c7 [bridge]
[ 9137.460299] [<ffffffff8103d102>] ? __wake_up+0x44/0x4d
[ 9137.460308] [<ffffffffa0468f19>] ? br_handle_frame_finish+0x0/0x1c7 [bridge]
[ 9137.460318] [<ffffffffa0468f07>] ? NF_HOOK.clone.3+0x46/0x58 [bridge]
[ 9137.460327] [<ffffffffa0469251>] ? br_handle_frame+0x171/0x18c [bridge]
[ 9137.460336] [<ffffffff813bedd0>] ? __netif_receive_skb+0x2cd/0x412
[ 9137.460344] [<ffffffff810a9d8d>] ? check_for_new_grace_period.clone.19+0x8b/0x97
[ 9137.460352] [<ffffffff813c0742>] ? process_backlog+0x87/0x15d
[ 9137.460371] [<ffffffff8106b8d8>] ? sched_clock_cpu+0x42/0xc6
[ 9137.460379] [<ffffffff813c08c4>] ? net_rx_action+0xac/0x1bb
[ 9137.460385] [<ffffffff8106b8d8>] ? sched_clock_cpu+0x42/0xc6
[ 9137.460393] [<ffffffff81053dc9>] ? __do_softirq+0xf0/0x1bf
[ 9137.460401] [<ffffffff8100abdc>] ? call_softirq+0x1c/0x30
[ 9137.460407] [<ffffffff8100abdc>] ? call_softirq+0x1c/0x30
[ 9137.460411] <EOI> [<ffffffff8100c338>] ? do_softirq+0x46/0x82
[ 9137.460423] [<ffffffff813bfced>] ? netif_rx_ni+0x26/0x2b
[ 9137.460431] [<ffffffffa005d888>] ? tun_get_user+0x3e0/0x421 [tun]
[ 9137.460439] [<ffffffffa005ded1>] ? tun_chr_aio_write+0x0/0x84 [tun]
[ 9137.460447] [<ffffffffa005df3a>] ? tun_chr_aio_write+0x69/0x84 [tun]
[ 9137.460456] [<ffffffff81117d22>] ? do_sync_readv_writev+0xc1/0x100
[ 9137.460464] [<ffffffff811e4452>] ? selinux_file_permission+0xa7/0xb9
[ 9137.460474] [<ffffffff811dce11>] ? security_file_permission+0x16/0x18
[ 9137.460481] [<ffffffff81117f78>] ? do_readv_writev+0xa7/0x127
[ 9137.460488] [<ffffffff81125194>] ? do_vfs_ioctl+0x468/0x49b
[ 9137.460495] [<ffffffff81118941>] ? fput+0x22/0x1ed
[ 9137.460502] [<ffffffff8111803d>] ? vfs_writev+0x45/0x47
[ 9137.460508] [<ffffffff81118160>] ? sys_writev+0x4a/0x93
[ 9137.460515] [<ffffffff81009cf2>] ? system_call_fastpath+0x16/0x1b
crash> bt
PID: 8762 TASK: ffff88012e0f5d00 CPU: 2 COMMAND: "qemu-kvm"
#0 [ffff88000e303400] machine_kexec at ffffffff81027dc3
#1 [ffff88000e303480] crash_kexec at ffffffff81084ffa
#2 [ffff88000e303550] panic at ffffffff81468e26
#3 [ffff88000e3035d0] icmp_send at ffffffff81417249
#4 [ffff88000e303790] local_bh_enable at ffffffff81053a38
#5 [ffff88000e3037d0] ipt_do_table at ffffffff8142bcfd
#6 [ffff88000e303920] iptable_filter_hook at ffffffff8142d8d0
#7 [ffff88000e303930] nf_iterate at ffffffff813e1b8d
#8 [ffff88000e303980] nf_hook_slow at ffffffff813e1c3a
#9 [ffff88000e3039f0] NF_HOOK_THRESH at ffffffffa046d26d
#10 [ffff88000e303a20] br_nf_forward_ip at ffffffffa046ded1
#11 [ffff88000e303a60] nf_iterate at ffffffff813e1b8d
#12 [ffff88000e303ab0] nf_hook_slow at ffffffff813e1c3a
#13 [ffff88000e303b20] NF_HOOK.clone.2 at ffffffffa0468269
#14 [ffff88000e303b50] __br_forward at ffffffffa046833a
#15 [ffff88000e303b70] br_forward at ffffffffa04683a9
#16 [ffff88000e303b80] br_handle_frame_finish at ffffffffa046906e
#17 [ffff88000e303bc0] NF_HOOK_THRESH at ffffffffa046d277
#18 [ffff88000e303bf0] br_nf_pre_routing_finish at ffffffffa046d908
#19 [ffff88000e303c90] NF_HOOK_THRESH at ffffffffa046d277
#20 [ffff88000e303cc0] br_nf_pre_routing at ffffffffa046e369
#21 [ffff88000e303d00] nf_iterate at ffffffff813e1b8d
#22 [ffff88000e303d50] nf_hook_slow at ffffffff813e1c3a
#23 [ffff88000e303dc0] NF_HOOK.clone.3 at ffffffffa0468f07
#24 [ffff88000e303df0] br_handle_frame at ffffffffa0469251
#25 [ffff88000e303e20] __netif_receive_skb at ffffffff813bedd0
#26 [ffff88000e303e80] process_backlog at ffffffff813c0742
#27 [ffff88000e303ee0] net_rx_action at ffffffff813c08c4
#28 [ffff88000e303f40] __do_softirq at ffffffff81053dc9
#29 [ffff88000e303fb0] call_softirq at ffffffff8100abdc
--- <IRQ stack> ---
#30 [ffff88008ca79c20] netif_rx at ffffffff813bfbce
#31 [ffff88008ca79c60] netif_rx_ni at ffffffff813bfced
#32 [ffff88008ca79c80] tun_get_user at ffffffffa005d888
#33 [ffff88008ca79d00] tun_chr_aio_write at ffffffffa005df3a
#34 [ffff88008ca79d40] do_sync_readv_writev at ffffffff81117d22
#35 [ffff88008ca79e50] do_readv_writev at ffffffff81117f78
#36 [ffff88008ca79f30] vfs_writev at ffffffff8111803d
#37 [ffff88008ca79f40] sys_writev at ffffffff81118160
#38 [ffff88008ca79f80] system_call_fastpath at ffffffff81009cf2
RIP: 00000034e04d8ab7 RSP: 00007fe3a75e6998 RFLAGS: 00010202
RAX: 0000000000000014 RBX: ffffffff81009cf2 RCX: 0000000001376e68
RDX: 0000000000000001 RSI: 00007fe3a75e6920 RDI: 000000000000002a
RBP: 0000000000000001 R8: 0000000000000000 R9: 0000000000000000
R10: 0000000001343630 R11: 0000000000000293 R12: 00007fe3a75e6920
R13: 0000000001343670 R14: 0000000101343670 R15: 0000000000000000
ORIG_RAX: 0000000000000014 CS: 0033 SS: 002b
젠장할 길다. 그러나 사실 크게 여러가지 볼 필요는 없다. 이미 Stack Protector 가 동작한 주소가 나오고 있기 때문이다.
보면 icmp_send 라는 함수부에서 동일한 메모리 번지를 할당받았다.
icmp 룰 을 재정의하는 과정에 ( iptable 재시작을 했으니 ) 서 어떤 오류로 잘못된 참조값이 들어갔다는 얘기일 테니까..
일단 버그를 찾아보자...icmp_send 를 키워드로 bugzilla 와 kernel.org 또한 lkml 과 구글에게 물어봤으나,
이들도 썩 맞는 케이스를 던져주고 있지 않았다.
혹시 정말 icmp 소스에 어떤 논리적 오류라도 있는건가? 하여 소스를 확인해 보기로 했다.
crash> gdb list *0xffffffff81417235
0xffffffff81417235 is in icmp_send (net/ipv4/icmp.c:649).
644 ende:
645 ip_rt_put(rt);
646 out_unlock:
647 icmp_xmit_unlock(sk);
648 out:;
649 }
650
651
652 /*
653 * Handle ICMP_DEST_UNREACH, ICMP_TIME_EXCEED, and ICMP_QUENCH.
지금 나타내는 메모리번지의 코드라인은 649... } 로 블럭이 닫히는 부분이다.
제길 이 소스보기로는 의미가 없다 왜냐하면 저 주소는 저 코드가 들어가는 부분에 대한 표시일 뿐인거였다.
