
데이터 소스
데이터소스는 테라폼이 사용자가 원하는 인프라 상태를 설정하기 위해 필요한 정보를 "인터넷에서 검색하는 키워드"와 같다고 볼 수 있습니다.
인프라 설정을 위한 정보: 테라폼은 클라우드 서비스나 서버, 네트워크 등 다양한 인프라 자원을 관리합니다. 이런 자원을 설정하려면 예를 들어 서버 크기, 리전, 네트워크 구성 등과 같은 정보가 필요합니다. 데이터소스는 이런 정보를 테라폼에 제공합니다.
외부 데이터의 활용: 데이터소스는 종종 외부 소스에서 정보를 가져올 수 있습니다. 예를 들어, 클라우드 제공업체의 가용 영역 정보나 이미 존재하는 리소스의 상태를 가져오는 데 사용될 수 있습니다.
설정의 유연성: 데이터소스를 사용하면 테라폼 설정을 더 유연하게 만들 수 있습니다. 즉, 특정 리전, 가용 영역, 또는 네트워크 구성을 하드 코딩하지 않고 데이터소스를 통해 동적으로 설정할 수 있습니다.
간단히 말하면, 데이터소스는 테라폼이 인프라 자원을 관리할 때 필요한 정보를 효과적으로 확보하는 방법으로 생각할 수 있으며, 이를 통해 테라폼 설정을 더 쉽게 관리하고 유연하게 만들 수 있습니다.
데이터 소스 블록의 구조:
데이터 소스 블록은 data 키워드로 시작하며, 이후에는 데이터 소스 유형을 정의합니다. 데이터 소스 유형은 프로바이더 이름과 해당 프로바이더에서 제공하는 특정 데이터 소스 유형을 나타내며 밑줄 (_)로 구분됩니다. 데이터 소스 유형을 정의한 후에는 데이터 소스 인스턴스에 대한 고유한 이름을 지정합니다. 이름은 리소스의 이름과 마찬가지로 중복되지 않아야 하며, 데이터 소스의 인스턴스를 식별하는 데 사용됩니다.
예를 들어, local 프로바이더에서 제공하는 파일 데이터 소스를 정의한 코드는 다음과 같습니다:
data "local_file" "example_file" {
filename = "${path.module}/abc.txt"
}이 코드에서 local_file은 데이터 소스 유형을 나타내고, example_file은 데이터 소스 인스턴스의 고유한 이름입니다.
데이터 소스 구성 인수:
데이터 소스 블록 내부의 중괄호 { } 안에는 데이터 소스 유형에 대한 구성 인수를 선언합니다. 이러한 구성 인수는 데이터 소스가 작동하는 데 필요한 정보를 제공합니다. 구성 인수의 이름과 값을 설정하여 데이터 소스를 구성합니다. 각 데이터 소스 유형은 지원하는 구성 인수가 다를 수 있으며, 해당 데이터 소스의 문서에서 확인할 수 있습니다.
메타 인수: 데이터 소스 블록에서는 몇 가지 메타 인수를 사용할 수 있습니다. 이러한 메타 인수를 사용하여 데이터 소스의 동작을 제어하거나 관리할 수 있습니다.
depends_on: 이 메타 인수를 사용하여 종속성을 선언할 수 있습니다. 종속성을 정의하면 데이터 소스가 의존하는 다른 리소스나 데이터 소스가 먼저 생성되도록 제어할 수 있습니다.
count: 이 메타 인수를 사용하여 데이터 소스를 여러 번 생성하고 동일한 데이터 소스 유형을 여러 번 사용할 수 있습니다. 예를 들어, 여러 파일에 대한 데이터 소스를 생성할 때 유용합니다.
variable "file_paths" {
type = list(string)
default = ["/path/to/file1.txt", "/path/to/file2.txt", "/path/to/file3.txt"]
}
data "local_file" "example_files" {
count = length(var.file_paths)
filename = var.file_paths[count.index]
}- count: count 메타 인수는 variable "file_paths"에 정의된 파일 경로 목록의 길이에 따라 데이터 소스 인스턴스를 여러 번 생성합니다. 각 데이터 소스 인스턴스는 다른 파일을 대상으로 하며, count.index를 사용하여 파일 경로를 선택합니다.
