4주차는 EKS observability 이다.
시작.
로깅 대상은 컨트롤 플레인, node, 애플리케이션이 있다.
먼저 컨트롤 플레인 로깅이다.

현재 모든 로깅은 꺼져있는 상태
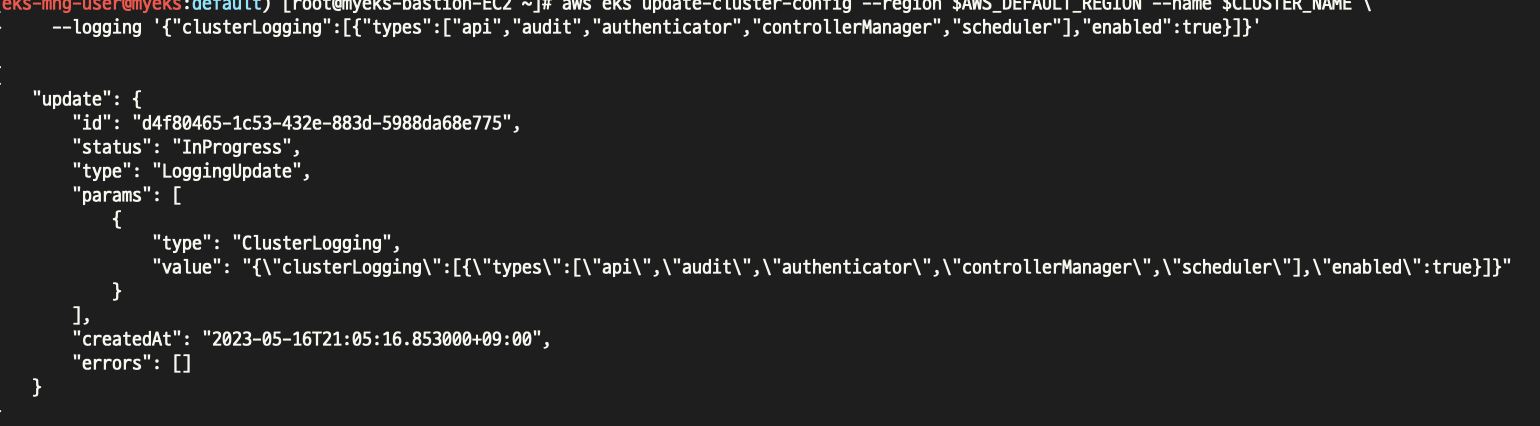
위와같이 enable 해주면

On 확인
# EC2 Instance가 NodeNotReady 상태인 로그 검색
fields @timestamp, @message
| filter @message like /**NodeNotReady**/
| sort @timestamp desc
# kube-apiserver-audit 로그에서 userAgent 정렬해서 아래 4개 필드 정보 검색
fields userAgent, requestURI, @timestamp, @message
| filter @logStream ~= "kube-apiserver-audit"
| stats count(userAgent) as count by userAgent
| sort count desc
#
fields @timestamp, @message
| filter @logStream ~= "**kube-scheduler**"
| sort @timestamp desc
#
fields @timestamp, @message
| filter @logStream ~= "**authenticator**"
| sort @timestamp desc
#
fields @timestamp, @message
| filter @logStream ~= "kube-controller-manager"
| sort @timestamp desc

log insights 에서 필터링하여 로그를 확인할수 있다.
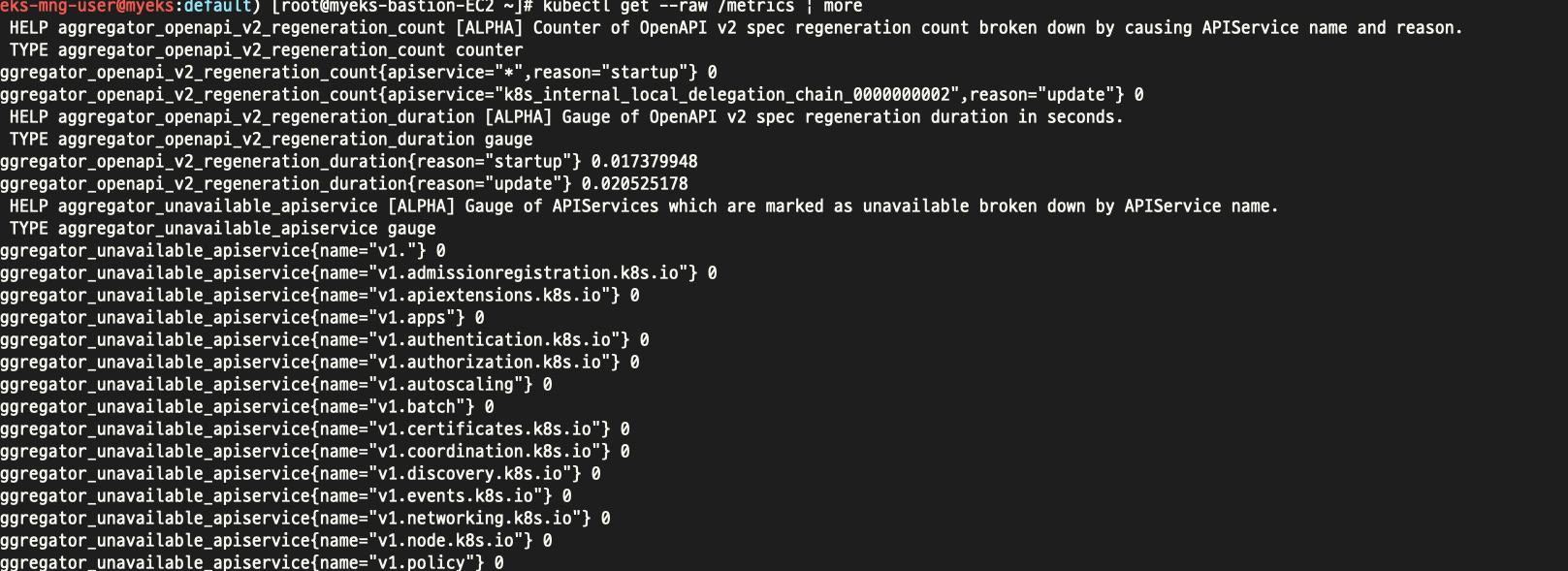
위와같이 프로메테우스 메트릭 형태로도 볼수있다.
그외에도 아래 내용을 참고하여 컨트롤플래인단 로그를 확인할수 있다.