어쨋든 icmp.c 의 icmp_send 함수에서 생기는 문제인건 다시 확실해 졌는데 뭔가 다시 얻어낼 힌트 없을까?
소스를 쭈욱 직접 열어서 보면.... icmp_send 코드내용중에
/* RFC says return as much as we can without exceeding 576 bytes. */
631
632 room = dst_mtu(&rt->u.dst);
633 if (room > 576)
crash> l
634 room = 576;
635 room -= sizeof(struct iphdr) + icmp_param.replyopts.optlen;
636 room -= sizeof(struct icmphdr);
637
638 icmp_param.data_len = skb_in->len - icmp_param.offset;
639 if (icmp_param.data_len > room)
640 icmp_param.data_len = room;
641 icmp_param.head_len = sizeof(struct icmphdr);
굵게 칠한 부분들이 눈에 띈다.. 어라 이거 MTU 값이 576 인부분에대한 처리인데??
좋다 거의 다 왔다. 아까부터 사실 스택에 들어있는 함수들을 볼때 신경쓰였던게 br 즉 브릿지 관련 함수들이였다.
네트워크 관련된 이야기인데, KVM 에서는 호스트머신과 Guest 머신간 통신에 설정되는 내부 브릿지는 MTU 를 576 으로 소통한다.
즉 커널버그인건데, 버그질라에서 안나와서 구글에게 물었더니 RHEL6 에 관련된 버그질라 내용을 떡하니 보여준다. ( kvm icmp 로 키워드 )
https://partner-bugzilla.redhat.com/show_bug.cgi?id=629590 젠장... partner 라고 붙는 주소다...라지만 공개되어있다.
여기의 설명에 따르면 다음과 같은 구조를 설명해 준다.
<Remote Machine>--<Host Machine>--<Bridge>--<Tun/Tap>--<KVM Guest>
1500 mtu 576 mtu 576 mtu 576 mtu 1500 mtu
재밌는건 소스코드를 비교해봤는데 패치가 이미 적용되어 있다.
혹시 몰라 lkml 을 뒤져본다.
http://lkml.org/lkml/2010/8/30/391
요로코롬 이번엔 ip_output.c 의 ip_fragment 함수에 대해 패치가 있다.
어...이건 적용이 안되어있다.
커밋된지 한참 된것같은데....뭐 일단 어찌됐든, KVM 에서 Host 와 Guest 간 브릿지 MTU 값에 대한 문제로 생긴 icmp 라우팅문제라는게 대략적 결론.
다른아저씨들처럼 아직 MTU 수정해서 테스트해보진 않았으나 (글작성후 할거임)
확실히 다시 해보니 동일한 내용으로 코어가 생성된다.
커널메일링에 있는대로 ip option 관련 패치좀 해보고 정상유무 확인해야겠다. 오래된건데 왜 적용을 안했을까... 흑..
이번에도 역시 내 노트북에서 발생한 커널 패닉이다.
Fedora16 으로 업그레이드를 했어야 하나, 귀차니즘으로 마냥 있다보니 Fedora 15 이다 아직.
대략적인 상황으로는 이녀석을 요즘은 내가 노트북이 그닥 필요없어진 경지 - 라기보단 그냥 없어도 되는일들인 - 인지라,
집에 놓고당기는데, 이녀석이 꼭 돌아와보면 먹통. 즉, Wakeup 이 안된다는점... 그래서 항상 강제리부팅을 해오다,
커널패닉이 왜 안떨어지지? 라며 Sysrq 를 이용해 강제 크래슁을 시켰더니 먹통은 아니더라.....
그래서 일단 커널덤프를 살펴보기로 마음먹었다.. 오랜만이다 +.,+
시스템 (OS) : Fedora 15 ( Lovelock )
Kernel Ver. : 2.6.41.4-1.fc15
Machine : x86_64
Memory : 4G
KERNEL: /usr/lib/debug/lib/modules/2.6.41.4-1.fc15.x86_64/vmlinux
DUMPFILE: /var/crash/127.0.0.1-2011-12-31-02:55:50/vmcore
CPUS: 4
DATE: Sat Dec 31 11:55:50 2011
UPTIME: 1 days, 16:02:09
LOAD AVERAGE: 89.57, 89.12, 89.00
TASKS: 398
NODENAME: Mirr-N
RELEASE: 2.6.41.4-1.fc15.x86_64
VERSION: #1 SMP Tue Nov 29 11:53:48 UTC 2011
MACHINE: x86_64 (2393 Mhz)
MEMORY: 3.8 GB
PANIC: "[143880.225534] Oops: 0002 [#1] SMP " (check log for details)
PID: 29800
COMMAND: "kworker/0:1"
TASK: ffff880107d32e60 [THREAD_INFO: ffff880112062000]
CPU: 0
STATE: TASK_RUNNING (PANIC)
자.. 일단 여기서 보여주는 정보..에서의 특징은 oops SMP 에 대한 패닉내용과, kworker 를 보면 알 수 있는데,
매직키를 이용한 커널덤프를 발생시켰음을 추측 해 볼 수 있다는 점.
언제나처럼 log 를 찍어보도록 하자.
crash> log
b7 d0 c1 e8 10 39 c2 74 07 f3 90 <0f> b7 17 eb f5 5d c3 55 48 89 e5 66 66 66 66 90 8b 07 89 c2 c1
[143763.111566] Call Trace:
[143763.111570] <IRQ> [<ffffffff8149ca36>] _raw_spin_lock+0xe/0x10
[143763.111589] [<ffffffffa040d866>] rtl_lps_leave+0x1c/0xea [rtlwifi]
[143763.111603] [<ffffffffa040f3cb>] _rtl_pci_ips_leave_tasklet+0xe/0x10 [rtlwifi]
[143763.111611] [<ffffffff8105cddb>] tasklet_action+0x7f/0xd2
[143763.111619] [<ffffffff8105d683>] __do_softirq+0xc9/0x1b5
[143763.111627] [<ffffffff81027719>] ? ack_APIC_irq+0x15/0x17
[143763.111634] [<ffffffff81014b35>] ? paravirt_read_tsc+0x9/0xd
[143763.111642] [<ffffffff814a542c>] call_softirq+0x1c/0x30
[143763.111649] [<ffffffff81010b45>] do_softirq+0x46/0x81
[143763.111657] [<ffffffff8105d94b>] irq_exit+0x57/0xb1
[143763.111663] [<ffffffff814a5d0e>] do_IRQ+0x8e/0xa5
[143763.111671] [<ffffffff8149ce2e>] common_interrupt+0x6e/0x6e
[143763.111675] <EOI> [<ffffffff8124bd80>] ? ip_compute_csum+0x34/0x34
[143763.111689] [<ffffffff8124be69>] ? delay_tsc+0x35/0x74
[143763.111697] [<ffffffff8124bdd9>] __delay+0xf/0x11
[143763.111704] [<ffffffff8124be07>] __const_udelay+0x2c/0x2e
[143763.111717] [<ffffffffa0424ac4>] rtl92s_phy_set_rf_power_state+0x50f/0x601 [rtl8192se]
[143763.111732] [<ffffffffa040dd55>] ? rtl_swlps_rf_sleep+0x177/0x177 [rtlwifi]
[143763.111746] [<ffffffffa040d393>] rtl_ps_set_rf_state+0xdd/0xe3 [rtlwifi]
[143763.111760] [<ffffffffa040dc5e>] rtl_swlps_rf_sleep+0x80/0x177 [rtlwifi]
[143763.111774] [<ffffffffa040dd82>] rtl_swlps_wq_callback+0x2d/0x83 [rtlwifi]
[143763.111782] [<ffffffff8106ed8c>] process_one_work+0x176/0x2a9
[143763.111790] [<ffffffff8106f89a>] worker_thread+0xda/0x15d
[143763.111798] [<ffffffff8106f7c0>] ? manage_workers+0x176/0x176
[143763.111805] [<ffffffff81072ce7>] kthread+0x84/0x8c
[143763.111813] [<ffffffff814a5334>] kernel_thread_helper+0x4/0x10
[143763.111821] [<ffffffff81072c63>] ? kthread_worker_fn+0x148/0x148
[143763.111829] [<ffffffff814a5330>] ? gs_change+0x13/0x13
[143763.182744] BUG: soft lockup - CPU#1 stuck for 22s! [kworker/u:1:11382]
[143763.182749] Modules linked in: tun ip6table_filter ipt_MASQUERADE iptable_nat nf_nat nf_conntrack_ipv4 nf_defrag_ipv4 xt_state nf_conntrack xt_CHECKSUM iptable_mangle bridge ipv6 tcp_lp fuse ip6_tables ebtable_nat ebtables nfsd lockd nfs_acl auth_rpcgss sunrpc 8021q garp stp llc acpi_cpufreq mperf rfcomm bnep xfs btrfs zlib_deflate libcrc32c snd_hda_codec_hdmi snd_hda_codec_conexant snd_hda_intel arc4 rtl8192se rtlwifi mac80211 cfg80211 snd_hda_codec virtio_net kvm_intel kvm thinkpad_acpi btusb bluetooth uvcvideo videodev iTCO_wdt rfkill media joydev snd_hwdep snd_seq snd_seq_device snd_pcm snd_timer snd iTCO_vendor_support e1000e v4l2_compat_ioctl32 intel_ips i2c_i801 snd_page_alloc soundcore microcode wmi i915 drm_kms_helper drm i2c_algo_bit i2c_core video [last unloaded: scsi_wait_scan]