- variable "file_paths": 이 변수는 파일 경로를 포함하는 문자열 목록을 정의합니다. count 메타 인수에서 이 변수의 길이에 따라 데이터 소스를 생성합니다.
for_each: 이 메타 인수를 사용하여 map 또는 set 타입의 데이터 배열의 값을 기준으로 여러 데이터 소스 인스턴스를 생성할 수 있습니다. 이것은 동적으로 생성해야 하는 경우에 유용합니다.
variable "file_data" {
type = map(string)
default = {
file1 = "/path/to/file1.txt"
file2 = "/path/to/file2.txt"
file3 = "/path/to/file3.txt"
}
}
data "local_file" "example_files" {
for_each = var.file_data
filename = each.value
}- for_each: for_each 메타 인수를 사용하여 variable "file_data"에 정의된 파일 데이터 맵을 기반으로 데이터 소스 인스턴스를 생성합니다. 각 데이터 소스 인스턴스는 다른 파일을 대상으로 합니다. each.key와 each.value를 사용하여 파일 이름과 파일 경로를 선택합니다.
- variable "file_data": 이 변수는 파일 이름을 키로 사용하고 파일 경로를 값으로 가지는 맵을 정의합니다. for_each 메타 인수에서 이 변수의 맵을 기반으로 데이터 소스를 생성합니다.
lifecycle: 이 메타 인수를 사용하여 데이터 소스의 수명주기를 관리할 수 있습니다. 예를 들어, 데이터 소스를 업데이트하는 조건을 지정할 수 있습니다.
data "local_file" "example_file" {
filename = "/path/to/some/file.txt"
lifecycle {
create_before_destroy = true
}
}- lifecycle: lifecycle 메타 인수를 사용하여 데이터 소스의 수명주기를 관리할 수 있습니다. 이 예시에서는 create_before_destroy를 true로 설정하여 데이터 소스를 업데이트할 때 이전 데이터 소스를 먼저 생성한 다음 제거하는 방식으로 동작하도록 지정합니다. 이것은 데이터 소스를 안전하게 업데이트하는 데 사용될 수 있습니다.
입력 변수 (Input Variables)는 Terraform 코드 내에서 사용되며, 인프라 구성에 필요한 속성 값을 정의하는 데 사용됩니다. 이를 통해 코드를 변경하지 않고 여러 인프라를 생성할 수 있습니다.
변수를 정의하는 방법과 변수 유형, 유효성 검사 및 민감한 변수 처리에 대한 내용을 살펴보겠습니다.
1. 변수 선언 방식
변수는 variable 블록으로 정의됩니다. 이 블록은 다음과 같은 구조를 가집니다:
variable "<이름>" {
<인수> = <값>
}여기서 <이름>은 변수의 고유한 이름이며, 다른 코드에서 변수를 참조할 때 사용됩니다. 변수 블록 내에서는 변수의 데이터 유형, 설명, 기본값 등을 설정할 수 있습니다.
변수 정의 시 사용 가능한 메타인수
- default : 변수 값을 전달하는 여러 가지 방법을 지정하지 않으면 기본값이 전달됨, 기본값이 없으면 대화식으로 사용자에게 변수에 대한 정보를 물어봄
variable "region" {
type = string
default = "us-east-1"
}- type : 변수에 허용되는 값 유형 정의, string number bool list map set object tuple 와 유형을 지정하지 않으면 any 유형으로 간주
variable "instance_type" {
type = string
default = "t2.micro"
}- description : 입력 변수의 설명
variable "subnet_id" {
type = string
description = "The ID of the subnet where the resource will be deployed."
}- validation : 변수 선언의 제약조건을 추가해 유효성 검사 규칙을 정의
variable "port" {
type = number
validation {
condition = var.port >= 0 && var.port <= 65535
error_message = "Port number must be between 0 and 65535."