# How to monitor etcd database size? >> 아래 10.0.X.Y IP는 어디일까요? >> 아래 주소로 프로메테우스 메트릭 수집 endpoint 주소로 사용 가능한지???
**kubectl get --raw /metrics | grep "etcd_db_total_size_in_bytes"**
etcd_db_total_size_in_bytes{endpoint="<http://10.0.160.16:2379>"} 4.665344e+06
etcd_db_total_size_in_bytes{endpoint="<http://10.0.32.16:2379>"} 4.636672e+06
etcd_db_total_size_in_bytes{endpoint="<http://10.0.96.16:2379>"} 4.640768e+06
**kubectl get --raw=/metrics | grep apiserver_storage_objects |awk '$2>100' |sort -g -k 2**
# CW Logs Insights 쿼리
fields @timestamp, @message, @logStream
| filter @logStream like /**kube-apiserver-audit**/
| filter @message like /**mvcc: database space exceeded**/
| limit 10
# How do I identify what is consuming etcd database space?
**kubectl get --raw=/metrics | grep apiserver_storage_objects |awk '$2>100' |sort -g -k 2**
**kubectl get --raw=/metrics | grep apiserver_storage_objects |awk '$2>50' |sort -g -k 2**
apiserver_storage_objects{resource="clusterrolebindings.rbac.authorization.k8s.io"} 78
apiserver_storage_objects{resource="clusterroles.rbac.authorization.k8s.io"} 92
# CW Logs Insights 쿼리 : Request volume - Requests by User Agent:
fields userAgent, requestURI, @timestamp, @message
| filter @logStream like /**kube-apiserver-audit**/
| stats count(*) as count by userAgent
| sort count desc
# CW Logs Insights 쿼리 : Request volume - Requests by Universal Resource Identifier (URI)/Verb:
filter @logStream like /**kube-apiserver-audit**/
| stats count(*) as count by requestURI, verb, user.username
| sort count desc
# Object revision updates
fields requestURI
| filter @logStream like /**kube-apiserver-audit**/
| filter requestURI like /pods/
| filter verb like /patch/
| filter count > 8
| stats count(*) as count by requestURI, responseStatus.code
| filter responseStatus.code not like /500/
| sort count desc
#
fields @timestamp, userAgent, responseStatus.code, requestURI
| filter @logStream like /**kube-apiserver-audit**/
| filter requestURI like /pods/
| filter verb like /patch/
| filter requestURI like /name_of_the_pod_that_is_updating_fast/
| sort @timestamp
이번엔 컨테이너 로깅이다..
# NGINX 웹서버 **배포**
helm repo add bitnami <https://charts.bitnami.com/bitnami>
# 사용 리전의 인증서 ARN 확인
CERT_ARN=$(aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text)
echo $CERT_ARN
# 도메인 확인
echo $MyDomain
# 파라미터 파일 생성
cat < nginx-values.yaml
service:
type: NodePort
ingress:
enabled: true
ingressClassName: alb
hostname: nginx.$MyDomain
path: /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
**alb.ingress.kubernetes.io/load-balancer-name: $CLUSTER_NAME-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'**
EOT
cat nginx-values.yaml | yh
# 배포
**helm install nginx bitnami/nginx --version 14.1.0 -f nginx-values.yaml**
# 확인
kubectl get ingress,deploy,svc,ep nginx
kubectl get targetgroupbindings # ALB TG 확인
# 접속 주소 확인 및 접속
echo -e "Nginx WebServer URL = "
curl -s
kubectl logs deploy/nginx -f
# 반복 접속
while true; do curl -s -I | head -n 1; date; sleep 1; done
# (참고) 삭제 시
helm uninstall nginx
위와같이 진행한다. 다만 ACM 은 인증서 따로 추가해줘야 한다.
CERT_ARN=$(aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text) echo $CERT_ARN
이부분

위와같이 배포 완료

컨테이너도 위와같이 로깅을 확인할수있다.
이번에는 외부에서 로그를 수집하도록 하는 방법이다.

# 설치
FluentBitHttpServer='On'
FluentBitHttpPort='2020'
FluentBitReadFromHead='Off'
FluentBitReadFromTail='On'
**curl -s <https://raw.githubusercontent.com/aws-samples/amazon-cloudwatch-container-insights/latest/k8s-deployment-manifest-templates/deployment-mode/daemonset/container-insights-monitoring/quickstart/cwagent-fluent-bit-quickstart.yaml> | sed 's/{{cluster_name}}/'${CLUSTER_NAME}'/;s/{{region_name}}/'${AWS_DEFAULT_REGION}'/;s/{{http_server_toggle}}/"'${FluentBitHttpServer}'"/;s/{{http_server_port}}/"'${FluentBitHttpPort}'"/;s/{{read_from_head}}/"'${FluentBitReadFromHead}'"/;s/{{read_from_tail}}/"'${FluentBitReadFromTail}'"/' | kubectl apply -f -**
# 설치 확인
kubectl get-all -n amazon-cloudwatch
kubectl get ds,pod,cm,sa -n amazon-cloudwatch
kubectl describe **clusterrole cloudwatch-agent-role fluent-bit-role** # 클러스터롤 확인
kubectl describe **clusterrolebindings cloudwatch-agent-role-binding fluent-bit-role-binding** # 클러스터롤 바인딩 확인
kubectl -n amazon-cloudwatch logs -l name=cloudwatch-agent -f # 파드 로그 확인
kubectl -n amazon-cloudwatch logs -l k8s-app=fluent-bit -f # 파드 로그 확인
for node in $N1 $N2 $N3; do echo ">>>>> $node <<<<<"; ssh ec2-user@$node sudo ss -tnlp | grep fluent-bit; echo; done
# cloudwatch-agent 설정 확인
**kubectl describe cm cwagentconfig -n amazon-cloudwatch**
{
"agent": {
"region": "ap-northeast-2"
},
"logs": {
"metrics_collected": {
"kubernetes": {
"cluster_name": "myeks",
"metrics_collection_interval": 60
}
},
"force_flush_interval": 5
}
}
# CW 파드가 수집하는 방법 : Volumes에 HostPath를 살펴보자! >> / 호스트 패스 공유??? 보안상 안전한가? 좀 더 범위를 좁힐수는 없을까요?
**kubectl describe -n amazon-cloudwatch ds cloudwatch-agent**
...
ssh ec2-user@$N1 sudo tree /dev/disk
...
# Fluent Bit Cluster Info 확인
**kubectl get cm -n amazon-cloudwatch fluent-bit-cluster-info -o yaml | yh**
apiVersion: v1
data:
cluster.name: myeks
http.port: "2020"
http.server: "On"
logs.region: ap-northeast-2
read.head: "Off"
read.tail: "On"
kind: ConfigMap
...
# Fluent Bit 로그 INPUT/FILTER/OUTPUT 설정 확인 - [링크](<https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/Container-Insights-setup-logs-FluentBit.html#ContainerInsights-fluentbit-multiline>)
## 설정 부분 구성 : application-log.conf , dataplane-log.conf , fluent-bit.conf , host-log.conf , parsers.conf
**kubectl describe cm fluent-bit-config -n amazon-cloudwatch
...
application-log.conf**:
----
[**INPUT**]
Name tail
Tag **application.***
Exclude_Path /var/log/containers/cloudwatch-agent*, /var/log/containers/fluent-bit*, /var/log/containers/aws-node*, /var/log/containers/kube-proxy*
**Path /var/log/containers/*.log**
multiline.parser docker, cri
DB /var/fluent-bit/state/flb_container.db
Mem_Buf_Limit 50MB
Skip_Long_Lines On
Refresh_Interval 10
Rotate_Wait 30
storage.type filesystem
Read_from_Head ${READ_FROM_HEAD}
[**FILTER**]
Name kubernetes
Match application.*
Kube_URL <https://kubernetes.default.svc:443>
Kube_Tag_Prefix application.var.log.containers.