[143763.182853] CPU 1
[143763.182855] Modules linked in: tun ip6table_filter ipt_MASQUERADE iptable_nat nf_nat nf_conntrack_ipv4 nf_defrag_ipv4 xt_state nf_conntrack xt_CHECKSUM iptable_mangle bridge ipv6 tcp_lp fuse ip6_tables ebtable_nat ebtables nfsd lockd nfs_acl auth_rpcgss sunrpc 8021q garp stp llc acpi_cpufreq mperf rfcomm bnep xfs btrfs zlib_deflate libcrc32c snd_hda_codec_hdmi snd_hda_codec_conexant snd_hda_intel arc4 rtl8192se rtlwifi mac80211 cfg80211 snd_hda_codec virtio_net kvm_intel kvm thinkpad_acpi btusb bluetooth uvcvideo videodev iTCO_wdt rfkill media joydev snd_hwdep snd_seq snd_seq_device snd_pcm snd_timer snd iTCO_vendor_support e1000e v4l2_compat_ioctl32 intel_ips i2c_i801 snd_page_alloc soundcore microcode wmi i915 drm_kms_helper drm i2c_algo_bit i2c_core video [last unloaded: scsi_wait_scan]
[143763.182958]
[143763.182963] Pid: 11382, comm: kworker/u:1 Not tainted 2.6.41.4-1.fc15.x86_64 #1 LENOVO 3249PQ9/3249PQ9
[143763.182972] RIP: 0010:[<ffffffff81085dc9>] [<ffffffff81085dc9>] do_raw_spin_lock+0x1e/0x25
[143763.182983] RSP: 0018:ffff8801011cbda0 EFLAGS: 00000293
[143763.182988] RAX: 000000000000b484 RBX: 0000000000000286 RCX: 0000000000002a3b
[143763.182994] RDX: 000000000000b481 RSI: 0000000000000286 RDI: ffff88012d3a9d74
[143763.182999] RBP: ffff8801011cbda0 R08: ffff88012d3a9408 R09: 00000000005b3607
[143763.183005] R10: 00000000005b3607 R11: ffff880137c92d00 R12: ffff8801011cbd28
[143763.183010] R13: 0000000000000000 R14: 0000000000000002 R15: 0000000101da448b
[143763.183017] FS: 0000000000000000(0000) GS:ffff880137c80000(0000) knlGS:0000000000000000
[143763.183023] CS: 0010 DS: 0000 ES: 0000 CR0: 000000008005003b
[143763.183029] CR2: 0000000000cbf000 CR3: 0000000001a05000 CR4: 00000000000026e0
[143763.183034] DR0: 0000000000000003 DR1: 00000000000000b0 DR2: 0000000000000001
[143763.183040] DR3: 0000000000000000 DR6: 00000000ffff0ff0 DR7: 0000000000000400
[143763.183046] Process kworker/u:1 (pid: 11382, threadinfo ffff8801011ca000, task ffff880040d08000)
[143763.183051] Stack:
[143763.183055] ffff8801011cbdb0 ffffffff8149ca36 ffff8801011cbdd0 ffffffffa040dbaf
[143763.183064] ffff88012d3a9d40 ffff88012d3a8540 ffff8801011cbe00 ffffffffa040ac8c
[143763.183074] ffff88012d3a8540 0000000000000010 ffff88012cbe3800 ffffffffa03c0713
[143763.183083] Call Trace:
[143763.183091] [<ffffffff8149ca36>] _raw_spin_lock+0xe/0x10
[143763.183106] [<ffffffffa040dbaf>] rtl_swlps_rf_awake+0x54/0x6c [rtlwifi]
[143763.183119] [<ffffffffa040ac8c>] rtl_op_config+0x128/0x328 [rtlwifi]
[143763.183142] [<ffffffffa03c0713>] ? ieee80211_rx_mgmt_beacon+0x4d3/0x4d3 [mac80211]
[143763.183159] [<ffffffffa03b6fcb>] ieee80211_hw_config+0x102/0x107 [mac80211]
[143763.183182] [<ffffffffa03c0745>] ieee80211_dynamic_ps_disable_work+0x32/0x47 [mac80211]
[143763.183191] [<ffffffff8106ed8c>] process_one_work+0x176/0x2a9
[143763.183199] [<ffffffff8106f89a>] worker_thread+0xda/0x15d
[143763.183207] [<ffffffff8106f7c0>] ? manage_workers+0x176/0x176
[143763.183214] [<ffffffff81072ce7>] kthread+0x84/0x8c
[143763.183222] [<ffffffff814a5334>] kernel_thread_helper+0x4/0x10
[143763.183230] [<ffffffff81072c63>] ? kthread_worker_fn+0x148/0x148
[143763.183238] [<ffffffff814a5330>] ? gs_change+0x13/0x13
[143763.183242] Code: 00 00 10 00 74 05 e8 17 6e 1c 00 5d c3 55 48 89 e5 66 66 66 66 90 b8 00 00 01 00 f0 0f c1 07 0f b7 d0 c1 e8 10 39 c2 74 07 f3 90 <0f> b7 17 eb f5 5d c3 55 48 89 e5 66 66 66 66 90 8b 07 89 c2 c1
[143763.183313] Call Trace:
[143763.183320] [<ffffffff8149ca36>] _raw_spin_lock+0xe/0x10
[143763.183334] [<ffffffffa040dbaf>] rtl_swlps_rf_awake+0x54/0x6c [rtlwifi]
[143763.183348] [<ffffffffa040ac8c>] rtl_op_config+0x128/0x328 [rtlwifi]
[143763.183370] [<ffffffffa03c0713>] ? ieee80211_rx_mgmt_beacon+0x4d3/0x4d3 [macrash> bt
PID: 29800 TASK: ffff880107d32e60 CPU: 0 COMMAND: "kworker/0:1"
#0 [ffff880137c03640] machine_kexec at ffffffff8102ba1a
#1 [ffff880137c036b0] crash_kexec at ffffffff810925c1
#2 [ffff880137c03780] oops_end at ffffffff8149db69
#3 [ffff880137c037b0] no_context at ffffffff814930f1
#4 [ffff880137c03810] __bad_area_nosemaphore at ffffffff814932cb
#5 [ffff880137c03870] bad_area_nosemaphore at ffffffff814932ff
#6 [ffff880137c03880] do_page_fault at ffffffff8149fb96
#7 [ffff880137c03990] page_fault at ffffffff8149d0f5
[exception RIP: sysrq_handle_crash+22]
RIP: ffffffff812d6ed1 RSP: ffff880137c03a40 RFLAGS: 00010086
RAX: 0000000000000010 RBX: ffffffff81a70e20 RCX: 000000000000dc0e
RDX: 0000000000000000 RSI: 0000000000000046 RDI: 0000000000000063
RBP: ffff880137c03a40 R8: 0000000000000001 R9: 0000ffff00066c0a
R10: 0000ffff00066c0a R11: 0000000000000000 R12: 0000000000000004
R13: 0000000000000063 R14: 0000000000000002 R15: 0000000000000001
ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0018
#8 [ffff880137c03a48] __handle_sysrq at ffffffff812d7464
#9 [ffff880137c03a88] sysrq_filter at ffffffff812d7655
#10 [ffff880137c03ac8] input_pass_event at ffffffff81381be6
#11 [ffff880137c03b28] input_handle_event at ffffffff8138320a
#12 [ffff880137c03b78] input_event at ffffffff8138330b
#13 [ffff880137c03bc8] atkbd_interrupt at ffffffff813886de
crash>
이번 것 역시 딱 보면 어디가 문제인지 알기 쉽게 나와있다.