}
}- sensitive : 민감한 변수 값임을 알리고 테라폼의 출력문에서 값 노출을 제한 (암호 등 민감 데이터의 경우)
variable "password" {
type = string
sensitive = true
}- nullable : 변수에 값이 없어도 됨을 지정
variable "optional_variable" {
type = string
nullable = true
}
2. 변수 유형
Terraform에서는 여러 종류의 변수 유형을 지원합니다. 주요 변수 유형은 다음과 같습니다:
- string: 글자 유형
- number: 숫자 유형
- bool: true 또는 false
- list: 리스트 형태, 예를 들어 문자열 리스트
- map: 키-값 쌍으로 이루어진 맵
- set: 중복을 허용하지 않는 집합
- object: 복잡한 구조를 가진 객체
- tuple: 고정된 크기의 순서가 있는 집합=
변수 우선 순위
[우선순위 수준 1]: 직접 입력
가장 높은 우선순위를 가지며, 테라폼 실행 중에 직접 값을 입력할 수 있습니다.
[우선순위 수준 2]: 변수 블록의 기본값(Default)
변수를 정의할 때 기본값을 설정할 수 있습니다. 이 값은 다른 곳에서 값을 지정하지 않을 때 사용됩니다.
[우선순위 수준 3]: 환경 변수
시스템 환경 변수의 이름이 TF_VAR_로 시작하면 해당 변수 이름으로 값을 설정할 수 있습니다.
[우선순위 수준 4]: terraform.tfvars 파일
terraform.tfvars 파일에 변수 값을 저장할 수 있습니다. 이 파일은 코드와 같은 디렉터리에 있어야 합니다.
[우선순위 수준 5]: *.auto.tfvars 파일
코드와 같은 디렉터리에 있는 .auto.tfvars 확장자를 가진 파일에 변수 값을 저장할 수 있습니다. 파일명의 알파벳 순서로 우선순위가 정해집니다.
[우선순위 수준 6]: *.auto.tfvars.json 파일
코드와 같은 디렉터리에 있는 .auto.tfvars.json 확장자를 가진 JSON 파일에 변수 값을 저장할 수 있습니다. 파일명의 알파벳 순서로 우선순위가 정해집니다.
[우선순위 수준 7]: CLI 실행 시 -var 인수 또는 -var-file 옵션
테라폼 명령어를 실행할 때 -var 옵션을 사용하여 변수 값을 전달할 수 있습니다. 이 옵션으로 변수 값을 지정하면 다른 모든 우선순위를 덮어씁니다. 또한 -var-file 옵션을 사용하여 변수 값이 정의된 파일을 지정할 수도 있습니다.
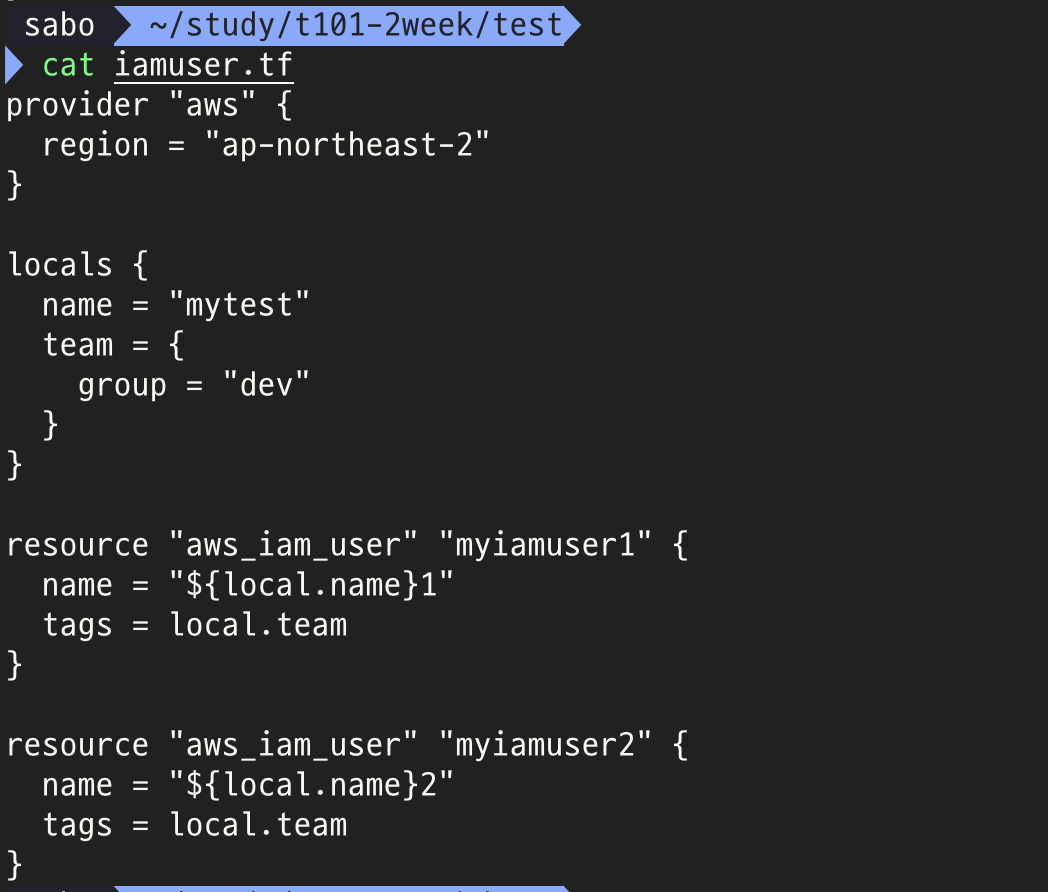