Merge_Log On
Merge_Log_Key log_processed
K8S-Logging.Parser On
K8S-Logging.Exclude Off
Labels Off
Annotations Off
Use_Kubelet On
Kubelet_Port 10250
Buffer_Size 0
[**OUTPUT**]
Name cloudwatch_logs
Match application.*
region ${AWS_REGION}
**log_group_name /aws/containerinsights/${CLUSTER_NAME}/application**
log_stream_prefix ${HOST_NAME}-
auto_create_group true
extra_user_agent container-insights
**...**
# Fluent Bit 파드가 수집하는 방법 : Volumes에 HostPath를 살펴보자!
**kubectl describe -n amazon-cloudwatch ds fluent-bit**
...
ssh ec2-user@$N1 sudo tree /var/log
...
# (참고) 삭제
curl -s <https://raw.githubusercontent.com/aws-samples/amazon-cloudwatch-container-insights/latest/k8s-deployment-manifest-templates/deployment-mode/daemonset/container-insights-monitoring/quickstart/cwagent-fluent-bit-quickstart.yaml> | sed 's/{{cluster_name}}/'${CLUSTER_NAME}'/;s/{{region_name}}/'${AWS_DEFAULT_REGION}'/;s/{{http_server_toggle}}/"'${FluentBitHttpServer}'"/;s/{{http_server_port}}/"'${FluentBitHttpPort}'"/;s/{{read_from_head}}/"'${FluentBitReadFromHead}'"/;s/{{read_from_tail}}/"'${FluentBitReadFromTail}'"/' | kubectl delete -f -
우선 위와같이 설치를 진행한다.

정상적으로 설치 완료

위와같이 fluent bit로 어떻게 가공 과정을 볼수있다.
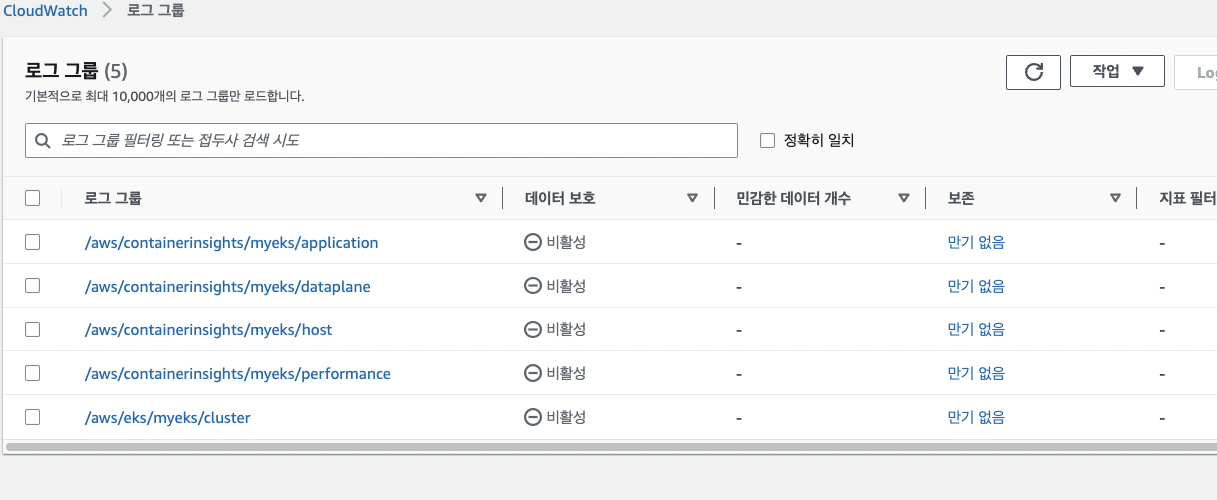

콘솔에서도 로그 확인

Insights 항목에서도 여러 항목 모니터링 가능
이번에는 모니터링을하기위한 메트릭수집 도구들을 알아볼것이다.

# 배포
**kubectl apply -f <https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml**>
# 메트릭 서버 확인 : 메트릭은 15초 간격으로 cAdvisor를 통하여 가져옴
kubectl get pod -n kube-system -l k8s-app=metrics-server
kubectl api-resources | grep metrics
kubectl get apiservices |egrep '(AVAILABLE|metrics)'
# 노드 메트릭 확인
kubectl top node
# 파드 메트릭 확인
kubectl top pod -A
kubectl top pod -n kube-system --sort-by='cpu'
kubectl top pod -n kube-system --sort-by='memory'
메트릭서버 설치방법(만 알아본다.)
kwatch라는것도 있다. 이걸로 slack 웹훅을 걸어줄수있다.
# configmap 생성
cat < ~/kwatch-config.yaml
apiVersion: v1
kind: Namespace
metadata:
name: kwatch
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kwatch
namespace: kwatch
data:
config.yaml: |
**alert**:
**slack**:
webhook: '**<https://hooks.slack.com/services/T03G23CRBNZ/sssss/sss**>'
title: $NICK-EKS
#text:
**pvcMonitor**:
enabled: true
interval: 5
threshold: 70
EOT
**kubectl apply -f kwatch-config.yaml**
# 배포
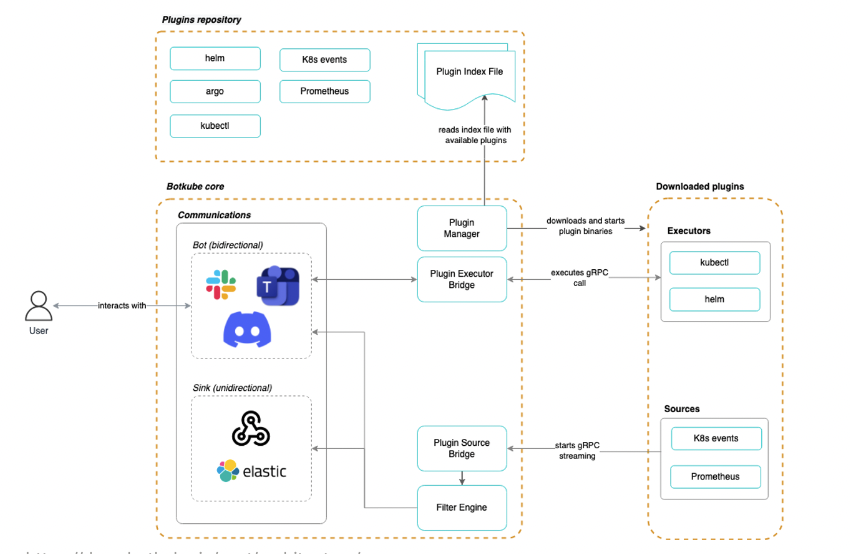
kubectl apply -f <https://raw.githubusercontent.com/abahmed/kwatch/v0.8.3/deploy/**deploy.yaml**>botube라는 도구도 있다.