그것은 바로 Spin_Lock 의 문제라는것! 고질적인 이놈의 스핀락 롹롹롹!!! 설마 LoveLock 이라는 릴리즈명 때문은 아니겠지? ㅎ
아무튼 눈에 띄는 그동안 알고 있던 내용들을 우선적으로 찾아보면, Spin Lock 으로 인해 CPU time 을 제대로 얻어오지 못했음을
직감적으로 알 수 있어야 한다. - 알고 있지 다들?
자, 그럼 이제 그 스택들을 살펴보도록 하자.
일단 IRQ 에 대한 spin lock 을 관리하는 raw_spin_lock 시스템 콜이 찍혀있음을 보았을때,
이것은 H/W 의 드라이버 혹은 H/W 관련된 문제임을 알 수 있다. - 그냥 그렇게 알면 된다.
그담에 눈여겨 볼것이 있다. 바로 rtl_lps_leave+0x1c/0xea [rtlwifi] 이녀석들인데!
눈치밥있다면 Realtek 관련 함수이지 않을까 라고 때려줘야 한다는 사실...
이것은 rtl92s_phy_set_rf_power_state+0x50f/0x601 [rtl8192se] 이녀석을 찾아보면 확실해진다.
그렇다! 내가 쓰고 있는 노트북인 IBM X201 모델에 들어있는 Realtek 무선랜카드는,
rtl8192SE 라는 드라이버를 사용하고 있으며, 이녀석은 커널에서 자체지원하지 않던 모델이라,
내가 직접 드라이버를 다운받아 컴파일하여 올려논 드라이버였다.
즉, 노트북이 대기모드나, 화면절약모드로 들어가있을때, 무선랜카드에서 전해지는 신호를 감지하거나,
유지시키는등의 Context Switching 과정에서 문제가 생겨 무한 데드락이 걸리는 현상이였던 것이다.
자..여기서 "그렇다면 문제는 커널 Spin Lock 이라고 내뱉을게 아니라, 드라이버 오류 Tained 를 뿝어야 하는거 아니냐!"
라는 맘에드는 예리한 인간이 있었으면 좋겠을려만... 나혼자 있는 상황이니 넘어가도록 하자.
항상 얘기하듯 이런건 일단 버그라고 뜬 부분이 있으니 버그질라를 찾아보도록 하자.
아주아주 깔쌈하게도, rtl_lps_leave 로 구글링을 하면 동일 버젼의 비슷한 부류의 커널 버그들을 알려주고 있는
RedHat Bugzilla 와, Kernel.org 가 여럿 발견된다.
https://bugzilla.redhat.com/show_bug.cgi?id=755154
http://thread.gmane.org/gmane.linux.kernel.wireless.general/81542/focus=81657
아주아주 간단하고도 친절스럽게, lps_leave 라는 함수는 Interrup context 로 부터 얼마든지 호출 될 수 있고,
이 과정에서 IRQ 에 대한 충돌이 일어나 Deadlock 에 진입 할 수도 있다는 간략한 설명이 있으며,
간단하게 IRQ 에 대한 스핀락 처리 함수를 Replace 하는 방법으로 해결 할 수 있다고 나와있다.
재밌게도 내가 컴파일해 사용하던 rtl8192se 의 드라이버에서는 당연히 spin_lock_irq 함수와,
spin_lock_irqsave 등의 함수들을 잘 사용하고 있었고, 역시 문제는 Kernel 에서 대기모드에서
활성모드로 전향하기 위한 irq spin lock 부분을 실제 처리해주는 모듈인 rtlwifi 가 문제이기 때문에,
위 문제를 해결하려면 나의 커널을 Fedora16 의 커널인 3.1대로 올리던가,
최소한 커널버젼 2.4.41.6-1.fc15 이상으로 올려야 한다고 한다.
문제는 위 버그질라에서 얘기하는 커널은 아직 Stable 커널이 아닌 Testing 커널이라는점,
어차피 나야 개인노트북이고, Fedora16 로 올라가야할 시간도 남아있으니 테스팅커널을 받아 이것저것 테스팅 해볼참이다.
테스팅 커널을 받는 방법은 다음과 같다.
[root@Mirr-N ~ ]# yum update kernel --enablerepo=updates-testing
Loaded plugins: fastestmirror, langpacks, presto, refresh-packagekit
Loading mirror speeds from cached hostfile
* fedora: ftp.cuhk.edu.hk
* rpmfusion-free: mirrors.163.com
* rpmfusion-free-updates: mirrors.163.com
* rpmfusion-nonfree-updates: ucmirror.canterbury.ac.nz
* updates: ftp.riken.jp
* updates-testing: ftp.riken.jp
Setting up Install Process
Resolving Dependencies
There are unfinished transactions remaining. You might consider running yum-complete-transaction first to finish them.
--> Running transaction check
---> Package kernel.x86_64 0:2.6.41.6-1.fc15 will be installed
--> Finished Dependency Resolution
--> Running transaction check
---> Package kernel.x86_64 0:2.6.40.6-0.fc15 will be erased
--> Finished Dependency Resolution
Dependencies Resolved
================================================================================
Package Arch Version Repository Size
================================================================================
Installing:
kernel x86_64 2.6.41.6-1.fc15 updates-testing 27 M
Removing:
kernel x86_64 2.6.40.6-0.fc15 @updates 110 M
Transaction Summary
================================================================================
Install 1 Package(s)
Remove 1 Package(s)
Total download size: 27 M
Is this ok [y/N]: y
Downloading Packages:
Setting up and reading Presto delta metadata
updates-testing/prestodelta | 4.2 kB 00:00
Processing delta metadata
Package(s) data still to download: 27 M
kernel-2.6.41.6-1.fc15.x86_64.rpm | 27 MB 02:04
Running rpm_check_debug
Running Transaction Test
Transaction Test Succeeded
Running Transaction
Installing : kernel-2.6.41.6-1.fc15.x86_64 1/2
Cleanup : kernel-2.6.40.6-0.fc15.x86_64 2/2
Removed:
kernel.x86_64 0:2.6.40.6-0.fc15
Installed:
kernel.x86_64 0:2.6.41.6-1.fc15
Complete!
[root@Mirr-N ~ ]# cat /etc/grub.conf
# grub.conf generated by anaconda
#
# Note that you do not have to rerun grub after making changes to this file
# NOTICE: You have a /boot partition. This means that
# all kernel and initrd paths are relative to /boot/, eg.
# root (hd0,0)
# kernel /vmlinuz-version ro root=/dev/mapper/vg_mirr-LogVol00
# initrd /initrd-[generic-]version.img
#boot=/dev/sda
default=0
timeout=0
splashimage=(hd0,0)/grub/splash.xpm.gz
hiddenmenu
title Fedora (2.6.41.6-1.fc15.x86_64)
root (hd0,0)
kernel /vmlinuz-2.6.41.6-1.fc15.x86_64 root=/dev/mapper/vg_mirr-LogVol00 ro rd_LVM_LV=vg_mirr/LogVol00 rd_LVM_LV=vg_mirr/LogVol01 rd_NO_LUKS rd_NO_MD rd_NO_DM LANG=ko_KR.UTF-8 KEYTABLE=us rhgb quiet crashkernel=192M
initrd /initramfs-2.6.41.6-1.fc15.x86_64.img
title Fedora (2.6.41.4-1.fc15.x86_64.debug)
root (hd0,0)
kernel /vmlinuz-2.6.41.4-1.fc15.x86_64.debug root=/dev/mapper/vg_mirr-LogVol00 ro rd_LVM_LV=vg_mirr/LogVol00 rd_LVM_LV=vg_mirr/LogVol01 rd_NO_LUKS rd_NO_MD rd_NO_DM LANG=ko_KR.UTF-8 KEYTABLE=us rhgb quiet crashkernel=192M
initrd /initramfs-2.6.41.4-1.fc15.x86_64.debug.img
title Fedora (2.6.41.4-1.fc15.x86_64)
root (hd0,0)
kernel /vmlinuz-2.6.41.4-1.fc15.x86_64 root=/dev/mapper/vg_mirr-LogVol00 ro rd_LVM_LV=vg_mirr/LogVol00 rd_LVM_LV=vg_mirr/LogVol01 rd_NO_LUKS rd_NO_MD rd_NO_DM LANG=ko_KR.UTF-8 KEYTABLE=us rhgb quiet crashkernel=192M
initrd /initramfs-2.6.41.4-1.fc15.x86_64.img
아주 간단하게 인스톨 되었다.