locals란
**로컬(local)**은 마치 여러분이 노트에 어떤 계산을 해서 그 값을 기억해두는 것과 비슷합니다. 그러면 필요할 때마다 그 값을 다시 불러와 사용할 수 있습니다.
로컬을 사용하는 이유는 여러 번 반복해서 사용하는 값을 효율적으로 다루기 위해서입니다. 예를 들어, 여러 리소스를 만들 때 사용하는 이름이나 설정 값 등을 한 번 정해놓고 필요할 때마다 그 값을 가져와서 사용할 수 있습니다.
로컬은 테라폼 코드 내에서만 사용되며, 사용자나 외부로부터 입력을 받지 않습니다. 코드 내에서 미리 정의되어 있어서 다른 사람이 코드를 읽을 때 무엇을 의미하는지 쉽게 파악할 수 있게 해줍니다.
로컬 값을 사용하기 위해서는 코드 내에서 locals라는 블록을 사용합니다. 그 안에서 로컬 변수의 이름과 그 변수에 할당할 값을 정의합니다.
로컬 값을 참조할 때는 local.<이름> 형식을 사용하며, 다른 테라폼 코드 파일에서도 사용할 수 있습니다. 이렇게 하면 여러 코드 파일 간에 값을 공유하거나 재사용할 수 있습니다.
로컬 값은 코드의 가독성을 높이고 반복 작업을 줄이는 데 도움을 줍니다. 그러나 로컬 값을 과도하게 사용하면 코드를 이해하기 어려워질 수 있으므로 적절하게 활용해야 합니다.


반복문
count : 반복문, 정수 값만큼 리소스나 모듈을 생성
resource "aws_instance" "example" {
count = 3 # 세 개의 EC2 인스턴스 생성
ami = "ami-0c55b159cbfafe1f0"
instance_type = "t2.micro"
}위 예제에서는 count를 사용하여 세 개의 EC2 인스턴스를 생성합니다. 각 인스턴스는 동일한 AMI 및 인스턴스 유형을 가지고 있습니다.
for_each : 반복문, 선언된 key 값 개수만큼 리소스를 생성
variable "servers" {
type = map
default = {
web = "ami-12345678"
app = "ami-87654321"
database = "ami-abcd1234"
}
}
resource "aws_instance" "example" {
for_each = var.servers
ami = each.value
instance_type = "t2.micro"
tags = {
Name = each.key
}
}위 예제에서는 for_each를 사용하여 var.servers 맵을 기반으로 EC2 인스턴스를 생성합니다. 각 인스턴스는 고유한 AMI 및 이름을 가지고 있습니다.