# repo 추가
helm repo add botkube <https://charts.botkube.io>
helm repo update
# 변수 지정
export ALLOW_KUBECTL=true
export ALLOW_HELM=true
export SLACK_CHANNEL_NAME=webhook3
#
cat < botkube-values.yaml
actions:
'describe-created-resource': # kubectl describe
enabled: true
'show-logs-on-error': # kubectl logs
enabled: true
executors:
k8s-default-tools:
botkube/helm:
enabled: true
botkube/kubectl:
enabled: true
EOT
# 설치
helm install --version **v1.0.0** botkube --namespace botkube --create-namespace \\
--set communications.default-group.socketSlack.enabled=true \\
--set communications.default-group.socketSlack.channels.default.name=${SLACK_CHANNEL_NAME} \\
--set communications.default-group.socketSlack.appToken=${SLACK_API_APP_TOKEN} \\
--set communications.default-group.socketSlack.botToken=${SLACK_API_BOT_TOKEN} \\
--set settings.clusterName=${CLUSTER_NAME} \\
--set 'executors.k8s-default-tools.botkube/kubectl.enabled'=${ALLOW_KUBECTL} \\
--set 'executors.k8s-default-tools.botkube/helm.enabled'=${ALLOW_HELM} \\
-f **botkube-values.yaml** botkube/botkube
# 참고 : 삭제 시
helm uninstall botkube --namespace botkube
# 연결 상태, notifications 상태 확인
**@Botkube** ping
**@Botkube** status notifications
# 파드 정보 조회
**@Botkube** k get pod
**@Botkube** kc get pod --namespace kube-system
**@Botkube** kubectl get pod --namespace kube-system -o wide
# Actionable notifications
**@Botkube** kubectl
botkube의 장점은 슬랙과 연동하여 @Botkube로 슬랙의 지정채널에서 파드의 정보를 불러오는등 슬랙에서 클러스터 정보 확인이 가능한장점이 있다.
자 이제 마지막으로 프로메테우스&그라파나이다.
프로메테우스 오퍼레이터 : 프로메테우스 및 프로메테우스 오퍼레이터를 이용하여 메트릭 수집과 알람 기능 실습
https://malwareanalysis.tistory.com/566
Thanos 타노드 : 프로메테우스 확장성과 고가용성 제공
https://hanhorang31.github.io/post/pkos2-4-monitoring/
프로메테우스란
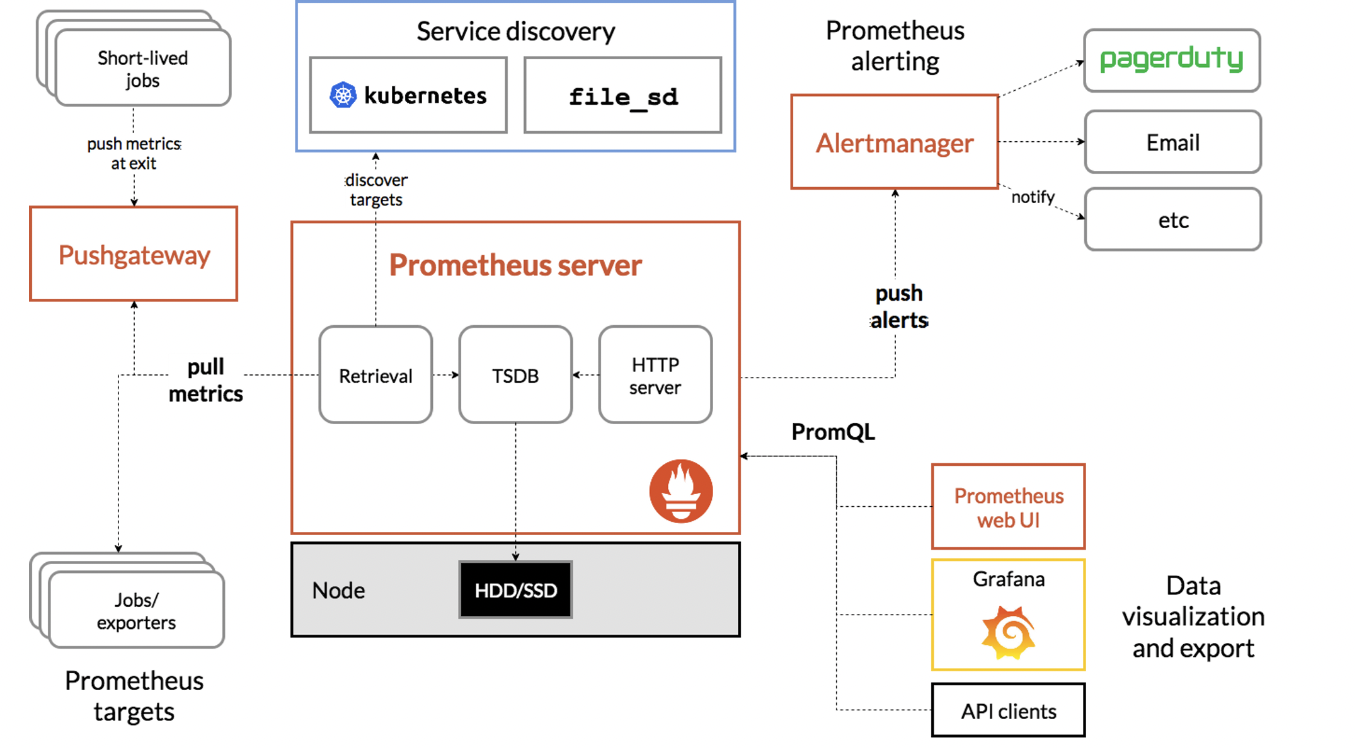
제공 기능
- a multi-dimensional data model with time series data(=TSDB, 시계열 데이터베이스) identified by metric name and key/value pairs
- PromQL, a flexible query language to leverage this dimensionality
- no reliance on distributed storage; single server nodes are autonomous
- time series collection happens via a pull model over HTTP
- pushing time series is supported via an intermediary gateway
- targets are discovered via service discovery or static configuration
- multiple modes of graphing and dashboarding support
설치 방법은 아래와 같다.