이제 부팅 후 Realtek 모듈 다시 올려본 뒤 한참 대기모드에 넣어보면 비교가 가능 할 것이다. 우히힛
역시 패치해보니 잘 행업 없이 잘 동작함을 확인 할 수 있었다. :)
| No space left on device ( df -i , i-node) (0) | 2018.08.31 |
|---|---|
| vi 에디터에서 utf8, euc-kr 전환하기 (펌글) (0) | 2018.08.31 |
| centos 5.9 64bit geoip iptables 설치 (0) | 2018.08.31 |
| 서버가 응답이 없어요..INfo:task <process>:<pid> lock for more than 120 seconds" 출처: http://ssambback.tistory.com/entry/서버가-응답이-없어요INfotask-processpid-lock-for-more-than-120-seconds [Rehoboth.. 이곳에서 부터] 출처.. (0) | 2018.08.31 |
| call trace 에러 (0) | 2018.08.31 |
GeoIP 란 MaxMind 에서 제공하는 국가별로 IP를 확인할 수 있는 오픈소스 라이브러리로 이를 이용하여 서버에 접근 하는 아이피를 국가별로 관리할 수 있습니다.
테스트 OS : CentOS 5.9 64bit
1. Apache에 GeoIP 모듈 설치하기
1-1. GeoIP C API 설치하기
# cd /usr/local/src
http://geolite.maxmind.com/download/geoip/api/c/
# wget http://geolite.maxmind.com/download/geoip/api/c/GeoIP-1.4.6.tar.gz
# tar xvfz GeoIP-1.4.6.tar.gz
# cd GeoIP-1.4.6
#./configure --prefix=/usr/local/GeoIP
# make && make install
- GeoIP의 ip목록을 최신정보로 갱신하기 위하여 GeoIP.dat 을 다운받아 설치된 위치에 복사
: 국가 정보 다운로드
# wget http://geolite.maxmind.com/download/geoip/database/GeoLiteCountry/GeoIP.dat.gz
: 도시 정보 다운로드
#wget http://geolite.maxmind.com/download/geoip/database/GeoLiteCity.dat.gz
# gzip -d GeoIP.dat.gz
# gzip -d GeoLiteCity.dat.gz
- 해제된 파일을 GeoIP가 설치된 위치에 덮어쓰기
#cp -a GeoIP.dat /usr/local/GeoIP/share/GeoIP/
#cp -a GeoLiteCity.dat /usr/local/GeoIP/share/GeoIP/
1-2. GeoIP 모듈을 아파치에 설치하기
-mod_geoip 다운
아파치 1.x 용
http://geolite.maxmind.com/download/geoip/api/mod_geoip/
아파치 2.x 용
http://geolite.maxmind.com/download/geoip/api/mod_geoip2/
ex)아파치 2.x용 다운로드
http://geolite.maxmind.com/download/geoip/api/mod_geoip2/mod_geoip2_1.2.5.tar.gz
# tar zxvf mod_geoip2_1.2.5.tar.gz
-> 해제된 위치로 이동 후 c 파일을 apxs 를 이용하여 설치
# cd mod_geoip2_1.2.5
# [아파치 apxs경로] -i -a -L [geoip 설치 디렉토리의 lib 경로] -I [geoip 설치 디렉토리의 include 경로] -l GeoIP -c [mod_geoip.c 경로]
----> 옵션 대소문자 주의 -l GeoIP = 소문자 엘로 시작
# /usr/local/apache/bin/apxs -i -a -L /usr/local/GeoIP/lib -I /usr/local/GeoIP/include -l GeoIP -c /usr/local/src/mod_geoip2_1.2.5/mod_geoip.c
# ls -al /usr/local/apache/modules/mod_geoip.so
# cat /usr/local/apache/conf/httpd.conf | grep geoip
- phpinfo 페이지의 Apache Environment 정보에 GEOIP_CONTINENT_CODE, GEOIP_COUNTRY_CODE, GEOIP_COUNTRY_NAME 항목 확인
# vi /usr/local/apache/conf/httpd.conf
특정 국가의 접근 차단
<IfModule mod_geoip.c>
GeoIPEnable On
GeoIPDBFile /usr/local/GeoIP/share/GeoIP/GeoIP.dat
<Location /home>
SetEnvIf GEOIP_COUNTRY_CODE CN go_out
SetEnvIf GEOIP_COUNTRY_CODE RU go_out
SetEnvIf GEOIP_COUNTRY_CODE TH go_out
<Limit GET POST>
Order allow,deny
Allow from all
Deny from env=go_out
</Limit>
</Location>
</IfModule>
특정 국가에만 접근 허용
<IfModule mod_geoip.c>
GeoIPEnable On
GeoIPDBFile /usr/local/GeoIP/share/GeoIP/GeoIP.dat
<Location /home>
SetEnvIf GEOIP_COUNTRY_CODE KR go_in
<Limit GET POST>
Order Deny,Allow
Deny from all
Allow from env=go_in
</Limit>
</Location>
</IfModule>
[참고]
Cannot load /usr/local/apache/libexec/mod_geoip.so into server: libGeoIP.so.1: cannot open shared object file: No such file or directory
에러 발생시
/etc/ld.so.conf 파일에
/usr/local/GeoIP/lib 라인 추가 후
ldconfig 적용
===================================================================
* GeoIP에는 국가별 IP대역에 대한 database가 담겨 있습니다. 이를 각 패키지 모듈에 적재하여 여러 방법으로 접속제한 및 속도향상, 등 여러가지 재미있는 구성을 해 볼 수 있습니다. 이번 포스팅에는 iptables에 모듈 적재하여 국가별로 접속을 제한하는 방법에 대해 설명 해 보고자 합니다.
GeoIP의 경우 공식적인 모듈 업데이트가 몇년 전에 중단 된 것으로 알고 있어 구 버전 OS를 사용하는 경우가 있으나
이를 위해 최신 OS 커널에 작업을 해보겠습니다.
2. Iptables에 GeoIP 모듈 설치하기
2-1. patch-o-matic-ng 구버전을 받아 압축을 푼다. patch-o-matic-ng 최근 버전의 경우 커널과 iptables에 ipt_geoip가 아닌 xt_geoip 모듈이 추가되는데, 2.6.18.x 커널과 iptables 1.3.5 버전엔 맞지 않는 모듈이라고 한다. iptables의 경우 v1.4.3 이상이 설치되어 있어야 사용 가능하다고 합니다.
-다운 경로 : http://ftp.netfilter.org/pub/patch-o-matic-ng/snapshot/
# cd /usr/src
# wget http://ftp.netfilter.org/pub/patch-o-matic-ng/snapshot/patch-o-matic-ng-20080521.tar.bz2
# tar xvf patch-o-matic-ng-20080521.tar.bz2
2-2.
rpm으로 설치된 iptables에 geoip extension을 추가하려면 iptables srpm을 받아 patch-o-matic-ng를 적용하고 리빌드하여 설치해야한다.
http://rpm.pbone.net 을 통해 iptables의 srpm을 다운받아 설치한다.
# ln -s /usr/src/kernel/`uname -r` /usr/src/linux
-> 최신 커널 버전을 입력
*****************************
geoip update 스크립트
http://people.netfilter.org/peejix/geoip/tools/geoip_update.sh
*******************************
# cd /usr/src/patch-o-matic-ng-20080521
# ./runme --download --> geoip 소스 가져오기
# ./runme geoip --> kernel과 iptables에 geoip 모듈 소스가 설치
* 주의사항 : 위 두줄 명령어 실행시 kernel dir 과 iptables dir의 위치를 찾을 수 없다는 메세지가 나올 수 있으며 심볼릭 링크를 제대로 걸어준 상태라면 /usr/src/linux , /usr/src/iptables 를 입력후 엔터하면 제대로 넘어간다.
Welcome to Patch-o-matic ($Revision: 6736 $)! Kernel: 2.6.18, /usr/src/linux
Iptables: 1.3.5, /usr/src/iptables
Each patch is a new feature: many have minimal impact, some do not.
Almost every one has bugs, so don't apply what you don't need!