for_each는 테라폼에서 사용되는 반복문 중 하나로, 이것을 이해하는 데 비유를 들어보겠습니다. 생각해보세요. 여러분이 서로 다른 지역에 있는 친구들과 휴가를 가고 싶다고 상상해보세요. 각 친구마다 서로 다른 여행지와 일정을 가지고 있습니다. 이때 for_each는 여러분이 이런 상황에서 사용할 수 있는 가상의 "여행 일정부표"와 같다고 생각할 수 있습니다. 이 부표에는 여러 친구들의 여행 정보가 기록되어 있습니다. 친구 A: 파리로 5일간 친구 B: 도쿄로 7일간 친구 C: 뉴욕으로 4일간 for_each를 사용하면, 이 "여행 일정부표"를 보고 테라폼이 각 친구에게 해당하는 여행지와 기간에 맞게 여행 예약을 생성할 수 있습니다. 여기서 for_each는 각 친구를 나타내는 항목을 하나씩 가져와서 여행 예약을 만듭니다. 다시 말해, for_each를 사용하면 여러분이 가진 데이터를 기반으로 여러 개의 리소스나 설정을 자동으로 생성할 수 있습니다. 이것은 반복 작업을 자동화하고, 설정을 더 효과적으로 관리하는 데 도움이 됩니다. 그러니까, for_each는 여러분이 가진 여러 데이터를 기반으로 여러 가지 작업을 자동으로 반복 수행하는 도구라고 생각하시면 됩니다.
for : 복합 형식 값의 형태를 변환하는 데 사용 ← for_each와 다름
variable "numbers" {
type = list
default = [1, 2, 3, 4, 5]
}
locals {
squared_numbers = [for num in var.numbers : num * num]
}위 예제에서는 for를 사용하여 var.numbers 리스트의 각 요소를 제곱한 새로운 리스트를 만듭니다.
for는 반복문의 일종으로, 특정 작업을 여러 번 반복할 때 사용됩니다. 이것을 비유하자면, 여러분이 같은 일을 여러 번 반복하는 상황과 비슷합니다. 예를 들어, 여러분이 동일한 메시지를 여러 사람에게 보내야 한다고 상상해보세요. for를 사용하면 메시지 내용을 작성한 후, 그 메시지를 여러 명의 친구나 동료에게 보내는 작업을 반복적으로 수행할 수 있습니다.
반면에, for_each는 데이터를 기반으로 리소스나 설정을 여러 번 생성하는 데 사용됩니다. 비유로 설명하자면, 여러분이 서로 다른 여행 일정을 가진 여러 명의 친구들이 있다고 상상해보세요. 각 친구의 여행 정보는 다르기 때문에, for_each를 사용하여 각각의 여행 일정에 대한 예약을 생성할 수 있습니다.
간단히 말해서, for는 같은 작업을 반복하는 데 사용되고, for_each는 데이터를 기반으로 여러 가지 작업을 반복해서 리소스를 생성하는 데 사용됩니다. 이 둘은 서로 다른 상황에서 사용되며, 각각의 목적에 맞게 선택적으로 테라폼 코드 내에서 사용할 수 있습니다.
dynamic : 리소스 내부 속성 블록을 동적인 블록으로 생성
variable "ports" {
type = list
default = [80, 443, 8080]
}
resource "aws_security_group" "example" {
name_prefix = "example-"
dynamic "ingress" {
for_each = var.ports
content {
from_port = ingress.value
to_port = ingress.value
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
}
}위 예제에서는 dynamic 블록을 사용하여 다양한 포트 번호로 AWS 보안 그룹의 인바운드 규칙을 동적으로 생성합니다. 이를 통해 여러 포트에 대한 보안 그룹 규칙을 간편하게 정의할 수 있습니다.