# 모니터링
kubectl create ns monitoring
watch kubectl get pod,pvc,svc,ingress -n monitoring
# 사용 리전의 인증서 ARN 확인
CERT_ARN=`aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text`
echo $CERT_ARN
****# repo 추가
helm repo add prometheus-community <https://prometheus-community.github.io/helm-charts>
# 파라미터 파일 생성
cat < monitor-values.yaml
**prometheus**:
prometheusSpec:
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
ingress:
enabled: true
ingressClassName: alb
hosts:
- prometheus.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
**alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'**
**grafana**:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
hosts:
- grafana.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
**alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'**
defaultRules:
create: false
**kubeControllerManager:
enabled: false
kubeEtcd:
enabled: false
kubeScheduler:
enabled: false**
alertmanager:
enabled: false
# alertmanager:
# ingress:
# enabled: true
# ingressClassName: alb
# hosts:
# - alertmanager.$MyDomain
# paths:
# - /*
# annotations:
# alb.ingress.kubernetes.io/scheme: internet-facing
# alb.ingress.kubernetes.io/target-type: ip
# alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
# alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
# alb.ingress.kubernetes.io/success-codes: 200-399
# alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
# alb.ingress.kubernetes.io/group.name: study
# alb.ingress.kubernetes.io/ssl-redirect: '443'
EOT
cat monitor-values.yaml | yh
# 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version **45.**27.2 \\
--**set** prometheus.prometheusSpec.scrapeInterval='15s' --**set** prometheus.prometheusSpec.evaluationInterval='15s' \\
-f **monitor-values.yaml** --namespace monitoring
# 확인
~~## alertmanager-0 : 사전에 정의한 정책 기반(예: 노드 다운, 파드 Pending 등)으로 시스템 경고 메시지를 생성 후 경보 채널(슬랙 등)로 전송~~
## grafana : 프로메테우스는 메트릭 정보를 저장하는 용도로 사용하며, 그라파나로 시각화 처리
## prometheus-0 : 모니터링 대상이 되는 파드는 ‘exporter’라는 별도의 사이드카 형식의 파드에서 모니터링 메트릭을 노출, pull 방식으로 가져와 내부의 시계열 데이터베이스에 저장
## node-exporter : 노드익스포터는 물리 노드에 대한 자원 사용량(네트워크, 스토리지 등 전체) 정보를 메트릭 형태로 변경하여 노출
## operator : 시스템 경고 메시지 정책(prometheus rule), 애플리케이션 모니터링 대상 추가 등의 작업을 편리하게 할수 있게 CRD 지원
## kube-state-metrics : 쿠버네티스의 클러스터의 상태(kube-state)를 메트릭으로 변환하는 파드
helm list -n monitoring
kubectl get pod,svc,ingress -n monitoring
kubectl get-all -n monitoring
**kubectl get prometheus,servicemonitors -n monitoring**
~~~~**kubectl get crd | grep monitoring**
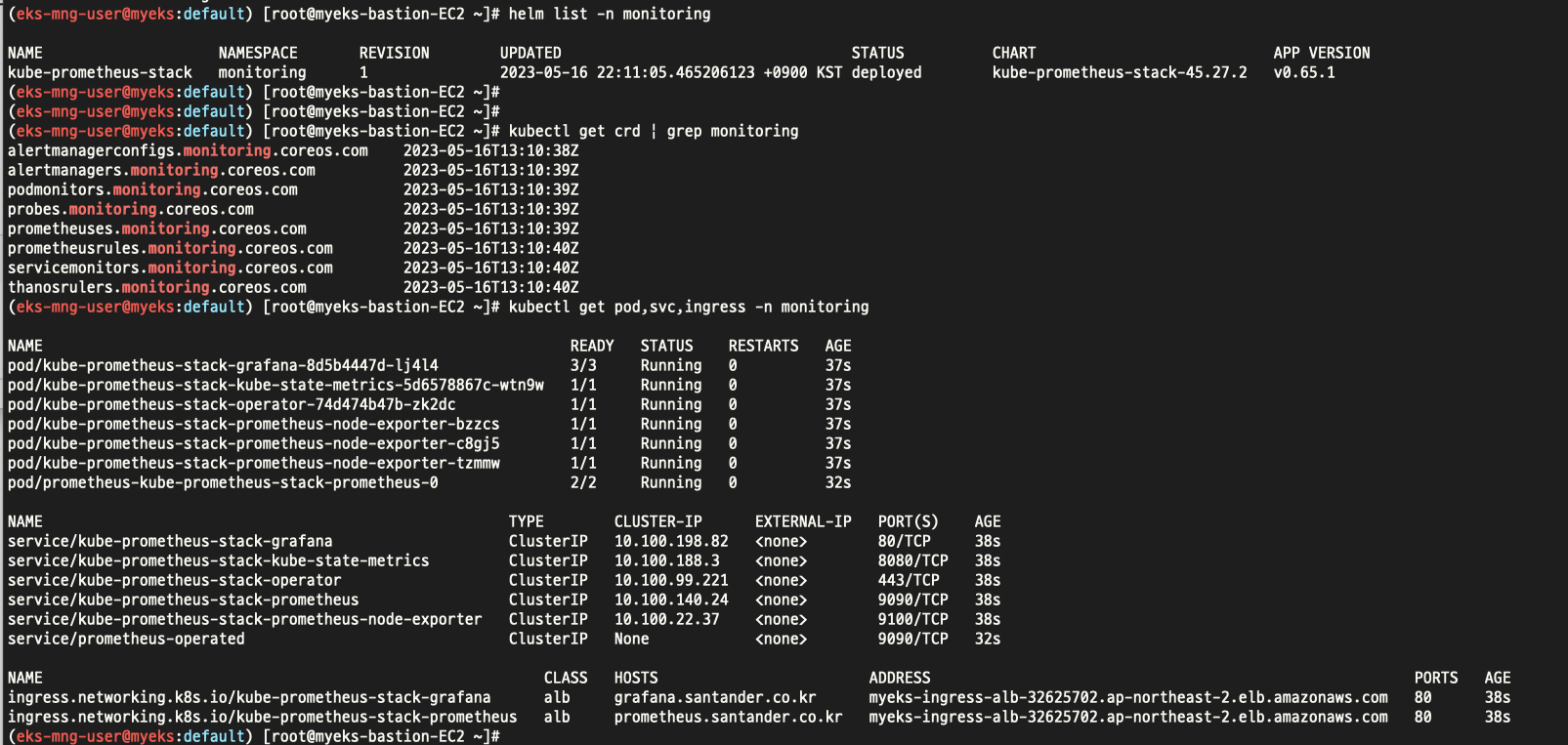
위와같이 설치 완료
프로메테우스 메트릭 수집정보를 확인해보자.

노드의 정보를 가져오는 노드 익스포터라는 파드가 올라온것을 확인할수있다.

위 메트릭들을 수집한다.