-------------------------------------------------------
Already applied:
Testing geoip... not applied
The geoip patch:
Author: Samuel Jean <jix@bugmachine.ca>; Nicolas Bouliane <nib@bugmachine.ca>
Status: Stable This patch makes possible to match a packet
by its source or destination country. GeoIP options:
[!] --src-cc, --source-country country[,country,country,...] Match packet coming from (one of)
the specified country(ies) [!] --dst-cc, --destination-country country[,country,country,...] Match packet going to (one of)
the specified country(ies) NOTE: The country is inputed by its ISO3166 code. The only extra files you need is a binary db (geoipdb.bin) & its index file (geoipdb.idx).
Take a look at http://people.netfilter.org/peejix/geoip/howto/geoip-HOWTO.html
for a quick HOWTO.
-----------------------------------------------------------------
Do you want to apply this patch [N/y/t/f/a/r/b/w/q/?] y
Excellent! Source trees are ready for compilation.
Recompile the kernel image (if there are non-modular netfilter modules).
Recompile the netfilter kernel modules.
Recompile the iptables binaries
위에서 압푹 푼 iptables의 extensions 경로에 geoip 패치파일이 있는지 확인한다
[root@ns patch-o-matic-ng-20071231]# ls -l /usr/src/iptables/extensions | grep geoip
# cd /usr/src/iptables
# make --> libipt_geoip.so 모듈 생성
# make install 또는
# cd extensions
# cp libipt_geoip.so /lib64/iptables --> iptables 실행 준비 완료
* 주의사항 : extensions 디렉터리에서 모듈을 lib에 복사하지 않으면 다음과 같은 에러 때문에 iptables에 geoip 모듈을 적용할 수 없다.
iptables v1.3.5: Couldn't load match `geoip':/lib/iptables/libipt_geoip.so: cannot open shared object file: No such file or directory
이 에러는 iptables의 geoip extension이 없어서 발생하는 문제 입니다. 이 글을 iptables의 geoip extension을 알아서 준비하셨거나 하실 거라고 가정을 하고, geoip kernel netfilter module을 빌드하기 위한 방법을 적은 것입니다.
즉, iptables 를 geoip extension을 넣어서 새로 빌드 하셔야 한다는 얘기 입니다. geoip extension은 patch-o-matics 에서 찾으실 수 있는데, 요즘 geoip extension이 있는 사이트가 죽은 모양인지 연결이 안되서, 인터넷을 뒤져야 할 수도 있을 것 같습니다. ^^;
즉, iptables에서 geoip를 사용하기 위해서는 ipbltales geoip extension과 kernel netfilter iptables module 이 필요하고, 이 글은 후자(kernel module)을 빌드하기 위한 글 입니다. (즉, iptblaes에서 geoip를 사용하기 위한 전반적인 내용을 담고 있는 것이 아닙니다.)
========================================================
2-3. 커널 작업
# cd /usr/src/linux
# make oldconfig
...(중략)...
geoip match support (IP_NF_MATCH_GEOIP) [N/m/?] (NEW)
# make modules_prepare
# mv net/ipv4/netfilter/Makefile net/ipv4/netfilter/Makefile.orig
# vi net/ipv4/netfilter/Makefile
obj-m := ipt_geoip.o
KDIR := /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
default:
$(MAKE) -C $(KDIR) M=$(PWD) modules
# make M=net/ipv4/netfilter
# cp net/ipv4/netfilter/ipt_geoip.ko /lib/modules/최신커널버전/kernel/net/ipv4/netfilter/
# chmod 744 /lib/modules/최신커널버전/kernel/net/ipv4/netfilter/ipt_geoip.ko
# depmod -a
# ls -l /lib/modules/2.6.18-164.el5/kernel/net/ipv4/netfilter | grep geoip
# modprobe ipt_geoip
# lsmod | grep geoip --> module 로딩 되었는지 확인
# yum install GeoIP GeoIP-devel
# mkdir /var/geoip
# cd /var/geoip
# wget http://people.netfilter.org/peejix/geoip/tools/csv2bin-20041103.tar.gz
# tar xvfz csv2bin-20041103.tar.gz
# cd csv2bin
# make
#>geoip_csv_update
#!/bin/bash
cd /var/geoip/
wget http://www.maxmind.com/download/geoip/database/GeoIPCountryCSV.zip
unzip GeoIPCountryCSV.zip
mv GeoIPCountryWhois.csv csv2bin/
cd /var/geoip/csv2bin/
chmod 755 GeoIPCountryWhois.csv
./csv2bin GeoIPCountryWhois.csv
cp geoipdb* /var/geoip -f
rm -f /var/geoip/GeoIPCountryCSV.zip
# ./geoip_csv_update-> 쉘 실행
----------------------------------------------------------------------------
3. iptables 룰 적용
***** 주의 : 체인 적용 할 때 INPUT 체인 대신 따른 체인을 사용한다면 꼭 적용되는 지 테스트 해 볼 것 -> 구글 크롭 Zenmate 사용
# iptables -I INPUT -p tcp -m geoip ! --src-cc KR -j DROP
# iptables -I OUTPUT -p tcp -m geoip ! --dst-cc KR -j DROP
1) 예로 국내를 제외한 모든 해외로부터의 시스템 접근 차단하기
iptables -A INPUT -m geoip ! --src-cc KR -j DROP
2) 중국 IP 대역으로부터 들어오는 ssh 접근 차단하기
iptables -A INPUT -p tcp --dport 22 -m geoip --src-cc CN -j DROP
-A RH-Firewall-1-INPUT -p tcp --dport 80 -m geoip ! --src-cc KR,AU,VN,JP,US -j DROP
-A RH-Firewall-1-INPUT -p tcp --dport 22 -m geoip ! --src-cc KR -j DROP
또는
# vi /etc/sysconfig/iptables 에 등록
# /etc/init.d/iptables restart
# iptables -L
확인
참고 : http://www.digimoon.net/blog/342
http://crowz.co.kr/49 여기서 전부 싹 퍼온거임
| vi 에디터에서 utf8, euc-kr 전환하기 (펌글) (0) | 2018.08.31 |
|---|---|
| 커널 패닉,행업,크래쉬 kernel panic crash hangup 분석 (0) | 2018.08.31 |
| 서버가 응답이 없어요..INfo:task <process>:<pid> lock for more than 120 seconds" 출처: http://ssambback.tistory.com/entry/서버가-응답이-없어요INfotask-processpid-lock-for-more-than-120-seconds [Rehoboth.. 이곳에서 부터] 출처.. (0) | 2018.08.31 |
| call trace 에러 (0) | 2018.08.31 |
| kill PID 여러개 한번에 죽이기 (0) | 2018.08.31 |
wget http://pkgs.repoforge.org/rpmforge-release/rpmforge-release-0.5.3-1.el6.rf.x86_64.rpm
CentOS 6
http://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
CentOS 5
http://dl.fedoraproject.org/pub/epel/5/x86_64/epel-release-5-4.noarch.rpm
yum 했는데 파일 없다고 할때
| Hdd하드와 ssd 하드에 따른 dbms 속도 비교 (0) | 2018.08.31 |
|---|---|
| warning: unmappable character for encoding UTF8 (0) | 2018.08.31 |
| ssl 인즉서 적용 확인하는곳 (0) | 2018.08.31 |
| ncdu 명령어 (0) | 2018.08.31 |
| sed '/^\#/d' 파일 > 파일_주석제거된거 (0) | 2018.08.31 |
https://www.comodossl.co.kr/products/ssl-checker.aspx
SSL 인증서 적용 상태 테스트 툴 - HanbiroSSL
www.comodossl.co.kr
https://www.geocerts.com/ssl_checker
| warning: unmappable character for encoding UTF8 (0) | 2018.08.31 |
|---|---|
| rpmforge (0) | 2018.08.31 |
| ncdu 명령어 (0) | 2018.08.31 |
| sed '/^\#/d' 파일 > 파일_주석제거된거 (0) | 2018.08.31 |
| 특정 프로세스 grep으로 찾아가지고 해당 프로세스들 $2 불러와서 kill 하기 (0) | 2018.08.31 |
리눅스 시스템을 운영하다 보면 시스템 Hang-up에 대한 문제점을 많이 들어나게 됩니다. 물론 리눅스 시스템
자체의 문제점이라고 보다는 특정 운영 프로세스에 대해서 인터럽트 또는 스케쥴이 정상적으로 진행되지 못했을때 나타는 문제점에 대해서 간략해 소개해 보고자 합니다.
갑자기 시스템 로그에서 출력하게된 /var/log/message 의 시스템 로그.
kernel: INFO: task startup.sh:9902 blocked for more than 120 seconds. |
[예상 문제점 1]
시스템 로그에서 나타난 kernel:INFO: task 의 메세지를 나타내는 의미는 현재 운영하고자 하는 startup.sh
스크립트에 대해서 120초 (2분 default) 동안 khungtaskd 쓰레드에서 D-state 상태를 감지하여 call trace
를 호출하게 되는 상황으로 예측할 수 있습니다.