ami-04a7c24c015ef1e4c
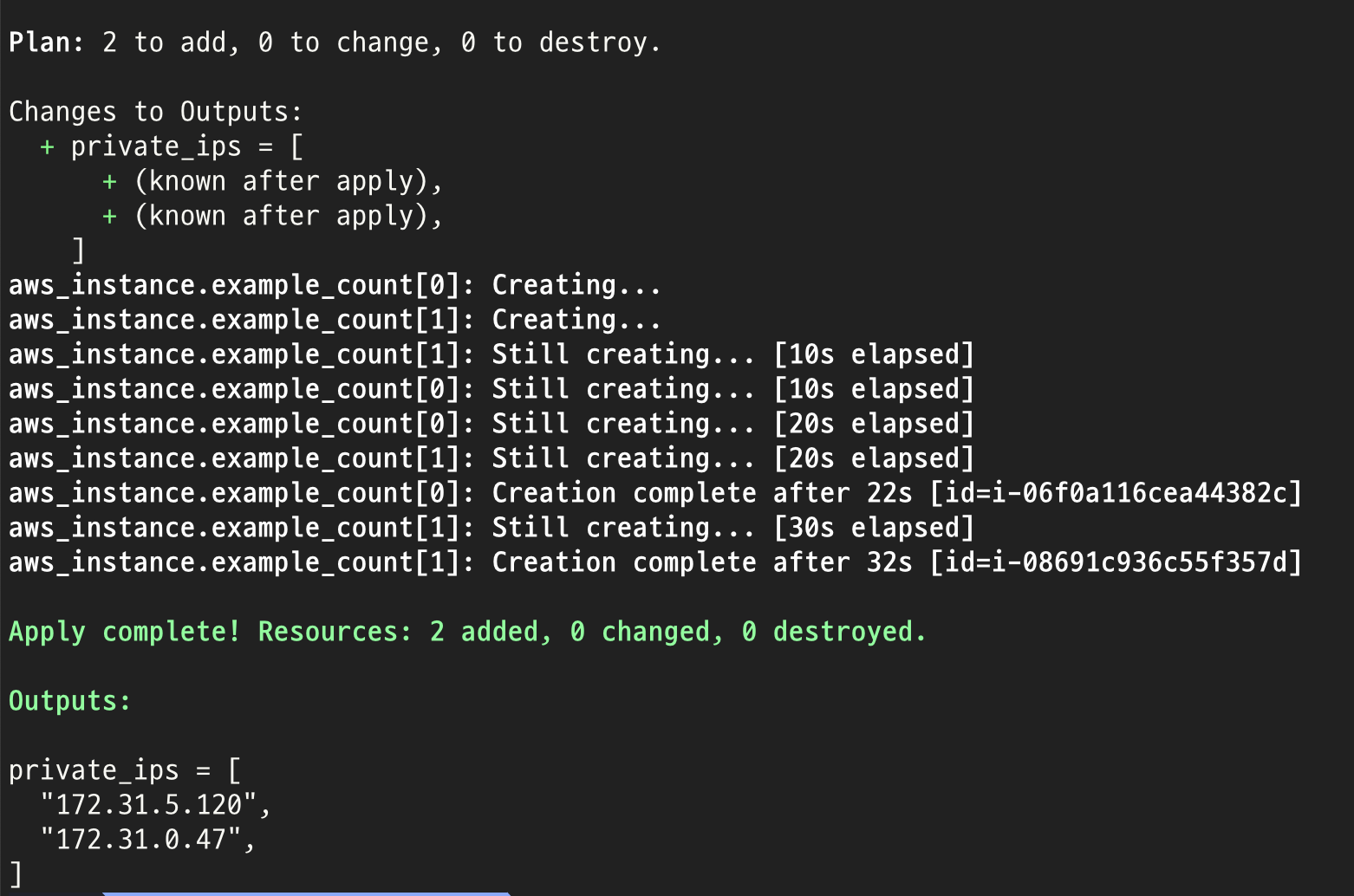
count 실습


for_each 실습



for 실습