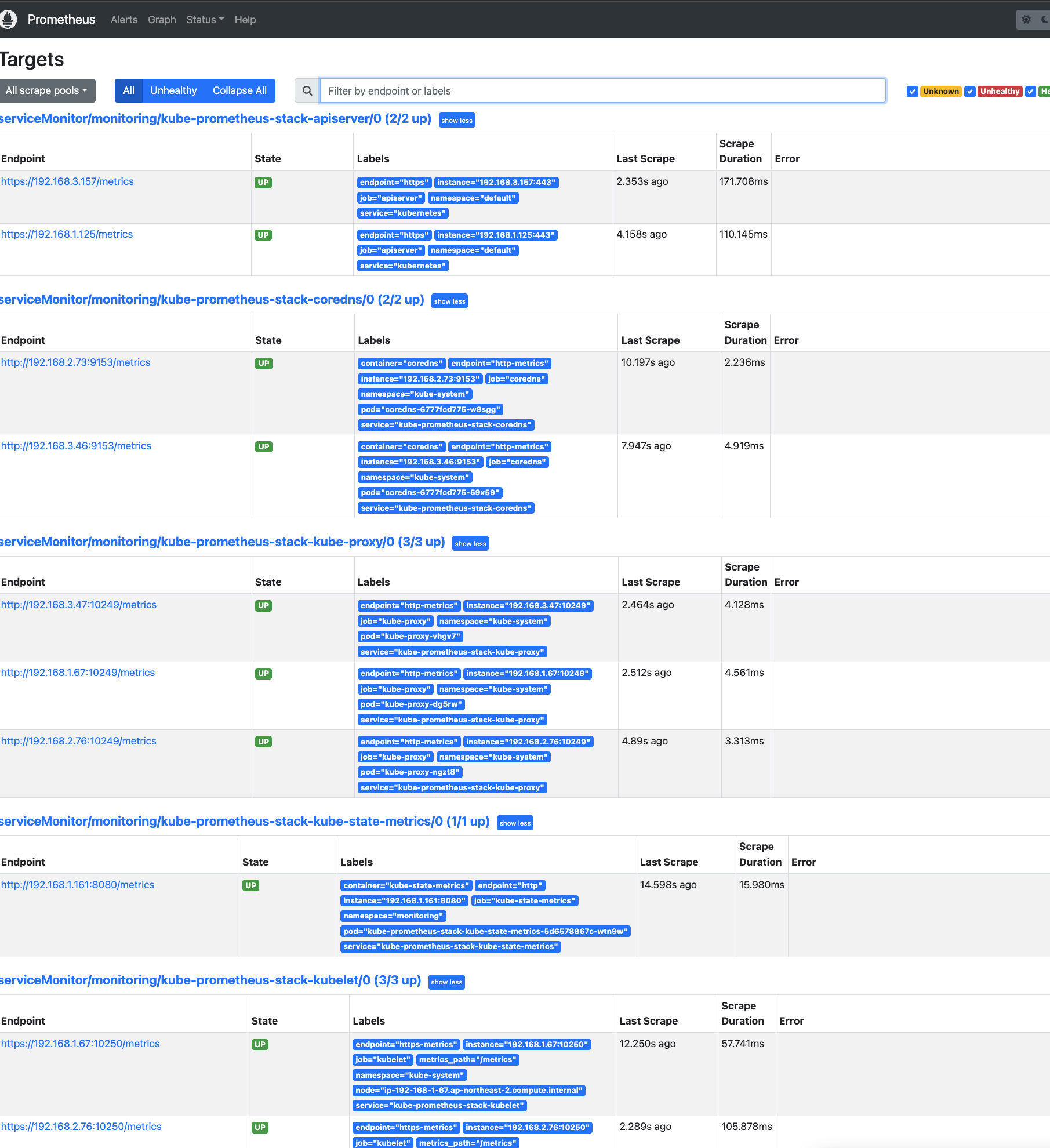
프로메테우스가 수집할 타겟들

아까 봤떤 노드 익스포터
그라파나 확인

다른 사용자가 만들어둔 여러가지 대시보드들이 있다.
- [Kubernetes / Views / Global] Dashboard → New → Import → 15757 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
- [1 Kubernetes All-in-one Cluster Monitoring KR] Dashboard → New → Import → 13770 or 17900 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
- [Node Exporter Full] Dashboard → New → Import → 1860 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
- kube-state-metrics-v2 가져와보자 : Dashboard ID copied! (13332) 클릭 - 링크
- [kube-state-metrics-v2] Dashboard → New → Import → 13332 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
- [Amazon EKS] **AWS CNI Metrics 16032 - 링크

위 항목에서 Dashboard 임폴트가 가능하다.

임폴트한 대시보드 화면
그럼 마지막으로 아까 배포한 Nginx 파드의 여러가지 정보를 모니터링해보자.
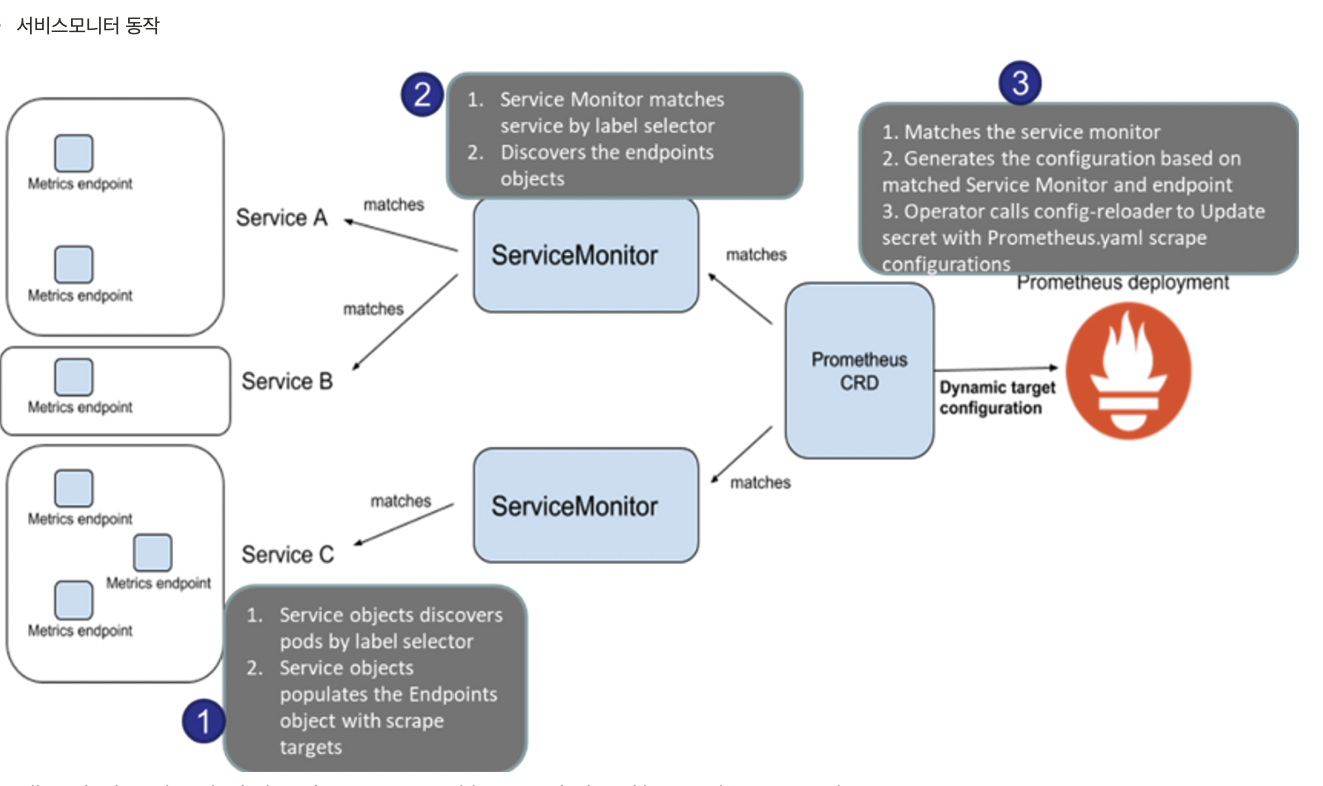
# 모니터링
watch -d kubectl get pod
# 파라미터 파일 생성 : 서비스 모니터 방식으로 nginx 모니터링 대상을 등록하고, export 는 9113 포트 사용, nginx 웹서버 노출은 AWS CLB 기본 사용
cat <<EOT > ~/nginx_metric-values.yaml
metrics:
enabled: true
service:
port: 9113
serviceMonitor:
enabled: true
namespace: monitoring
interval: 10s
EOT
# 배포
helm **upgrade** nginx bitnami/nginx **--reuse-values** -f nginx_metric-values.yaml
# 확인
kubectl get pod,svc,ep
kubectl get servicemonitor -n monitoring nginx
kubectl get servicemonitor -n monitoring nginx -o json | jq
# 메트릭 확인 >> 프로메테우스에서 Target 확인
NGINXIP=$(kubectl get pod -l app.kubernetes.io/instance=nginx -o jsonpath={.items[0].status.podIP})
curl -s <http://$NGINXIP:9113/metrics> # nginx_connections_active Y 값 확인해보기
curl -s <http://$NGINXIP:9113/metrics> | grep ^nginx_connections_active
# nginx 파드내에 컨테이너 갯수 확인
kubectl get pod -l app.kubernetes.io/instance=nginx
kubectl describe pod -l app.kubernetes.io/instance=nginx
# 접속 주소 확인 및 접속
echo -e "Nginx WebServer URL = <https://nginx.$MyDomain>"
curl -s <https://nginx.$MyDomain>
kubectl logs deploy/nginx -f
# 반복 접속
while true; do curl -s <https://nginx.$MyDomain> -I | head -n 1; date; sleep 1; done
추가 참고.