[예상 문제점2]
시스템의 성능저하 특히 레드햇의 보고서에 의하면 디스크의 heavy I/O 로 나타나는 문제점으로
예측될수 있습니다.
[예상 문제점 2]
운영되고 있는 Application에 대해서 "D-state" (Uninterruptible sleep) 모드가 120초 동안 지속되었을때
예측될수 있는 문제로 해당 프로세스가 정상적으로 스케쥴링이 일어나지 않았을 때도 나타나게 됩니다
[ D-state 원인분석을 위해서는 ? ]
위와같은 문제점에 대해서 접근할수 있는 기본적인 방법에 대해서는 정확한 문제점을 파악하기 위해서는 커널의 덤프를 이용하여 core를 분석하는 것이 가장 정확할수 있습니다. core를 분석하기 위한 방법론에 대해서는 다음
블로깅을 통하여 소개하도록 하겠습니다.
# echo 1 > /proc/sys/kernel/hung_task_panic |
위와 같이 kernel core를 생성하기 위해 설정을 진행한 후 동일한 현생이 발생되어 core가 생성이 되면 문제가
되는 운영 프로세스의 D-state 문점에 대해서 분석이 가능합니다.
[ hung_task_timeout을 Disable 시켜라]
기본적인 Work-Arround에 대해서는 아래와 같이 hung_task_timeout 부분에 대해서 Disable 시켜주는 것을 권장하고 있습니다.
# echo 0 > /proc/sys/kernel/hung_task_timeout_secs |
위와 같이 커널에서 Hang Time OUt 을 체크하는 부분에 대해서 Disable 시켜준 후에는 call trace 여부가 지속적으로 발생되는지 모니터링이 필요합니다. 만약 해당 프로세스에 대해서 Uninterrupt sleep이 지속적으로 발생한다면 커널 업데이트 또한 고려해야 합니다.
출처: http://ssambback.tistory.com/entry/서버가-응답이-없어요INfotask-processpid-lock-for-more-than-120-seconds [Rehoboth.. 이곳에서 부터]
출처: http://ssambback.tistory.com/entry/서버가-응답이-없어요INfotask-processpid-lock-for-more-than-120-seconds [Rehoboth.. 이곳에서 부터]
| 커널 패닉,행업,크래쉬 kernel panic crash hangup 분석 (0) | 2018.08.31 |
|---|---|
| centos 5.9 64bit geoip iptables 설치 (0) | 2018.08.31 |
| call trace 에러 (0) | 2018.08.31 |
| kill PID 여러개 한번에 죽이기 (0) | 2018.08.31 |
| curl 로 페이지 접속하는데 간헐적으로 느리면 (0) | 2018.08.31 |
Mar 24 11:19:15 grep-r kernel: You need to implement a remote task_setrlimit in your security module and call it directly from this functionWARNING: at security/security.c:51 security_o
ps_task_setrlimit()
Mar 24 11:19:15 grep-r kernel:
Mar 24 11:19:15 grep-r kernel: Call Trace:
Mar 24 11:19:15 grep-r kernel: [<ffffffff8012f05b>] security_ops_task_setrlimit+0x87/0x96
Mar 24 11:19:15 grep-r kernel: [<ffffffff8009dc2f>] do_prlimit+0xd7/0x1d2
Mar 24 11:19:15 grep-r kernel: [<ffffffff8009ed78>] sys_setrlimit+0x36/0x43
Mar 24 11:19:15 grep-r kernel: [<ffffffff8005d116>] system_call+0x7e/0x83
Mar 24 11:19:15 grep-r kernel:
###############################
https://www.redhat.com/archives/rhelv5-list/2013-January/msg00009.html
| centos 5.9 64bit geoip iptables 설치 (0) | 2018.08.31 |
|---|---|
| 서버가 응답이 없어요..INfo:task <process>:<pid> lock for more than 120 seconds" 출처: http://ssambback.tistory.com/entry/서버가-응답이-없어요INfotask-processpid-lock-for-more-than-120-seconds [Rehoboth.. 이곳에서 부터] 출처.. (0) | 2018.08.31 |
| kill PID 여러개 한번에 죽이기 (0) | 2018.08.31 |
| curl 로 페이지 접속하는데 간헐적으로 느리면 (0) | 2018.08.31 |
| 히스토리, 명령어 저장등 script (0) | 2018.08.31 |
kill -9 $(ps -ef | grep "error\/warning check" | awk '{print $2}')
| 서버가 응답이 없어요..INfo:task <process>:<pid> lock for more than 120 seconds" 출처: http://ssambback.tistory.com/entry/서버가-응답이-없어요INfotask-processpid-lock-for-more-than-120-seconds [Rehoboth.. 이곳에서 부터] 출처.. (0) | 2018.08.31 |
|---|---|
| call trace 에러 (0) | 2018.08.31 |
| curl 로 페이지 접속하는데 간헐적으로 느리면 (0) | 2018.08.31 |
| 히스토리, 명령어 저장등 script (0) | 2018.08.31 |
| centos 6 xtables 설치시 에러 (0) | 2018.08.31 |
yum install -y ncdu
du보다 속도도 빠르고 디렉토리별로 나열해서 보기도 편하고 통파티션으로 설치된 리눅스에서 어디가 용량큰지 찾자고 계속 du 치고있ㅉ말자
| rpmforge (0) | 2018.08.31 |
|---|---|
| ssl 인즉서 적용 확인하는곳 (0) | 2018.08.31 |
| sed '/^\#/d' 파일 > 파일_주석제거된거 (0) | 2018.08.31 |
| 특정 프로세스 grep으로 찾아가지고 해당 프로세스들 $2 불러와서 kill 하기 (0) | 2018.08.31 |
| tee 명령어 (0) | 2018.08.31 |
Processor\%Processor Time : % Processor Time은 프로세서가 비유휴 스레드를 실행하는 데 소비하는 시간의 백분율입니다. 이것은 프로세서가 각 샘플 간격 동안 유휴 스레드를 실행하는 데 소비한 시간을 측정하여 간격 기간에서 그 값을 뺀 것입니다. 각 프로세서에는 유휴 스레드가 있는데 이것은 다른 어떤 스레드도 실행되지 않을 때 사이클을 소비하는 스레드입니다. 이 카운터는 프로세서 동작의 주요 표시기이며 샘플 간격 동안 관찰되는 사용 시간의 평균 백분율을 표시합니다. 이것은 서비스가 비활성인 시간을 모니터링하여 100%에서 그 값을 뺀 것입니다.
즉 쉽게 말해서, 1시간 동안 CPU상태를 관찰하였고, 1시간 중에서 30분간 CPU가 일을 하였다면, %Processor Time은 50% 입니다. 일반적으로 %Processor Time이 80%이상 사용되고 있으면, 관심을 가지고 사용량의 변화를 모니터하셔야 합니다.
Processor\%Privileged Time : % Privildged Time은 프로세스 스레드가 특권 모드에서 명령을 실행하면서 경과된 시간을 백분율로 표시한 것입니다. Windows 시스템 서비스가 호출되면, 서비스는 시스템 전용 데이터를 액세스하기 위해 흔히 특권 모드에서 실행됩니다. 그러한 데이터는 사용자 모드에서 실행되는 스레드가 액세스하지 못하도록 보호됩니다. 시스템 호출은 페이지 오류 또는 인터럽트가 발생할 때처럼 명시적이거나 암시적입니다. 일부 초기 운영 체제와는 달리 Windows는 사용자 및 특권 모드의 일반적인 보호뿐만 아니라 하위 시스템을 보호하기 위해 프로세스 경계를 사용합니다. 응용 프로그램을 대신하여 Windows에서 수행한 일부 작업은 프로세스의 특권 시간 및 다른 하위 시스템 프로세스에서도 나타납니다. 쉽게 말해서, 운영체제가 사용한 시간의 백분율 값입니다.