kubecost - k8s 리소스별 비용 현황 가시화 도구

#
cat < cost-values.yaml
global:
grafana:
enabled: true
proxy: false
priority:
enabled: false
networkPolicy:
enabled: false
podSecurityPolicy:
enabled: false
persistentVolume:
storageClass: "gp3"
prometheus:
kube-state-metrics:
disabled: false
nodeExporter:
enabled: true
reporting:
productAnalytics: true
EOT
**# kubecost chart 에 프로메테우스가 포함되어 있으니, 기존 프로메테우스-스택은 삭제하자 : node-export 포트 충돌 발생**
**helm uninstall -n monitoring kube-prometheus-stack**
# 배포
kubectl create ns kubecost
helm install kubecost oci://public.ecr.aws/kubecost/cost-analyzer --version **1.103.2** --namespace kubecost -f cost-values.yaml
# 배포 확인
kubectl get-all -n kubecost
kubectl get all -n kubecost
# kubecost-cost-analyzer 파드 IP변수 지정 및 접속 확인
CAIP=$(kubectl get pod -n kubecost -l app=cost-analyzer -o jsonpath={.items[0].status.podIP})
curl -s $CAIP:9090
# 외부에서 bastion EC2 접속하여 특정 파드 접속 방법 : socat(SOcket CAT) 활용 - [링크](<https://www.redhat.com/sysadmin/getting-started-socat>)
yum -y install socat
socat TCP-LISTEN:80,fork TCP:$CAIP:9090
웹 브라우저에서 bastion EC2 IP로 접속
설치 방법
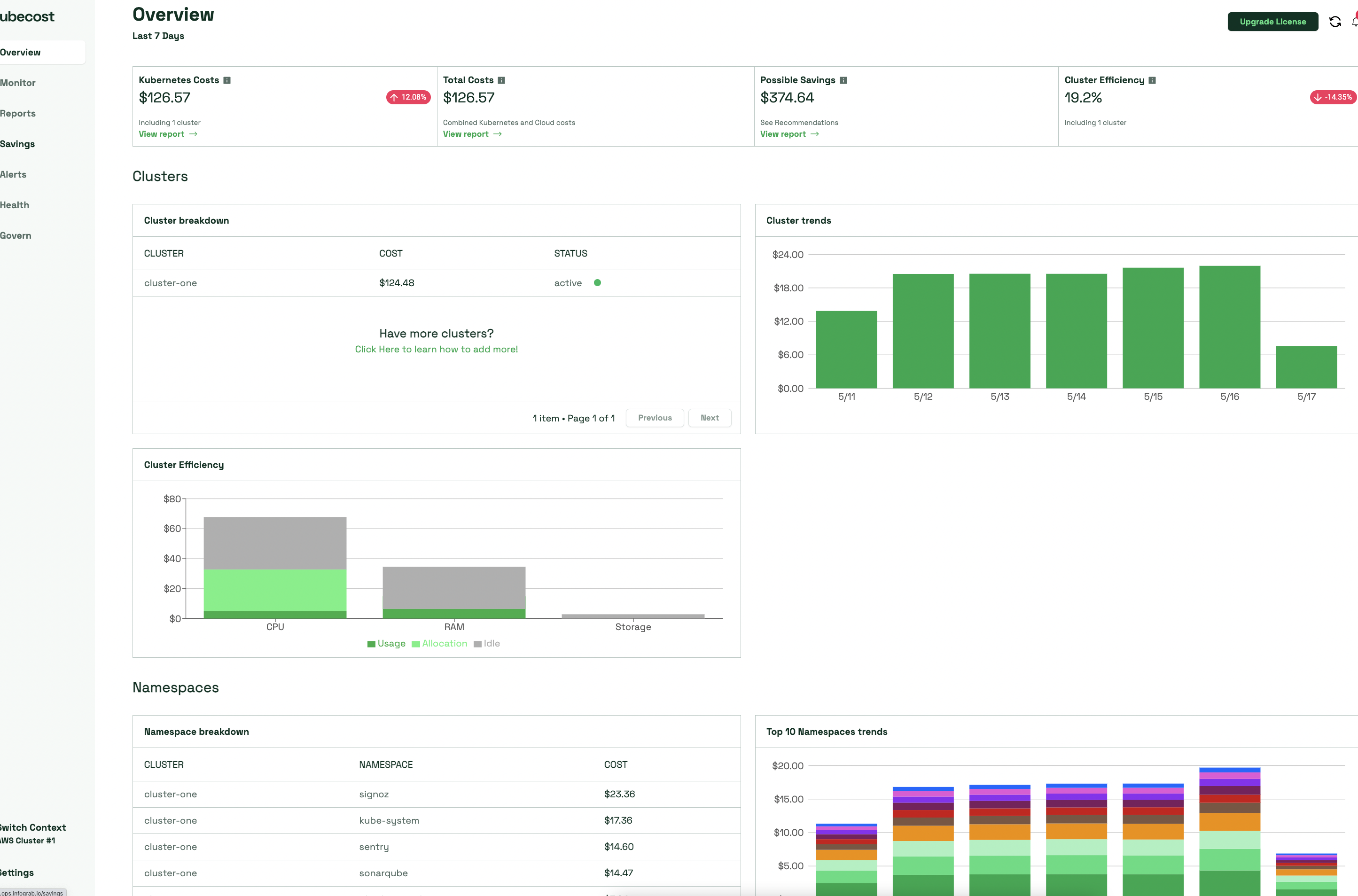

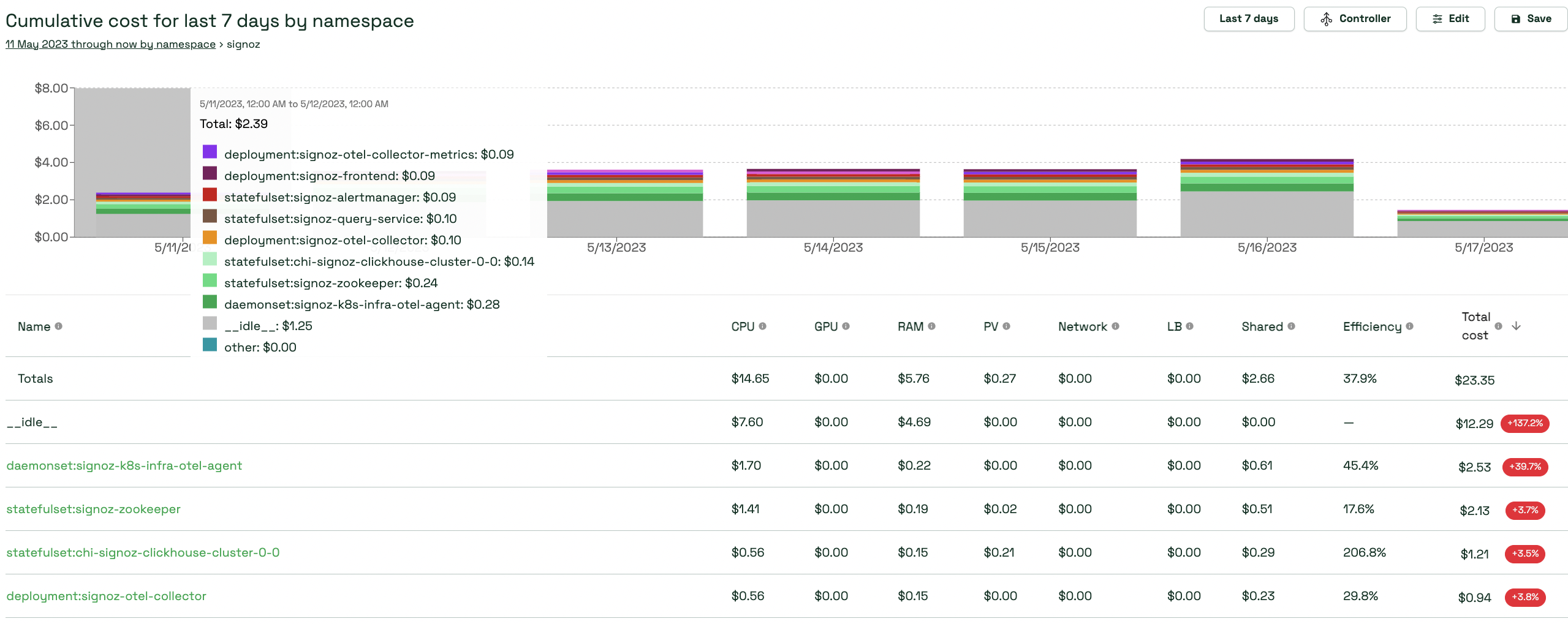
위와같이 kubecost를 통해 리소스별 비용 확인이 가능하다.
오픈텔레메트리
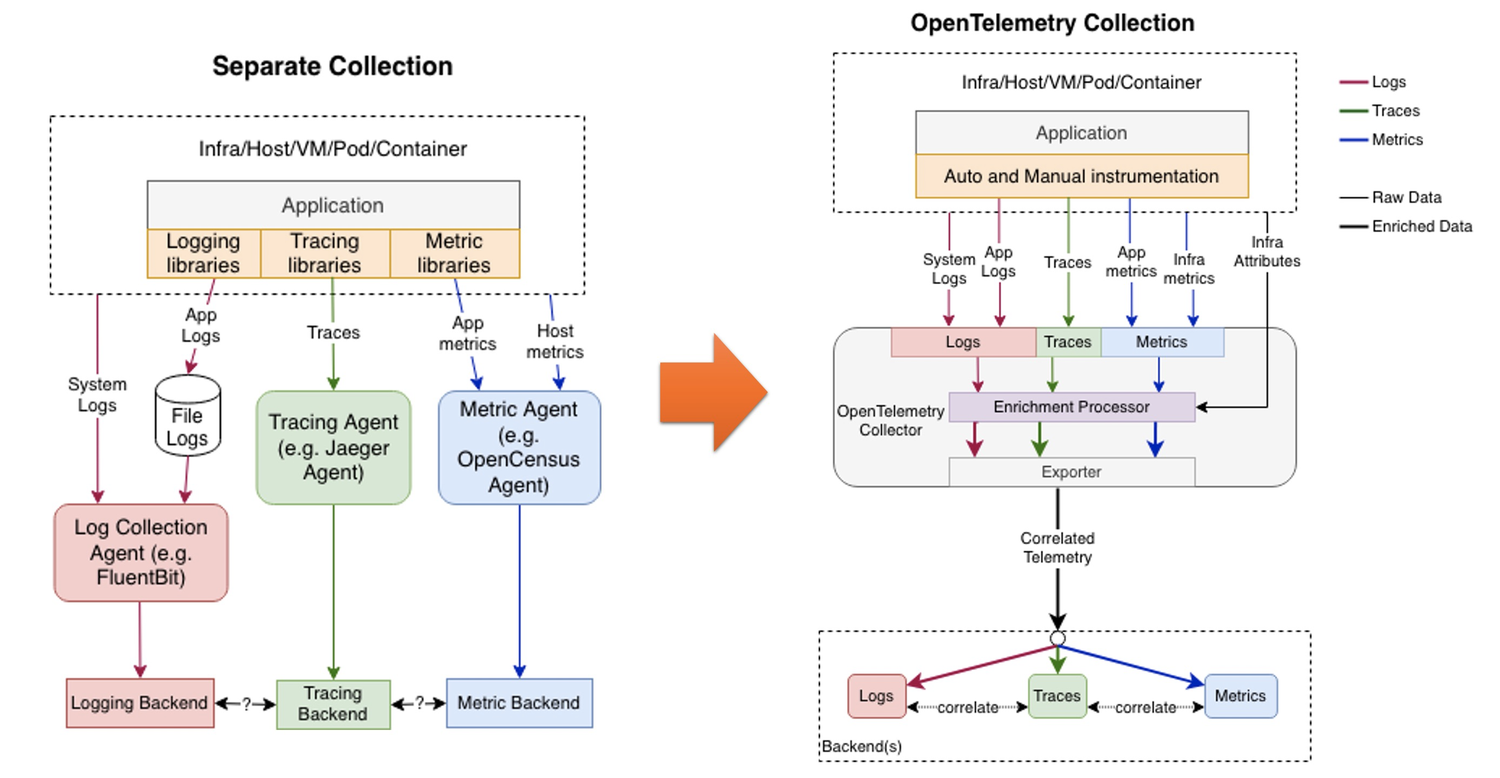
https://opentelemetry.io/docs/what-is-opentelemetry/ 참고