Memory\Available Bytes : Available Bytes는 컴퓨터에서 실행되는 프로세스에 사용할 수 있는 실제 메모리의 양(바이트)입니다. 이것은 0으로 채워 있거나 비어 있거나 대기 중인 메모리 목록에 있는 공간을 합해 계산합니다. 빈 메모리는 사용할 준비가 된 메모리이고, 0으로 채워진 메모리는 다음 프로세스가 이전 프로세스에서 사용된 데이터를 보지 못하도록 0으로 채운 메모리 페이지로 구성되며, 대기 메모리는 프로세스의 작업 집합(실제 메모리)에서 제거되어 디스크로 라우트되었지만 다시 호출되어 사용될 수 있는 메모리를 말합니다. 이 카운터는 최근에 관찰된 값만 표시하며 평균값은 아닙니다. 사용 가능한 여유 메모리는 많이 있으면 좋겠지만, 그렇지 않다면, 최소한 5Mbyte이상은 남아 있어야 합니다.
Memory\Page Faults/sec : Page Faults/sec는 프로세스가 사용하는 메모리 공간(Working Set)에 존재하지 않는 코드나, 데이터를 요청할 경우에 발생합니다. 이 때 요청된 코드나 데이터를 다른 메모리 공간에서 찾으면 Soft Page Fault라고 하며, 디스크에서 찾게되면 Hard Page Fault라고 합니다. Page Faults/sec은 초당 발생한 Soft Page Fault와 Hard Page Fault의 합입니다.
Soft Page Fault값은 Page Faults/sec값에서 Pages/sec값을 빼면 됩니다.
따라서, Page Faults/sec의 값은 작을수록 좋다고 말 할 수 있겠으며, 상황에 따라서 그 임계치는 다르므로, 평상시에 모니터하여 적정 값을 파악해 두셔야 합니다.
Memory\Pages/sec : Pages/sec는 하드 페이지 부재를 해결하기 위해 디스크에서 읽거나 디스크로 쓴 페이지의 비율입니다. 이것은 Memory\\Pages Input/sec과 Memory\\Pages Output/sec의 합입니다. 메모리 공간이 부족하게 되면, 디스크의 페이징 파일로 메모리의 내용을 옮겨서 메모리의 여유공간을 확보하여 사용하게 되며, 또 필요 시 페이징 파일에서 데이터를 메모리로 로드하여 처리하는 과정을 반복하게 되므로 성능이 저하되게 됩니다.
Pages/sec 카운터 값이 20이상 지속되면 메모리 이상을 의심해야 합니다.
PhysicalDisk\%Disk Read Time : 디스크가 읽기 작업을 수행한 시간의 백분율입니다.
PhysicalDisk\%Disk Write Time : 디스크가 쓰기 작업을 수행한 시간의 백분율입니다.
PhysicalDisk\%Disk Time : 디스크가 읽기 및 쓰기 작업을 수행한 시간의 백분율이며, 이 값은 Disk Read Time과 Disk Write Time의 합입니다.
PhysicalDisk\Avg. Disk Queue Length : 디스크의 읽기 및 쓰기 작업을 위해 대기중인 실제 디스크 큐 길이 입니다. 이 값은 디스크당 2를 초과하게 되면, 디스크 쪽 부하를 점검해야 합니다.
PhysicalDisk\Current Disk Queue Length : 현재 시점의 디스크 읽기 및 쓰기 작업을 위해 대기중인 디스크 큐 길이 입니다. 이 값 역시 2를 초과하면, 디스크 쪽 부하를 점검해야 합니다.
Network Interface\Current Bandwidth : 네트워크 인터페이스의 현재 대역폭입니다. 사용하는 네트워크 어댑터 카드의 지원 가능 대역이 100Mbps인 경우에 Current Bandwidth값이 10Mbps라면 네트워크 어댑터 카드의 속성 세팅이 잘못 되었을 가능성이 큽니다.
Network Interface\Packets Outbound Errors : 이 항목은 오류로 인해서 외부로 반출할 수 없는 패킷의 수를 나타냅니다.
Network Interface\Packets Received Errors : 이 항목은 상위 계층의 프로토콜로 전달되지 못하도록 하는 오류를 포함하고 있는 외부로부터 유입되는 패킷의 수를 나타냅니다.
Server\Bytes Total/sec : 이 항목은 초당 서버가 네트워크에서 주고 받은 바이트 수 입니다. 동일 네트워크에 존재하는 서버들의 각각의 Bytes Total/sec 합이 네트워크 대역폭보다 크다면, 네트워크 분리를 고려하셔야 합니다.
SQLServer:Buffer Manager\Buffer cache hit ratio : SQL서버가 데이터를 디스크에서 읽지 않고 버퍼 풀에서 찾은 페이지 비율입니다. 이 값은 90% 이상 유지되어야 하며, 대부분의 시스템에서 98% 정도 유지 됩니다. 이 값이 90보다 낮다면 버퍼 공간이 부족하다고 판단할 수 있습니다.
SQLServer:Buffer Manager\Page life expectancy : 이 항목은 페이지가 참조되지 않고 얼마나 오랫동안 버퍼에 존재할 수 있는가를 초 단위로 나타냅니다. 이 값이 300초 이하이면, 성능향상을 위해 SQL서버에 추가적인 버퍼 공간이 필요하다고 볼 수 있습니다.
SQLServer:Buffer Manager\Page reads/sec : 모든 데이터베이스에 대해서 발생한 물리적 데이터 페이지의 초당 읽기 수를 나타냅니다. 물리적 I/O는 상대적으로 비용이 많이 발생하므로, 더 큰 데이터 캐시를 사용하거나, 인덱스 및 쿼리를 효율적으로 작성하거나, 데이터베이스 모델링을 다시하여 물리적 I/O비용을 줄여야 합니다.
SQLServer:Buffer Manager\Stolen Page : 윈도우 시스템이 SQL서버가 아닌 다른 응용 프로그램의 요구를 충족시키기 위하여 얼마나 많은 페이지들이 SQL Server 데이터 캐시로부터 제거되었는지를 나타낸다. min Server memory를 지정하여 SQL서버가 지정한 만큼의 SQL서버 전용으로 메모리를 할당하게 할 수 있지만, 그 만큼 다른 프로그램이 적은 메모리로 운영되게 되므로 페이징이 발생하게 됩니다. 따라서 메모리 증설을 고려해야 합니다.
SQLServer:Databases\Log Flushes/sec : 초당 발생한 로그 플러시 수를 나타냅니다. 하나의 로그플러시는 하나의 트랜잭션이 커밋되어 로그 파일에 기록되는 것을 의미 합니다.
SQLServer:Databases\Transactions/sec : 선택한 데이터 베이스에서 발생한 초당 발생하는 트랜잭션 수를 나타냅니다.
SQLServer:General Statistics\User Connections : 시스템에 연결된 사용자 수를 나타냅니다.
SQL Server:Latches\Average Latch Wait Time(ms) : 요청된 래치에 대한 평균 래치 대기 시간(ms)
SQL Server:Latches\Latch Waits/sec : 즉시 서비스 될 수 없고 자원 해제를 위해 대기해야 하는 래치 요청 수
SQL Server: Locks\Average Wait Time(ms) : 리소스에 잠금을 걸기 위해 대기하였던 평균 시간(ms)을 나타냅니다.
SQL Server: Locks\Lock Timeouts/sec : 리소스에 잠금을 얻기 위해 대기하면서 타임 아웃된 잠금 요청 횟수를 나타냅니다.
SQL Server: Locks\Lock Waits/sec : 즉시 충족시킬 수 없고 잠금을 허가하기 위해서 호출자가 기다려야 하는 잠금 요청 수
SQL Server: Locks\Number of Deadlocks/sec : 교착 상태를 일으킨 잠금 요청 수
SQL Server: Memory Manager\Memory Grants Pending : 작업 영역 메모리 허가를 위해 대기하고 있는 현재의 프로세스 수
SQL Server: Memory Manager\Target Server Memory(KB) : SQL Server가 사용할 수 있는 전체 메모리 양
SQL Server: Memory Manager\Total Server Memory(KB) : SQL Server가 사용하고 있는 전체 메모리 양
SQL Server: SQL Statistics\Batch Requests/sec : 초당 요청 받은 SQL 배치 요청 수
SQL Server: SQL Statistics\SQL Compilations/sec : 초당 SQL Server가 SQL문을 컴파일 한 수
SQL Server: SQL Statistics\Re-Compilations/sec : 초당 SQL Server가 SQL문을 재 컴파일 한 수
출처
http://sqler.pe.kr/web_board/view_list.asp?id=919&read=8898&pagec=17&gotopage=17&block=1&part=myboard7&tip=
| 모니터링시 조치 방법 (0) | 2018.08.31 |
|---|---|
| 병목현상 점검 조치 (0) | 2018.08.31 |
 tail.exe
tail.exe